
NUC_CTF-writeup
逆向
jungle
PEID 查壳,没有壳,32位。IDA打开大致看了看,C++写的,静态太难了,直接OD动态调试,
检测长度 大于0x1E
格式 flag{xx-xxxx-xxxx-xxxx}
第一个是一个md5解密,可以直接搜到md5字符串,猜测应该是字符串拼接,还能搜到两个base64编码,解密后拼接,第二个检测,不知道怎么弄,4个字符爆破呗。。。
upx
题目upx,那肯定是upx壳啊,手脱,用工具都可以。这道题没什么难度,最难得应该就是脱壳了吧。
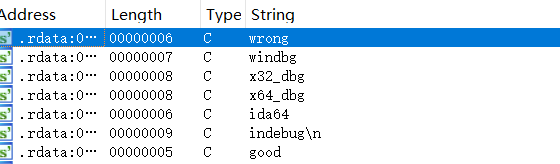
查找关键字,交叉引用。
来到主函数,使用R键将数字转换为字符,可以找出三个字符串,然后异或求解。

s1 = '6ljh,!;:+&p%i*a=Sc4#pt*%'
s2 = '1zsw438oOFu5i4nd0f_cH2z1'
s3 = 'azxxcqabRW5qb3llZ2FtZwgi'
flag = ''
for i in range(len(s1)):
flag += chr(ord(s1[i]) ^ ord(s2[i]) ^ ord(s3[i]))
print(flag)
跑脚本就完事了。
RE2
一个游戏,64位,ELF文件,IDA载入分析,发现流程很简单。
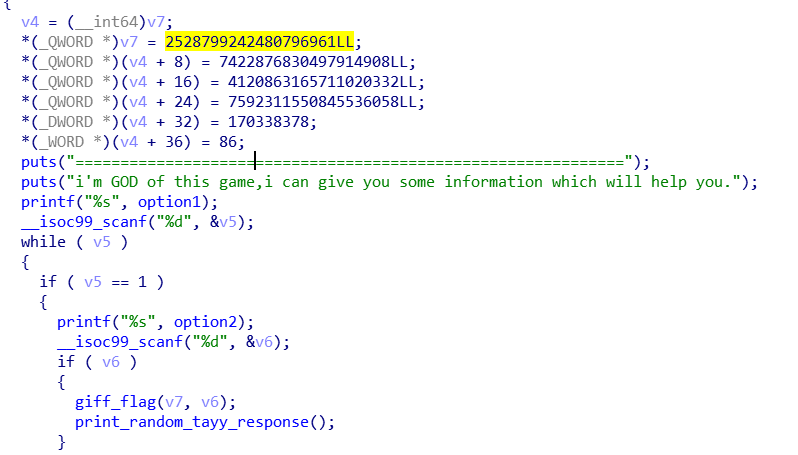
一大串字符串,应该是用来进行解密的,然后有个‘flag’关键字符串的函数,进去看看。
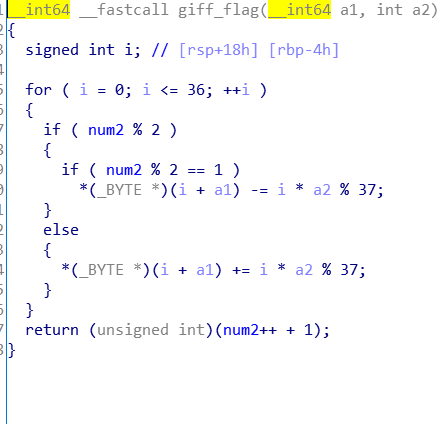
动态调试。num是从0开始的,每次选择第一个选项的时候就会+1.没什么其他难点了,动态调试有反调试,很简单,直接jmp就行。因为只能输入7次,所以得爆破九百万个数,牛批。
上爆破脚本:
for w in range(1111111, 9999999):
flag = ['0x21', '0x45', '0x58', '0x4c', '0x83', '0x19', '0x18', '0x23', '0x1c', '0x40', '0x4e', '0x35', '0x26',
'0x5b',
'0x3', '0x67', '0x2c', '0x71', '0x32', '0x48', '0x37', '0x3f', '0x30', '0x39', '0x3a', '0x47', '0x3e',
'0x34',
'0x21', '0x4f', '0x5d', '0x69', '0x4a', '0x28', '0x27', '0xa', '0x56']
s1 = str(w)
n = 0
result = ''
for j in range(7):
r = 0
if n % 2 == 1:
for i in range(37):
flag[i] = hex(int(flag[i], 16) - ((i * int(s1[j])) % 37))
else:
for i in range(37):
flag[i] = hex(int(flag[i], 16) + ((i * int(s1[j])) % 37))
for z in range(len(flag)):
if 33 > int(flag[z], 16) or int(flag[z], 16) > 126:
r = 1
if r == 0:
for p in flag:
s2 = chr(int(p, 16))
result += s2
print(result)
n += 1
crypto
base
没提示还不知道咋做。base全家桶,直接上py2脚本:
import base92, base58, base64
a = '4%_,,I,*xt];Y@(6Hk]jrF.2:gR_Ss&-=S<Eil^TnIW%U+(XJXk_Fr.A4!Y)o\'[AIT%:U3\Z55IUmVJPIP<%&Rb2Pujy+rE)<,SLEg*os4]9lQXa;-w#SWbC5MiY=;Da5KuI&V[S:auU?Ub&4gT$lY6=PRhxBng,<,H-A@^v$:QHTg1;@au)]]B'
b = base92.decode(a)
c = base58.b58decode(b)
d = base64.b64decode(c)
e = base64.b32decode(d)
f = base64.b16decode(e)
print f
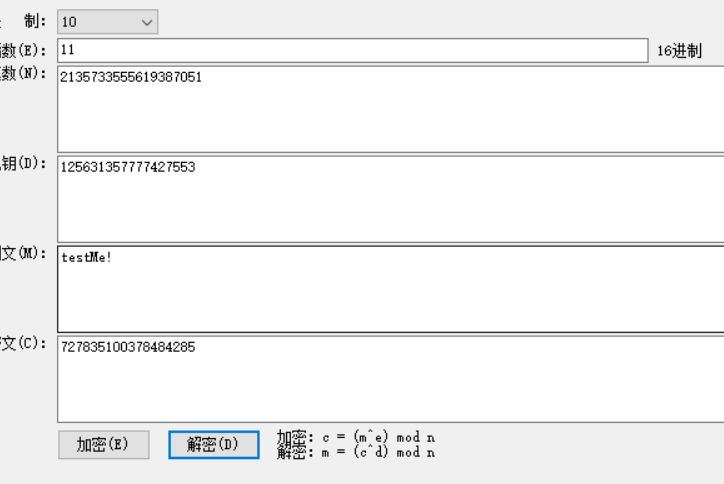
easy_rsa
所有信息都很明显,根据p,q,e算出D,然后解密密文。
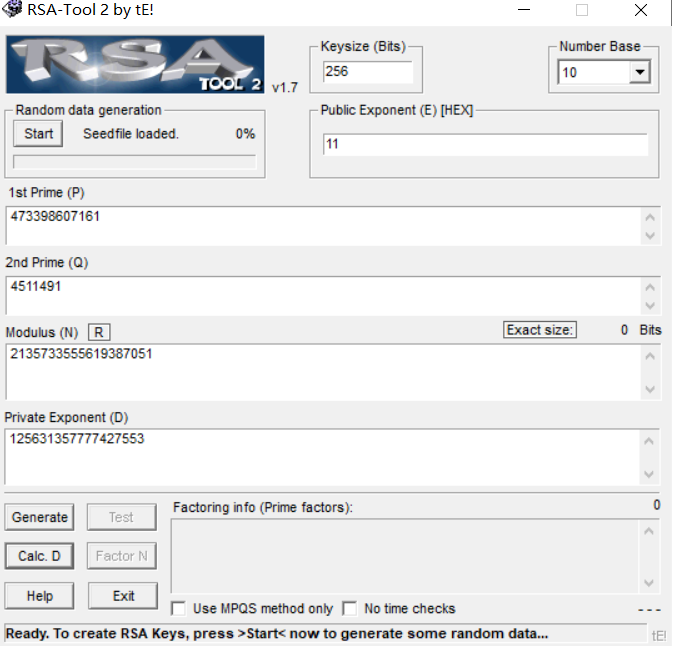
simple_crypto
提示quip,有个解密网站的域名好像是这个名字,词频分析吧,试试,

那肯定是cryptoooo啊。
超级凯撒
很脑洞,我要是上课听课了,肯定也做不出来,哈哈。
ascii码 每次相差 0x7e 递减2, 说不清楚, 看脚本吧,简单易懂。
s = 'e7f09ae1e994d9dfddd08b88baccc780c4c8bbbf76bdc58a6eb2b6a9adbf7875776f6e6968986a62605f5e605c58835983534b4e7c477642733f6c386b367f'
s1 = []
for i in range(0, len(s), 2):
a = '0x' + s[i:i+2]
s1.append(a)
s2 = ''
d = 0x7e
for i in range(len(s1)):
c = chr(int(s1[i], 16) - d)
s2 += c
d -= 2
print(s2)
it is good! The flag is: flag{6593412d82234864a9e716f3d2e3b0e2}
web
pastejacking
右键粘贴复制。JS代码好像是不让复制什么的,不是很懂,好像快捷键不行吧,我审计JS代码快捷键粘贴也出错了,手残没复制对?
ez_cmd
一堆过滤,慢慢过waf吧,最后是%0a截断,然后 cd ../../../ 忘了在哪个目录了,最后 cat ../../../flag.txt!
web很渣,我不知道我学了一年web,却还是这么渣。。。。
MISC
wireshark
流量分析,在一堆ICMP报文中有很多可疑的ttl 像是ascii码,提取出来是,strong+passwordstrong+password
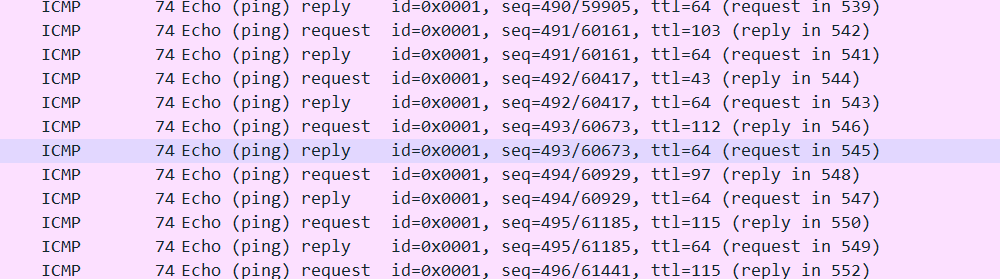
以为是flag,交上去不对,又翻了翻HTTP协议,发现有个压缩包,把文件dump出来,需要解压密码,就是上边的字符串。

解压出来一张图片,这么多关卡,啊,杂项呗,慢慢搞,最后发现是lsb隐写。
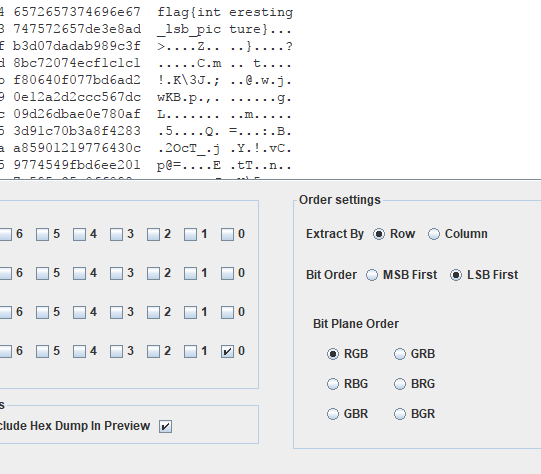
找吧
很多{} 猜测词频分析 ,一波现成脚本打上去。
# -*- coding:utf-8 -*-
import operator
str = '''
flM{Sg_i_igl1S_ll__SfM_FF_1ilfM{Sa11gagc1lSSMgfnafg_fMa1n5iaF_c1lSFiSaf_1f{S_l_FalS5_faSl_fgl5M1_{ll!{i5c}if1__fg5{__M{ngU{1l1gff1f1iS__Mf5iFMlciSgaU{glgUF5M_1aa_f_i5{nflllla1S1FS!cSg{fUfFcS1{{ag1lU51acfUSffMcMSgfSfalFg_g_gfgfiSfla1i{{{n{_lg_}{ggi{gglg{{flnliF{M5faF1ig_agal{_{{aMMilfUSa{a5ggiiigfSSg{M_Mng{a}fcMf1_Fl{cM{1fiflMSSM{_l!Scf5FFcn{g{SFnMlf{l__aScMl{{c_lS1Sic1!l5ga1_gfggllcllccaagMU1iala55FSfia5lScMMFiMaFff{{g{fcicM!l_{iffcg{UlcMa{{5f5Mc{McfagcM_Ma1Slcf{cSg_SflM5U11_5i_fcc{FagglaMUfS1g_{lSc5f_lag5Sg_ccclca___ala1g1aSMfa_fcaFnSSi{a1a{gUif_FgaS{lacSgfga{F1fgScf1_M__{1ag_5MMSiga11g_aMl5fM15a_gla5f1_UllgcSc{Sagac{accS_i{Mf{Sgccg_ici{fgcl_gaMlffS{{i{nnfaM}aallSSg1ilUif{Mi1SMiMl1aaMUl{alaglM!1lgngScMac1fa1acafS1fgfM__S11_SM{f}la_cM_g{fniifgc1M{_lM!M5}g5_l1USg{cgl{SaccigSU1fMgl5lcaiggMFfcaca1l{Ugf_lalg1_g!{iaala_M5l1Mc11afcgfgl5f1g_c{llaUMf1lM1aF{af1Sl5lf5l1l5a_cc_c_1ff}f_ff}MlU{afM_1fcla{{gM{_Sl_M_{gM_{g5gaMaFU{{!S1ala1lfl1lifl_Mlf5F{l_g{li__aM_gfSU{lM_agM{giff{ii_{ff_naaaif1gf_ag__lnFacgiSlSac_Ma5M{fg{{fac{gllfaa{Mi5MnMff{{gc!fn_iU{ll5i_Saa5M{Mi}{g{Ffl{Ffac!a{afffgl!_gMalF_c{lac_MFMg5acMFcla5cMlU5aSff{l_UFf_Ug1!g1F_c{{aMMg{SlgUa1ca1ff5_c1g5{fligg11_lla_fcf1{Mla1MnglM{5lSl1g__Sll_cUc5MSa{_fiMiiS1c{M1g_SSUifi1!Saa{_glS1aaal{llF1cFgig_Sf{acf{Uf1c1fa!gfFM_aS51lgaMa1aa_gfif_ia{M_a_M1fMSaSSfMSl{1gFcl151l_lFfMilffgf1gSSgcaf_SfMgaf{}ilaUMM_MU5ff551i5SnFgc15nSMa1M{{_fSlMg{{5fcS1g5fSgMMUi{_ig5falf1nfgFaUMlff!g__la_F_c1{i1!{lc{i{1iglM_fUgl___a5fnMaFf{_lfll_igf1lcalniMag_5nFS1MMaiM1ll5SlMiaf_5l{af__MMgac_Mf__fUa1fc{1{_55SF!llfgU1l1U_Mal_l{alglSglcnlfSfaacgSSgSc_Maa{ffg51MaSfca1U_{gfS1ff5l{{f1Ml_gSgc_n5iS1Sg_l__1nnM1lM15MillfaMff1!nl1fFSM5Fflf{acagl{Sf{ggfSi1f!FSagf{{lFf5la5{ff__lM{M_fUlSgi
'''
payloads = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!0}{123456789_\n'
#payloads = payloads.upper()
# print payloads
dists = {}
for x in payloads:
dists[x] = 0
# print x,dists[x]
for s in str:
dists[s] += 1
ans = ''
res = sorted(dists.iteritems(), key=operator.itemgetter(1), reverse=True)
for r in res:
ans += r[0]
print r
print ans

跑出来是这个,哦,不对,看着也出来了,应该脚本的问题吧,自己慢慢改对了,凭经验, 应该是misc_is_fun
文体两开花
提示 \u 和中国话, 那就先 unicode试试,先分离,
s = '5e1d4f9d5927662f545076e785a94f84681759629053602f80fd573063d0602f6240654553574f848f3869c35922545066f066f04e09670b8c468af380367f3d91af601b8af35e1d8f384f845492602f963f601b68b566f076a44ea67f3d53c368b5537354c66f2b596290535937624068b56f2b5450522951a57a76602f6ec5771f54504e16545096407f3d67095c3c54c6803676e781f34f5b602f5a4676a4608967094f8459227f8569c350e77adf96c68af3795e59625927545059ea6d85540968b5745f7b49601b5373963f5a468b395a46720d96408c467adf608954c685dd5ea6602f5f9768177f3d300254c64e0954c68ae6820d9060803654c65937822c820d57304f9d77e551a59060601676a46c9968b59ebc76a47adf4e16602f5fc383e9964054c676e75bc65beb59624ee54ff1985b54c6591c602f822c77e5602f6ce24ff17919964096e296e24e00602f592283e9602f771f5b558af38a368af38af882e6602f59ea4f8484996089660e8dcb9ebc5f4c66f0545085dd84994ff15fc37f3d80366ce24ea676a467095962985b8af382e554c6720d4ff15beb596260895962662f4f8476e154c685dd76a47b4982e5545090606bbf7f70771f905369c35450795e68b56c995beb5357771f596290fd6578745f54c64ea67f3d9ebc68b55a4685d08b394ff180057f3d6b7b9060820d5e1d802868b5535796e2559d76e74ed6573050e768b5559d68b54e1653574f3d4ed659624e165bc6602f860753737f704e00670b54c68b39'
f = ''
for i in range(0, len(s), 4):
f += "\\u" + s[i:i + 4]
print(f.encode('GBK').decode('GBK'))
然后解密: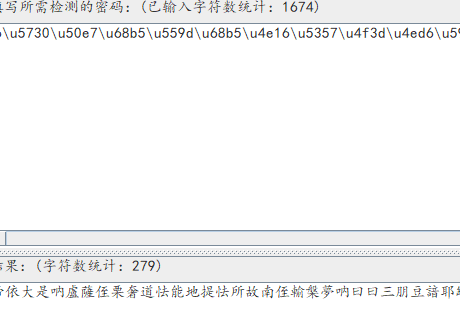
中国话, 与佛论禅吧,试试。。。

黑白
gif动图,只有黑的和白的,肯定是01二进制转ascii码啊,直接python脚本分离,然后去像素转换0和1
from PIL import Image
from PIL import ImageSequence
frames = []
img = Image.open('./hei.gif')
for frame in ImageSequence.Iterator(img):
f = frame.copy().convert("RGB")
r1, g1, b1 = f.getpixel((111,52))
if r1 == 0 and g1 == 0 and b1 == 0:
print('0',end='')
else:
print('1',end='')
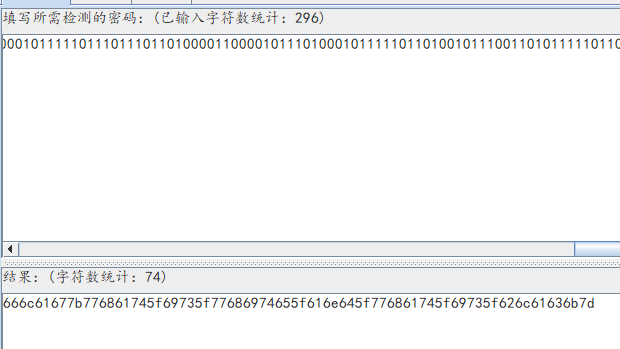
人生
分不高,一个png,难度应该不大,最简单的来吧,改高度试试。

洋葱
洋葱,一层一层的剥开,哦。。。
foremost 分割, 找到一个 4 文件,不知道是个啥,后来有提示。pkt ,百度pkt怎么打开, 下载思科的软件,打开直接复制flag。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号