


作业①: 爬取大学排名信息
1. 作业代码及运行结果
import requests
from bs4 import BeautifulSoup
# 函数:请求网页数据,处理可能的异常
def get_html(url):
try:
response = requests.get(url, timeout=30)
response.raise_for_status()
response.encoding = 'utf-8'
return response.text
except requests.RequestException as e:
print(f"请求错误: {e}")
return None
# 函数:解析并提取大学排名信息
def parse_ranking_table(html):
soup = BeautifulSoup(html, 'html.parser')
# 查找包含排名信息的表格
ranking_table = soup.find('table', class_='rk-table')
if not ranking_table:
print("未找到排名表格")
return
rows = ranking_table.find_all('tr')
# 打印表头信息
header = [th.get_text(strip=True) for th in rows[0].find_all('th')]
print(" | ".join(header))
# 遍历每一行,提取大学排名信息
for row in rows[1:]:
columns = [td.get_text(strip=True) for td in row.find_all('td')]
if columns:
print(" | ".join(columns))
# 主程序
if __name__ == '__main__':
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
# 获取网页HTML
html_content = get_html(url)
# 如果获取到HTML,解析并打印排名信息
if html_content:
parse_ranking_table(html_content)
运行结果:
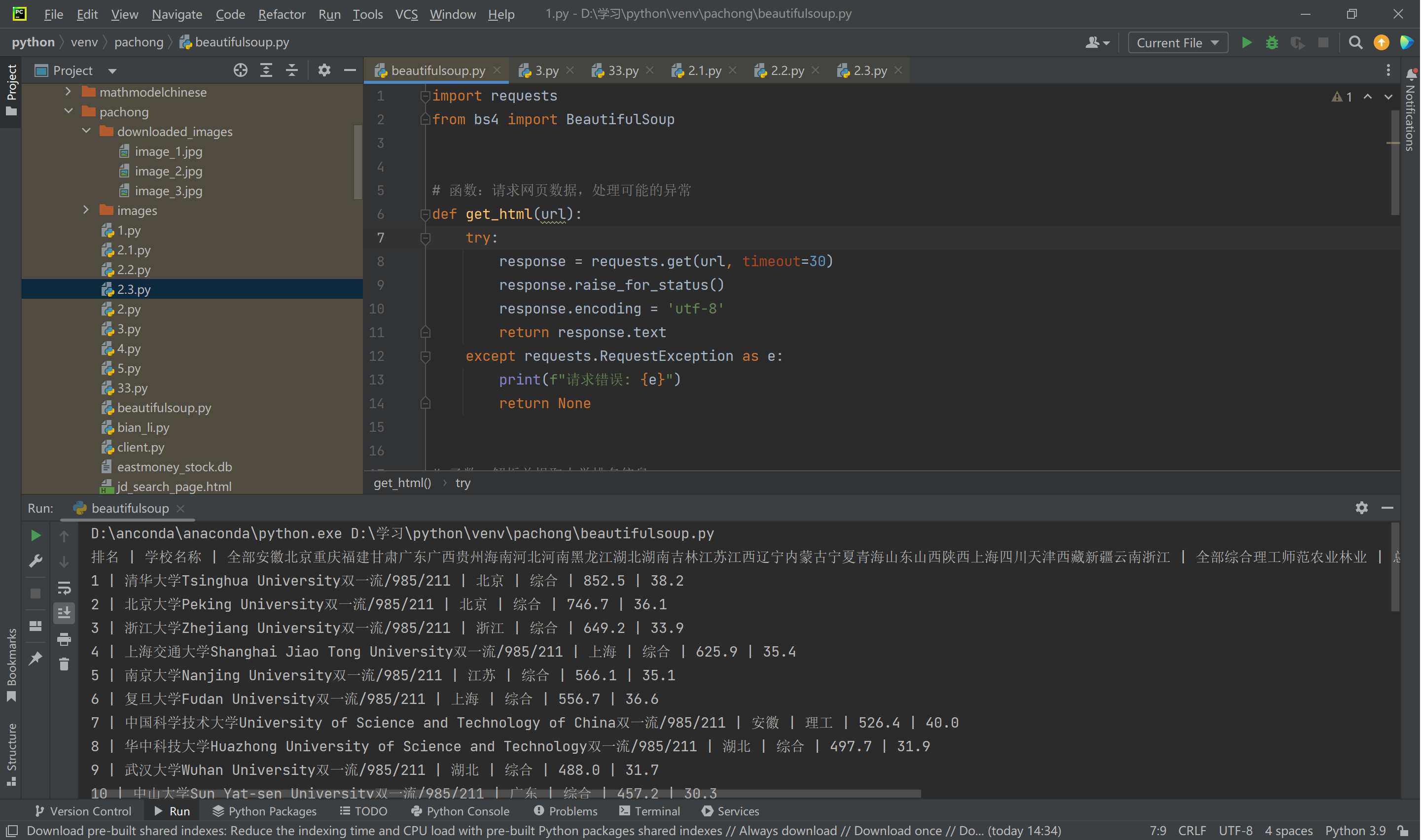
2. 作业心得
在这一作业中,我使用了 requests 和 BeautifulSoup 库来爬取并解析网页信息,具体流程如下:
- 通过
requests.get()方法获取网页内容,并将其解码为可解析的 HTML 。 - 利用
BeautifulSoup库解析 HTML 页面,通过find_all()方法遍历所需的标签提取表格数据。 - 最后使用自定义格式打印出大学排名、名称、省市、类型和总分。
心得:
- 使用
BeautifulSoup时,准确选择标签至关重要,特别是网页结构较为复杂时,可能需要不断调整选择器。 - 在调试过程中,遇到过网页加载不全的情况,需要重新设计爬取逻辑。
- 学习到爬虫抓取静态网页的基本流程和方法。
作业②: 爬取商品信息
1. 作业代码及运行结果
import requests
from bs4 import BeautifulSoup
# 函数:根据URL和headers获取网页内容
def get_page_content(url, headers):
try:
response = requests.get(url, headers=headers, timeout=30)
response.raise_for_status() # 如果返回状态码不是200,引发异常
response.encoding = response.apparent_encoding
return response.text
except requests.RequestException as e:
print(f"请求错误: {e}")
return None
# 函数:解析商品名称和价格
def parse_product_info(content):
if not content:
return []
soup = BeautifulSoup(content, 'lxml')
products = []
# 查找所有商品条目
items = soup.find_all('li')
for item in items:
try:
# 提取商品名称
name = item.find('a', attrs={'dd_name': '单品图片'})['title'].strip() if item.find('a', attrs={'dd_name': '单品图片'}) else None
# 提取商品价格
price = item.find('span', class_='price_n').text.strip() if item.find('span', class_='price_n') else None
if name and price:
products.append((name, price)) # 将商品名称和价格添加到列表中
except AttributeError:
continue # 忽略缺失名称或价格的条目
return products
# 函数:输出商品信息
def print_product_info(products):
print('序号\t\t价格\t\t商品名称')
for idx, (name, price) in enumerate(products, start=1):
print(f"{idx}\t\t{price}\t\t{name}")
# 主程序
if __name__ == '__main__':
url = 'https://search.dangdang.com/?key=%CA%E9%B0%FC&act=input'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0'
}
# 获取网页内容
page_content = get_page_content(url, headers)
# 解析商品信息
product_list = parse_product_info(page_content)
# 输出商品信息
print_product_info(product_list)
运行结果:
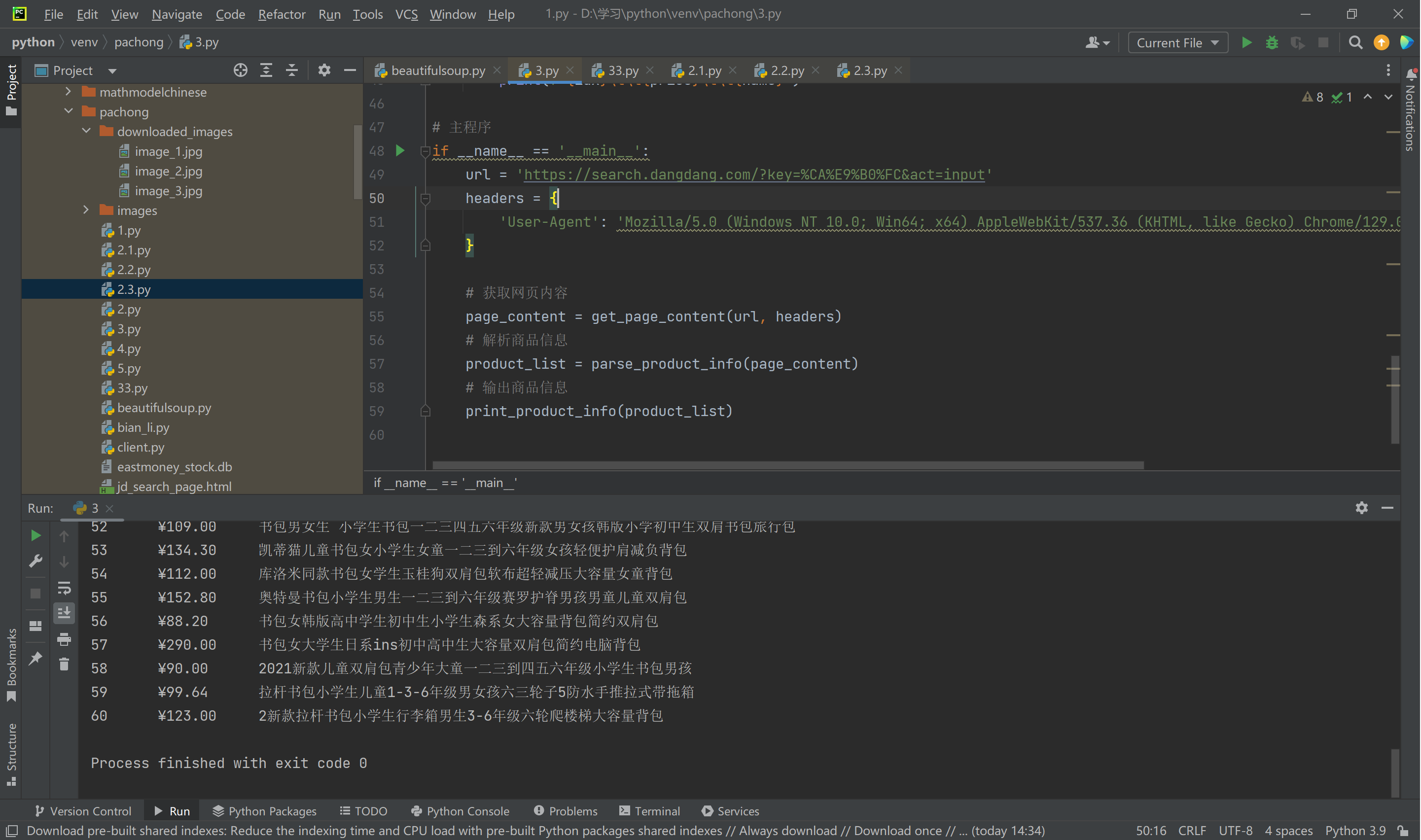
2. 作业心得
本作业要求设计一个定向爬虫,爬取商品信息,整个实现过程如下:
- 使用
requests库发起请求,获取网页HTML数据。 - 通过
re正则表达式来定位符合条件的商品信息,并结合BeautifulSoup来提取每个商品的价格和名称。 - 通过格式化输出的方式展示爬取到的商品名称与价格。
心得:
- 爬取电商平台数据时,了解网页的请求方式和动态加载机制非常重要。
- 使用正则表达式进行数据提取时需要非常小心,确保精确匹配相关字段,避免误抓无关信息。
- 针对不同电商平台,解析规则可能需要根据页面结构进行定制。
作业③: 爬取网页图片
1. 作业代码及运行结果
import os
import requests
from bs4 import BeautifulSoup
import re
from urllib.parse import urljoin
# 创建保存图片的文件夹
def create_save_dir(save_dir):
if not os.path.exists(save_dir):
os.makedirs(save_dir)
return save_dir
# 下载图片
def download_image(img_url, image_count, save_dir, headers, base_url):
# 如果图片URL没有协议头(例如 "//" 或以 "/" 开头的相对路径),补全为完整的URL
if img_url.startswith('//'):
img_url = 'https:' + img_url
elif img_url.startswith('/'):
img_url = urljoin(base_url, img_url) # 使用 urljoin 来补全相对路径
try:
# 下载图片数据
img_data = requests.get(img_url, headers=headers, timeout=10).content
# 构建文件保存路径
img_filename = os.path.join(save_dir, f'image_{image_count}.jpg')
# 将图片数据写入文件
with open(img_filename, 'wb') as f:
f.write(img_data)
print(f'已下载: {img_filename}')
except Exception as e:
print(f'下载失败: {e}')
# 爬取网页并下载JPEG和JPG图片
def crawl_images_from_page(url, save_dir):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0'
}
# 发送请求获取网页内容
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status() # 检查是否请求成功
except requests.RequestException as e:
print(f"请求错误: {e}")
return
html_content = response.text
# 使用 BeautifulSoup 解析 HTML
soup = BeautifulSoup(html_content, 'html.parser')
# 查找所有 img 标签中的图片链接
img_tags = soup.find_all('img')
# 图片计数
image_count = 0
# 遍历所有 img 标签,提取图片链接
for img_tag in img_tags:
img_url = img_tag.get('src')
if img_url and re.search(r'\.(jpg|jpeg)$', img_url, re.IGNORECASE):
image_count += 1
download_image(img_url, image_count, save_dir, headers, url)
if image_count == 0:
print('未找到任何JPEG或JPG格式的图片。')
# 主函数
if __name__ == '__main__':
# 爬取的目标网页
url = 'https://news.fzu.edu.cn/yxfd.htm' # 或者你可以替换为你自选的网页
# 保存图片的文件夹
save_dir = create_save_dir('downloaded_images')
# 开始爬取并下载图片
crawl_images_from_page(url, save_dir)
运行结果:

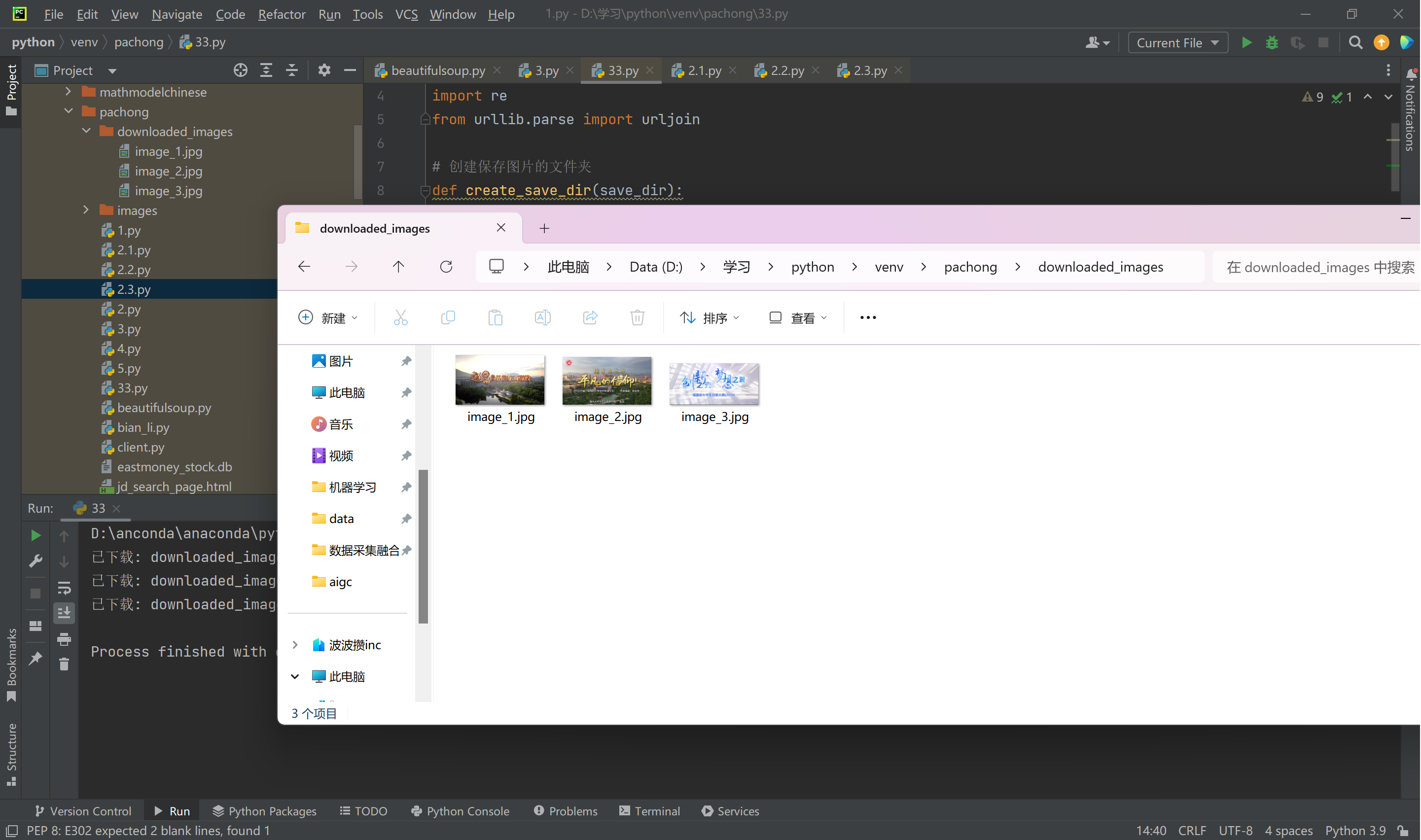
2. 作业心得
在这次作业中,我学习到如何抓取网页中的图片资源并保存到本地,主要流程如下:
- 使用
requests获取网页 HTML 内容。 - 通过
BeautifulSoup提取所有<img>标签,并使用urljoin()处理相对路径图片链接。 - 利用
requests.get()下载图片内容,并保存到指定文件夹中。
心得:
- 使用
urljoin()方法可以确保图片的相对路径与网站的根路径正确拼接,从而能够正确下载图片。 - 保存图片时,确保文件夹路径正确并考虑图片名称的处理,避免因重复图片名导致覆盖问题。
- 图片下载过程需要考虑网络不稳定的情况,必要时可以加上异常处理逻辑。
四、总结
通过这三次作业,我对网络爬虫的原理有了更加深入的理解,特别是如何利用 requests 和 BeautifulSoup 库进行静态网页的抓取和解析。每个作业的实现都增强了我对爬虫技术的信心,为未来进行更复杂的数据采集任务打下了坚实的基础。
 posted on
posted on
