transformer
论文:Attention is All You Need:Attention Is All You Need
1. Transformer 整体结构
首先介绍 Transformer 的整体结构,下图是 Transformer 用于中英文翻译的整体结构:

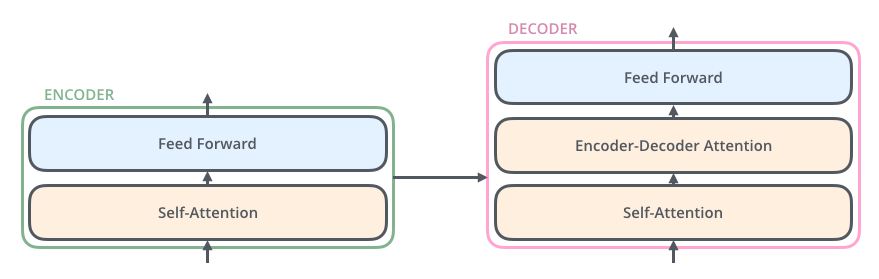
可以看到transformer由Encoder和Decoder两部分组成,Encoder和Decoder都包含6了block(数字6没有什么特殊的含义,可尝试其他数字),
Encoder在结构上都是相同的(但他们不共享权重)。每个Encoder被分成两个子层:
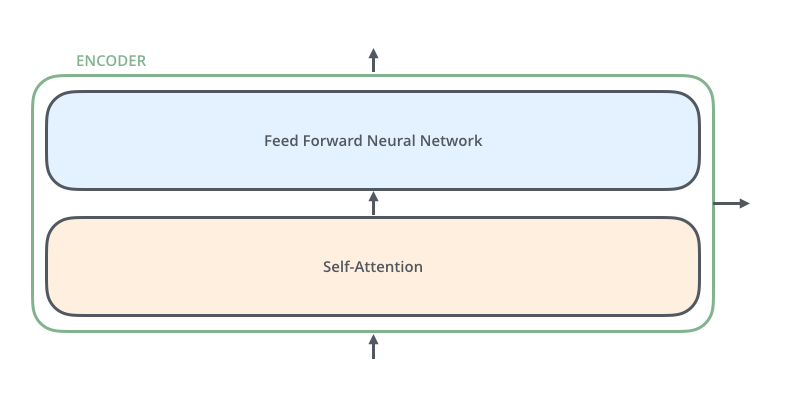
encoder的输入首先会流入自注意力层(self-Attention),该层在帮助Encoder编码一个特定词语时,会查看输入句子中的其他词语。
自注意力层(self-attention layer)是一种机制,它允许编码器在处理一个词语时,参考整个句子的其他词语,从而捕获句子中词语之间的相互关系和上下文信息,这对于理解和生成更准确的语言表述非常重要。
自注意力层的输出会被馈送到前馈神经网络,完全相同的前馈网络独立应用于每个位置。
Decoder也具有这两个层,但他们之间有一个注意力层,可以帮助解码器更关注输入句子的相关部分(类似于seq2seq模型中的注意力的作用)。
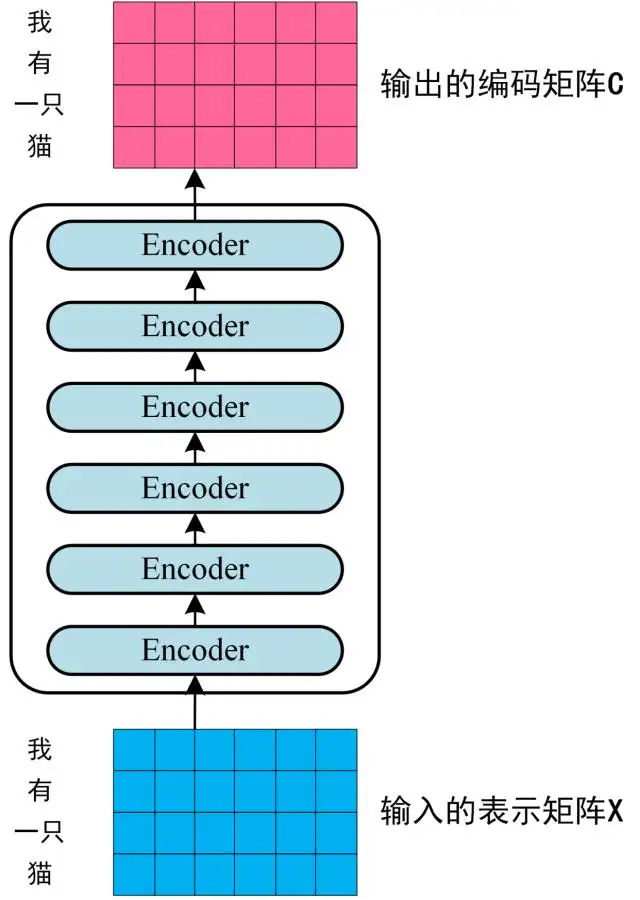
2. Transformer的处理流程
第一步: 获取输入句子的每一个单词的表示向量X,X由单词的Embedding(Embedding就是从原始数据提取出来的Feature)和单词位置的Embedding相加得到的。

第二步:将得到的单词表示向量矩阵(如上图所示,每一行都是一个单词的表示X)传入Encoder中,经过6个Encoder block后得到句子所有单词的编码矩阵信息C,如下图。单词向量矩阵用
表示,n是句子中单词个数,d是表示向量的维度(论文中n=512),每一个Encoder block输出的矩阵维度和输入是完全一致的。
第三步:将Encoder输出的编码信息矩阵 C传递到Decoder中,Decoder依次会根据当前翻译过的单词 1~i翻译下一个单词i+1,如下图所示。在使用的过程中,翻译到单词i+1的时候需要通过 Mask(掩盖)操作遮住i+1之后的单词。
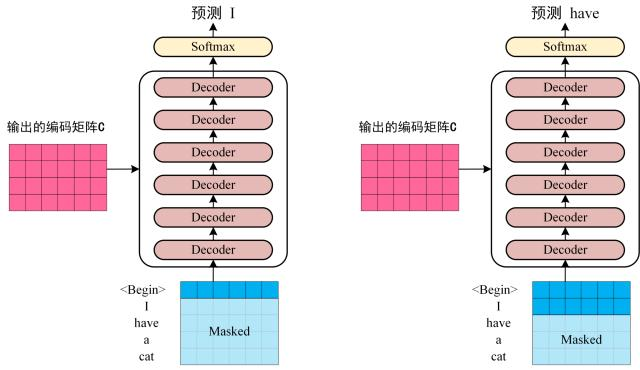
上图Decoder接收了Encoder的编码矩阵C,然后首先输入一个输入一个翻译开始符"<Begin>",预测第一个单词 "I",然后输入翻译开始符"<Begin>"和单词 "I",预测单词 ”have“,以此类推。
这就是Transformer使用时候的大致流程,接下来来看下各个部分的细节。
3. Transformer的输入
Transformer中的单词的输入表示x由 单词Embedding 和 位置 Embedding(position Encoding)相加所得。
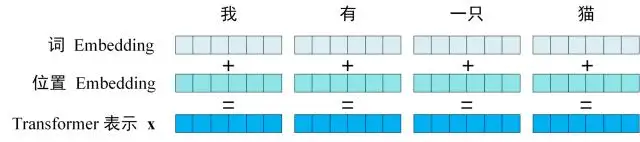
3.1 单词Embedding
单词Embedding由很多种方式可以获取,例如可以采用 Word2Vec、Glove等算法预训练得到,也可以在Transformer中训练得到。
3.2 位置Embedding
Transformer中除了单词的Embedding,还需要使用位置Embedding表示单词出现在句子中的位置。因为Transformer不采用RNN的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于NLP来说非常重要。 所以Transformer中使用位置Embedding保存单词在序列中的相对或绝对位置。
位置Embedding用 PE 表示,PE 的维度与单词Embedding是一样的。PE可以通过训练得到,也可以使用某种公式计算得到。在Transformer中采用了后者,计算公式如下:
其中,pos表示单词在句子中的位置,d表示PE的维度(与词Embedding一样),2i表示偶数的维度,2i+1表示奇数维度(即 )。使用这种公式计算PE有以下好处:
- 使PE能够适应比训练集里面所有句子更长的句子,假设训练集里面最长的句子是有20个单词,突然来了一个长度为21的句子,则使用公式计算可以计算出第21位的Embedding
- 可以让模型容易地计算出相对位置,对于固定长度的间隔k,PE(pos+k) 可以使用 PE(pos) 计算得到。因为,
将单词的词Embedding和位置Embedding相加,就可以得到单词的表示向量x,x就是Transformer的输入。
4. Self-Attention(自注意力机制)
Transformer Encoder和Decoder:

上图是论文中Transformer的内部结构图,左侧位Encoder block,右侧为Decoder block。红色圈中的部分为 Multi-Head Attention ,是由多个 Self-Attention 组成,可以看到Encoder block包含一个Multi-Head Attention(其中有一个用到Masked)。Multi-Head Attention上方还包括一个Add & Norm层,Add表示残差链接(Residual Connection)用于防止网络退化,Norm表示Layer Normalization,用于对每一层的激活值进行归一化。
因为 Self-Attention 是Transformer的重点,所以重点关注Multi-Head Attention以及 Self-Attention,首先详细了解下Self-Attention的内部逻辑。
4.1 Self-Attention结构

上图是Self-Attention 的结构, 在计算的时候需要用到矩阵 Q(查询),K(键值),V(值)。在实际中,Self-Attention接收的是输入(单词的表示向量x组成的矩阵X)或者上一个Encoder block的输出。而 Q,K,V 正是通过Self-Attention 的输入进行线性变换得到的。
4.2 Q,K,V的计算
Self-Attention的输入用矩阵X进行表示,则可以使用线性变阵矩阵WQ,WK,WV计算得到Q,K,V。计算如下图所示,注意X, Q, K, V的每一行都表示一个单词。

4.3 Self-Attention的输出
得到矩阵Q,K,V之后就可以计算出Self-Attention的输出了,计算的公式如下:
是Q,K矩阵的列数,即向量维度。
公式中计算矩阵Q和K每一行向量的内积,为防止内积过大,因此除以 的平方根。Q 乘以 K 的转置后,得到的矩阵行列数都为n,n为句子单词数,这个矩阵可以表示单词之间的attention强度。下图为Q 乘以 ,1 2 3 4表示的是句子中的单词。

得到 之后,使用Softmax计算每一个单词对于其他单词的attention系数,公式中的softmax是对矩阵的每一行进行softmax,即每一行的和都变为1.

得到softmax矩阵之后可以和v相乘,得到最终的输出Z。
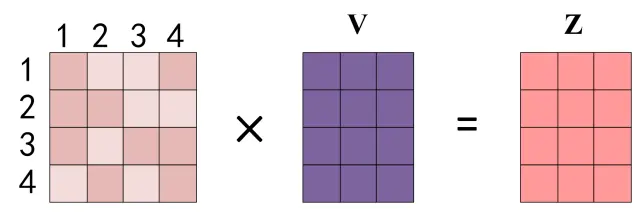
上图中softmax矩阵的第1行表示单词1与其他所有单词的attention系数,最终单词1的输出 等于所有单词i的值根据attention系数的比例加在一起得到,如下图所示:

PS:
- 注意力机制
自注意力机制的基本思想是,在处理序列数据时,每个元素都可以与序列中的其他元素建立关联,而不仅仅是依赖于相邻位置的元素。它通过计算元素之间的相对重要性来自适应地捕捉元素之间的长程依赖关系。
具体而言,对于序列中的每个元素,自注意力机制计算其与其他元素之间的相速度,并将这些相似度归一化为注意力权重。然后,通过将每个元素对应的注意力权重进行加权求和,可以得到自注意力机制的输出。

假设,有一个序列(或一句话):"你好机车",分别使用表示,如上所示
简单地说,表示"你",表示"好",表示"机",表示"车"
- Embedding操作
首先,对"你好机车"进行Embedding操作(可以使用Word2Vec等方法),得到行的向量,,如下图所示:

其中,表示Embedding的参数矩阵
- q,k操纵
Embedding操作后,将会作为注意力机制的input data
第一步,每个都会分别乘以三个矩阵,分别是,需要注意的是,矩阵在整个过程中是共享的,公式如下:
$$q^i = W^qa^i\\ k^i = W^ka^i \\ v^i = W^va^i\qquad\text{(5)}$$
其中,的含义一般的解释是 用来和其他单词进行匹配,更准确的说是用来计算当前单词或字与其他的单词或字之间的关联或关系;
的含义则是被用来和进行匹配,也可以理解为单词或字的关键信息。
如下图所示,若需要计算 和 之间的关系(或关联),则需要用 和 进行匹配计算,计算公式如下:
其中,表示和的矩阵维度,在self中,和的维度是一样的,这里除以的原因是防和的点乘结果较大。

经过和的点乘操作后,会得到 然后,就是对其进行Softmax操作,得到。

- 操作
的含义主要是表示当前单词或字的重要信息表示,也可以理解为单词的重要特征,例如,代表"你"这个字的重要信息。在操作中,会将操作后得到的 和 分别相乘,如下图所示,计算公式如下:

对应的,,以此类推:

代码:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# 定义自注意力模块
class SelfAttention(nn.Module):
def __init__(self, embed_dim):
super(SelfAttention, self).__init__()
self.query = nn.Linear(embed_dim, embed_dim)
self.key = nn.Linear(embed_dim, embed_dim)
self.value = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
q = self.query(x)
k = self.key(x)
v = self.value(x)
attn_weights = torch.matmul(q, k.transpose(1, 2))
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
attended_values = torch.matmul(attn_weights, v)
return attended_values
# 定义自注意力分类器模型
class SelfAttentionClassifier(nn.Module):
def __init__(self, embed_dim, hidden_dim, num_classes):
super(SelfAttentionClassifier, self).__init__()
self.attention = SelfAttention(embed_dim)
self.fc1 = nn.Linear(embed_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, num_classes)
def forward(self, x):
attended_values = self.attention(x)
x = attended_values.mean(dim=1) # 对每个位置的向量求平均
x = self.fc1(x)
x = torch.relu(x)
x = self.fc2(x)
return x
- 多头注意力机制
多头注意力机制是在自注意力机制的基础上发展起来的,是自注意力机制的变体, 旨在增强模型的表达能力和泛化能力。它通过使用多个独立的注意力头,分别计算注意力权重,并将他们的结果进行拼接或加权求和,从而获的更丰富的表示。
在自注意力机制中,每个单词或者字都仅仅只有一个 与其对应,如下图所示;

多头注意力机制则是在乘以一个后,会再分配多个,这里以2个为里,如下图所示:
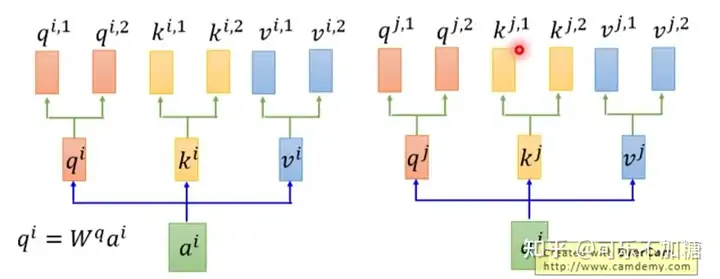
- q,k操作
在多头注意力机制中,会先乘矩阵,
其次,会为其多分配两个head,以为例,包括:;
$$q^{i,1}=W^{q,1}q^i \\ q^{i,2}=W^{q,2}q^i\qquad\text{(6)}$$
同样的,和也是一样的操作。
那么,下面就是 和 的点乘操作了,在多头注意力机制中,有多个 和,究竟应该选择哪个进行操作呢?
其实很简单,就是看下标,如下图所示。 会和 和进行点乘,再进行 操作。

- 操作
- 多头注意力机制中 操作和自注意力机制操作是类似的,如上图所示;
代码:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# 定义多头自注意力模块
class MultiHeadSelfAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super(MultiHeadSelfAttention, self).__init__()
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.query = nn.Linear(embed_dim, embed_dim)
self.key = nn.Linear(embed_dim, embed_dim)
self.value = nn.Linear(embed_dim, embed_dim)
self.fc = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
batch_size, seq_len, embed_dim = x.size()
# 将输入向量拆分为多个头
q = self.query(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
k = self.key(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
v = self.value(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
# 计算注意力权重
attn_weights = torch.matmul(q, k.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float))
attn_weights = torch.softmax(attn_weights, dim=-1)
# 注意力加权求和
attended_values = torch.matmul(attn_weights, v).transpose(1, 2).contiguous().view(batch_size, seq_len, embed_dim)
# 经过线性变换和残差连接
x = self.fc(attended_values) + x
return x
# 定义多头自注意力分类器模型
class MultiHeadSelfAttentionClassifier(nn.Module):
def __init__(self, embed_dim, num_heads, hidden_dim, num_classes):
super(MultiHeadSelfAttentionClassifier, self).__init__()
self.attention = MultiHeadSelfAttention(embed_dim, num_heads)
self.fc1 = nn.Linear(embed_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, num_classes)
def forward(self, x):
x = self.attention(x)
x = x.mean(dim=1) # 对每个位置的向量求平均
x = self.fc1(x)
x = torch.relu(x)
x = self.fc2(x)
return x
参考:https://zhuanlan.zhihu.com/p/631398525
4.4 Multi-Head Attention
在上一步,已经知道怎么通过Self-Attention 计算得到输出矩阵Z,而Multi-Head Attention是由多个Self-Attention 组合形成,下图为论文中Multi-Head Attention的结构图:

从上图可看到Multi-Head Attention包含多个Self-Attention层,首先将输入X分别传递到h个不同的Self-Attention中,计算得到h个输出矩阵Z。下图是h=8时候的情况,此时会得到8个输出矩阵Z。

得到8个输出矩阵 到 之后,Multi-Head Attention将它们拼接起来(concat),然后传入一个Linear层,得到Multi-Head Attention最终的输出Z。
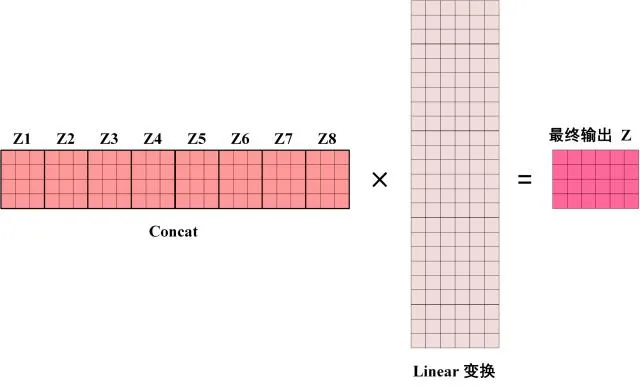
可以看出Multi-Head Attention的输出矩阵Z 与其输入的矩阵X的维度是一样的。
5. Encoder结构

上图红色部分就是Transformer的Encoder block结构,可以看到是由Multi-Head Attention,Add & Norm,Feed Forward, Add & Norm 组成。刚已经了解了Multi-Head Attention的计算过程,现在了解下Add & Norm 和 Feed Forward 部分。
5.1 Add & Norm
Add & Norm层由Add 和Norm两部分组成,其计算公式如下:
其中, 表示Multi-Head Attention或者Feed Forward的输入,MultiHeadAttention(X) 和 FeedForward(X)表示输出(输出与输入X维度是一样的,所以可以相加)。
Add 指 , 是一种残差链接,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分,在ResNet中经常用到:

Norm 指Layer Normalization,通常用于RNN结构,Layer Normalization会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
5.2 Feed Forward
Feed Forward层比较简单,是一个两层的全连接层,第一层的激活函数为Relu,第二层不使用激活函数,对应的公式如下:
X 是输入,Feed Forward最终得到的输出矩阵的维度与X 一致。
5.3 组成Encoder
通过上面描述的Multi-Head Attention, Feed Forward,Add & Norm就可以构造出一个Encoder block,Encoder block接收输入矩阵,并输出一个矩阵。通过多个Encoder block叠加就可以组成Encoder。
第一个Encoder block的输入为句子单词的表示向量矩阵,后续Encoder block的输入是前一个Encoder block的输出,最后一个Encoder block输出的矩阵就是 编码信息矩阵C,这一矩阵后续会用到Decoder中。
6. Decoder 结构

上述红色部分为Transformer的Decoder block结构,与Encoder block相似,但存在一些区别:
- 包含了两个Multi-Head Attention层
- 第一个Multi-Head Attention 层采用了Masked操作
- 第二个Multi-Head Attention 层的K,V矩阵使用Encoder 的 编码信息矩阵C 进行计算,而Q使用上一个Decoder block的输出计算。
- 最后有一个Softmax 层计算下一个翻译单词的概率。
6.1 第一个Multi-Head Attention
Decoder block的第一个Multi-Head Attention采用 Masked操作,因为在翻译的过程中是顺序翻译的,即翻译完第i个单词,才会翻译第i+1个单词。通过Masked 操作可以防止第i个单词知道i+1个单词之后的信息。下面以"我有一只猫"翻译成"I have a cat"为例,了解下Masked操作。
下面的描述中使用了类似Teacher Forcing的概念,在Decoder的时候,是需要根据之前的翻译,求解当前最有可能的翻译,如下图所示。首先根据输入"" 预测出第一个单位为"I",然后根据输入" I" 预测下一个单词"have"。

Decoder可以在训练的过程中使用Teacher Forcing并且并行化训练,即将正确的单词序列( I have a cat)和对应输出(I have cat)传递给Decoder。那么在预测第i个输出时,就要将第i+1之后的单词掩盖住,注意Mask操作是在Self-Attention的Softmax之前使用的,下面用 0 1 2 3 4 5分别表示" I have a cat "。
第一步:是Decoder的输入矩阵和 Mask矩阵,输入矩阵包含" I have a cat" (0, 1, 2, 3, 4)五个单词的表示向量, Mask是一个的矩阵。在Mask可以发现单词0只能使用单词0的信息,而单词1可以使用单词0, 1的信息,即只能使用之前的信息。

第二步:接下来的操作和之前的Self-Attention一样,通过输入矩阵X计算得到Q,K,V矩阵,然后计算Q和。
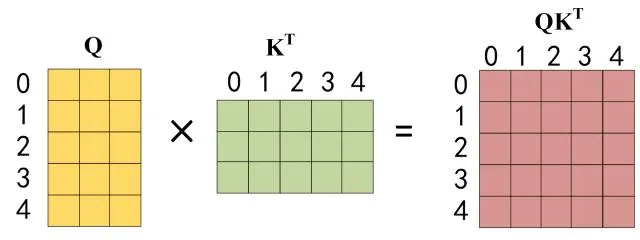
第三步: 在得到之后需要进行Softmax,计算Attention score,在Softmax之前需要使用Mask矩阵遮挡住每一个单词之后的信息,遮挡操作如下:

得到Mask 之后再Mask 上进行Softmax,每一行的和都为1。但单词0在单词1,2,3,4上的Attention score都为0.
第四步:使用Mask 与矩阵V相乘,得到输出Z,则单词1的输出向量 是只包含单词1信息的。
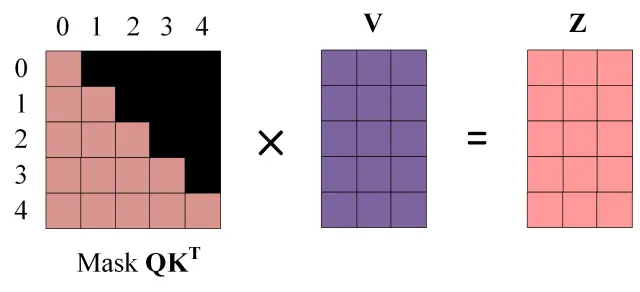
第五步:通过上述步骤就可以得到一个Mask Self-Attention的输出矩阵,然后和Encoder 类似,通过Multi-Head Attention拼接多个输出 然后计算得到第一个Multi-Head Attention的输出Z,Z与输出X维度一样。
6.2 第二个Multi-Head Attention
Decoder block第二个Multi-Head Attention变化不大,主要的区别在于其中Self-Attention的K,V矩阵不是使用 上一个Decoder block的输出计算的,而是使用 Encoder的编码信息矩阵C计算的。
根据Encoder的输出C计算得到K,V,根据上一个Decoder block的输出Z 计算Q(如果是第一个Decoder block则使用输入矩阵X进行计算),后续的计算方法与之前描述的一致。
这样做的好处是在Decoder的时候,每一个单词都可以利用到Encoder所有单词的信息(这些信息无需Mask)
6.3 Softmax预测输出单词
Decoder block最后的部分是利用Softmax预测下一个单词,在之前的网络层可以得到一个最终输出Z,因为Mask的存在,使得单词0的输出 只包含单词0的信息,如下:

Softmax根据输出矩阵的每一行预测下一个单词:

这就是Decoder block的定义,与Encoder一样,Decoder是由多个Decoder block组合而成。
7 Transformer 总结
- Transformer 与 RNN 不同,可以比较好地并行训练。
- Transformer 本身是不能利用单词的顺序信息的,因此需要在输入中添加位置 Embedding,否则 Transformer 就是一个词袋模型了。
- Transformer 的重点是 Self-Attention 结构,其中用到的 Q, K, V矩阵通过输出进行线性变换得到。
- Transformer 中 Multi-Head Attention 中有多个 Self-Attention,可以捕获单词之间多种维度上的相关系数 attention score。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号