使用FileReader在浏览器读取预览文件(image和txt)
如标题,之前在某个地方看到因为有Blob的存在,理论上可以在浏览器上查看所有格式的文件.自己想着试试现在暂时只能够查看图片和预览txt文件.其他的比如doc,docx格式的文件查看的时候是乱码
如图:可以多选照片查看,可以查看txt文件
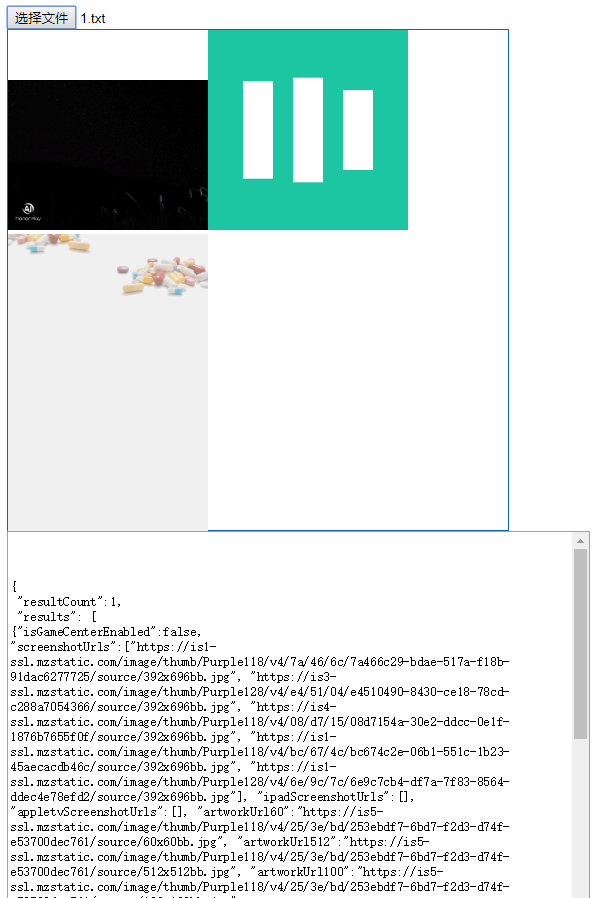
不说多了,主要是利用filereader读取blob转成base64或者直接读取文本然后展示.代码如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
<input type="file" id="file1" multiple="multiple">
<div id="showArea" style="width: 500px;height: 500px;border: #0066CC 1px solid;">
</div>
<textarea rows="30" cols="80" id="textarea">
</textarea>
</body>
<script type="text/javascript">
/* ArrayBuffer, Blob对象(二进制文件) 和 字符串, base64(ASCII码) 之间的相互转换/单向转换, */
// 文件读取器 FileReader
// FileReader 只接受 File 或 Blob 类型的数据(事实上 File 也 Blob 的一种)
// 1.Blob类型
const filereader = new FileReader();
const blob = new Blob(['hello file-reader'], { type: 'text/plain'});
filereader.onload = e => {
console.log(e.target.result); // 输出 data:text/plain;base64,aGVsbG8gZmlsZS1yZWFkZXI=
var txt = new File();
}
// filereader.readAsDataURL(blob);
// 2. File类型
let file1DOM = document.querySelector('#file1');
file1DOM.onchange = function(){
console.log(this.files)
let file1 = this.value
var fileReaders = []
for(var i = 0;i<this.files.length;i++){
console.log(this.files[i].type)
fileReaders[i] = new FileReader();
var fileType = this.files[i].type.split('/')[0]
if(fileType == 'image'){
fileReaders[i].readAsDataURL(this.files[i])
fileReaders[i].onload = function(e) {
var image = new Image();
image.setAttribute('src',e.target.result)
image.setAttribute('width',200)
image.onload = function() {
document.querySelector('#showArea').appendChild(this)
}
}
} else if(fileType == 'text'){
fileReaders[i].readAsText(this.files[i])
fileReaders[i].onload = function(e){
document.querySelector('#textarea').value = e.target.result
}
}
}
}
</script>
</html>
试过利用filereader的readastext()读取docx,但是读取出来格式是application/vnd.openxmlformats-officedocument.wordprocessingml.document,读取出来也是乱码.大概是编码问题.试了试别的编码方式GB2312,GBK没有用,都是乱码.先放放,有空了再看看

 浙公网安备 33010602011771号
浙公网安备 33010602011771号