
ZeRO:一种去除冗余的数据并行方案
ZeRO:一种去除冗余的数据并行方案
目前训练超大规模语言模型主要有两条技术路线:
- TPU + XLA + TensorFlow/JAX
- GPU + Pytorch + Megatron + DeepSpeed
前者由Google主导,由于TPU和自家云平台GCP深度绑定,对于非Googler来说并不友好
后者背后则有NVIDIA、Meta、MS等大厂加持,社区氛围活跃,也更受群众欢迎
另,上面提到的DeepSpeed的核心就是ZeRO(Zero Redundancy Optimizer),它是一种显存优化的数据并行(data parallelism,DP)方案
ZeRO:论文链接:https://arxiv.org/abs/1910.02054
背景
如今训练大模型离不开各种分布式并行策略,常用的并行策略包括:
- 数据并行(Data Parallelism,DP)
假设有N张卡,每张卡都要保存一个模型,每次迭代(iteration/step)都将batch数据分隔成N个大小的micro-batch,每张卡根据拿到的micro-batch数据独立计算梯度,然后调用AllReduce计算梯度均值,每张卡在独立进行参数更新。
PS:
模型每张卡都存,数据切分,由每张卡单独计算
# https://huggingface.co/docs/transformers/parallelism#model-parallelism
# 假设模型有三层:L0, L1, L2
# 每层有两个神经元
# 两张卡
GPU0:
L0 | L1 | L2
---|----|---
a0 | b0 | c0
a1 | b1 | c1
GPU1:
L0 | L1 | L2
---|----|---
a0 | b0 | c0
a1 | b1 | c1
- 模型并行(Model Parallelism/Tensor Parallelism,MP/TP)
有的tensor/layer很大,一张卡放不下,将tensor分割成多块,一张卡存一块
如果模型的规模比较大,单个 GPU 的内存承载不下时,我们可以将模型网络结构进行拆分,将模型的单层分解成若干份,把每一份分配到不同的 GPU 中,从而在训练时实现模型并行。
训练过程中,正向和反向传播计算出的数据通过使用All gather或者All reduce的方法完成整合。这样的特性使得模型并行成为处理模型中大 layer 的理想方案之一。然而,深度神经网络层与层之间的依赖,使得通信成本和模型并行通信群组中的计算节点 (GPU) 数量正相关。其他条件不变的情况下,模型规模的增加能够提供更好的计算通信比。
# https://huggingface.co/docs/transformers/parallelism#model-parallelism
# 假设模型有三层:L0, L1, L2
# 每层有两个神经元
# 两张卡
GPU0:
L0 | L1 | L2
---|----|---
a0 | b0 | c0
GPU1:
L0 | L1 | L2
---|----|---
a1 | b1 | c1
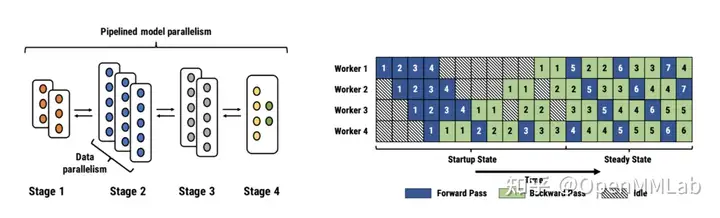
- 流水线并行(Pipline parallelism,PP)
将网络按层切割,划分成多组,一张卡存一组。
流水线并行,可以理解为层与层之间的重叠计算,也可以理解为按照模型的结构和深度,将不同Layer分配给指定GPU进行计算。
相较于数据并行需要GPU之间的通信,流水线并行只需其之间点对点通讯部分activations,这样的特性可以使流水并行对通讯带宽的需求降到更低。然而,流水并行需要相对稳定的通讯频率来确保效率,这导致在应用时需要手动进行网络分段,并插入繁琐的通信原语。同时,流水线并行的并行效率也依赖各卡负载的手动调优。这些操作都对应用该技术的研究员提出了更高的要求。
# https://huggingface.co/docs/transformers/parallelism#model-parallelism
# 假设模型有8层
# 两张卡
====================== =====================
| L0 | L1 | L2 | L3 | | L4 | L5 | L6 | L7 |
====================== =====================
GPU0 GPU1
# 设想一下,当GPU0在进行(前向/后向)计算时,GPU1在干嘛?闲着
# 当GPU1在进行(前向/后向)计算时,GPU0在干嘛?闲着
# 为了防止”一卡工作,众卡围观“,实践中PP也会把batch数据分割成
# 多个micro-batch,流水线执行
流水线并行:
为什么需要ZeRO
上述三种并行方式中,数据并行因其易用性,得到了最为广泛的应用。然而,数据并行会产生大量冗余Model State的空间占用。
ZeRO的本质,是在数据并行的基础上,对冗余空间进行深度优化。
PS:
大模型训练中的显存占用可以分为Model State和Activation两部分
1、Model State
- 优化器状态(Optimizer States):是Optimizer 在进行梯度更新时所需要用到数据。一些优化器(如Adam)需要存储额外的状态信息,如梯度的移动平均值和平方梯度的移动平均值。例如SGD中的Momentum亦即使用混合精度训练时的Float32 Master Parameters
- 模型参数(Model Parameters):存储在显存中的模型权重和偏置项
- 梯度(Gradients): 在反向传播过程中计算得到的梯度,用于更新模型参数。其决定了参数的更新方向
它们三个简称OPG,其中优化器状态会占据大约2倍参数量的显存空间,这取决于选择的优化器,也是整个训练中占据最大空间的部分。
2、 Activation - 中间激活值(Intermediate Activations): 在前向传播过程中,神经网络的每一层会产生中间激活值,这些激活值需要再反向传播过程中用来计算梯度
- 输入数据(Input Data): 批处理中输入数据也占用显存,尤其是当批处理较大时。
在传统数据并行下,每个进程都使用同样参数进行训练。每个进程也会持有对 Optimizer States 的完整拷贝,同样使用了大量显存。在混合精度场景下,以参数量为\(\Psi\) 的模型和Adam Optimizer为例,Adam需要保存:
- Float16 的 参数 和 梯度 的备份,这两项分别消耗了为\(2\Psi\) 和 \(2\Psi\)内存。(1 Float16 = 2Bytes)
- Float32 的 参数, Momentum, Variance备份,对应到3份 \(4 \Psi\) 的内存空间。(1 Float32 = 4Bytes)
终需要\(2\Psi + 2\Psi + K\Psi = 16\Psi\)Bytes 的显存。
一个7.5B参数量的模型,就需要至少120GB的显存空间才能装下这些Model Stats。当数据并行时,这些重复的Model State会在N个GPU上复制N份
ZeRO则在数据并行的基础上,引入了对冗余Model States的优化。使用ZeRO后,各个进程之后只保存完整状态的1/GPUs,互不重叠,不再存在冗余。在本文中,就以7.5B参数量的模型为例,量化各个级的ZeRO对于内存的优化表现。
ZeRO的三个级别
相比传统数据并行的简单复制,ZeRO通过将模型的 参数、梯度 和 Optimizer State划分到不同的进程来消除冗余的内存占用
ZeRO 有三个不同级别,分别对应Model States 不同程度的分割(Partition):
- ZeRO-1: 分割Optimizer States
- ZeRO-2: 分割Optimizer States 与 Gradients
- ZeRO-3: 分割Optimizer States、Gradients 与 Parameters;

ZeRO-1
模型训练中,正向传播和反向传播并不会用到优化器状态,只有在梯度更新的时候才会使用梯度和优化器状态计算新参数。因此每个进程单独使用一段优化器状态,对各自进程的参数更新完之后,再把各个进程的模型参数合并形成完整的模型。
假设我们有 𝑁𝑑 个并行的进程,ZeRO-1 会将完整优化器的状态等分成 𝑁𝑑 份并储存在各个进程中。当反向传播完成之后,每个进程的优化器会对自己储存的优化器状态(包括Momentum、Variance 与 FP32 Master Parameters)进行计算与更新。更新过后的Partitioned FP32 Master Parameters会通过All-gather传回到各个进程中。完成一次完整的参数更新。
通过 ZeRO-1 对优化器状态的分段化储存,7.5B 参数量的模型内存占用将由原始数据并行下的 120GB 缩减到 31.4GB。
ZeRO-2
第二阶段中对梯度进行了拆分,在一个Layer的梯度都被计算出来后: 梯度通过All-reduce进行聚合, 聚合后的梯度只会被某一个进程用来更新参数,因此其它进程上的这段梯度不再被需要,可以立马释放掉。
通过 ZeRO-2 对梯度和优化器状态的分段化储存,7.5B 参数量的模型内存占用将由 ZeRO-1 中 31.4GB 进一步下降到 16.6GB
ZeRO-3
第三阶段就是对模型参数进行分割。
在ZeRO3中,模型的每一层都被切片,每个进程存储权重张量的一部分。在前向和后向传播过程中(每个进程仍然看到不同的微批次数据),不同的进程交换它们所拥有的部分(按需进行参数通信),并计算激活函数和梯度。
初始化的时候。ZeRO-3将一个模型中每个子层中的参数分片放到不同进程中,训练过程中,每个进程进行正常的正向/反向传播,然后通过All-gather进行汇总,构建成完整的模型。
图解
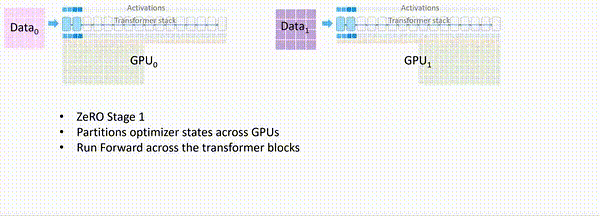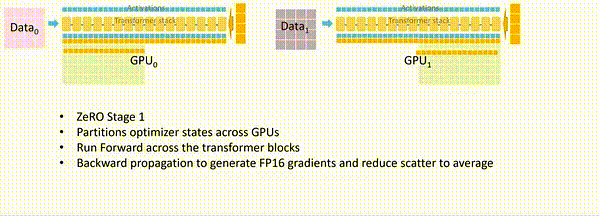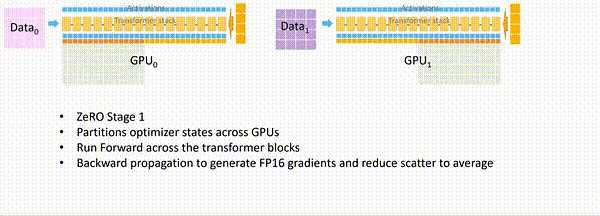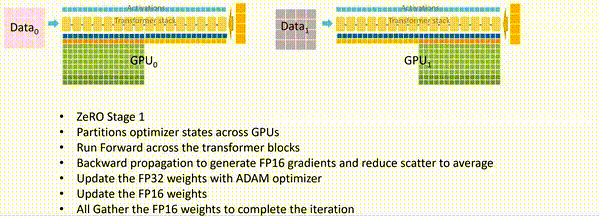
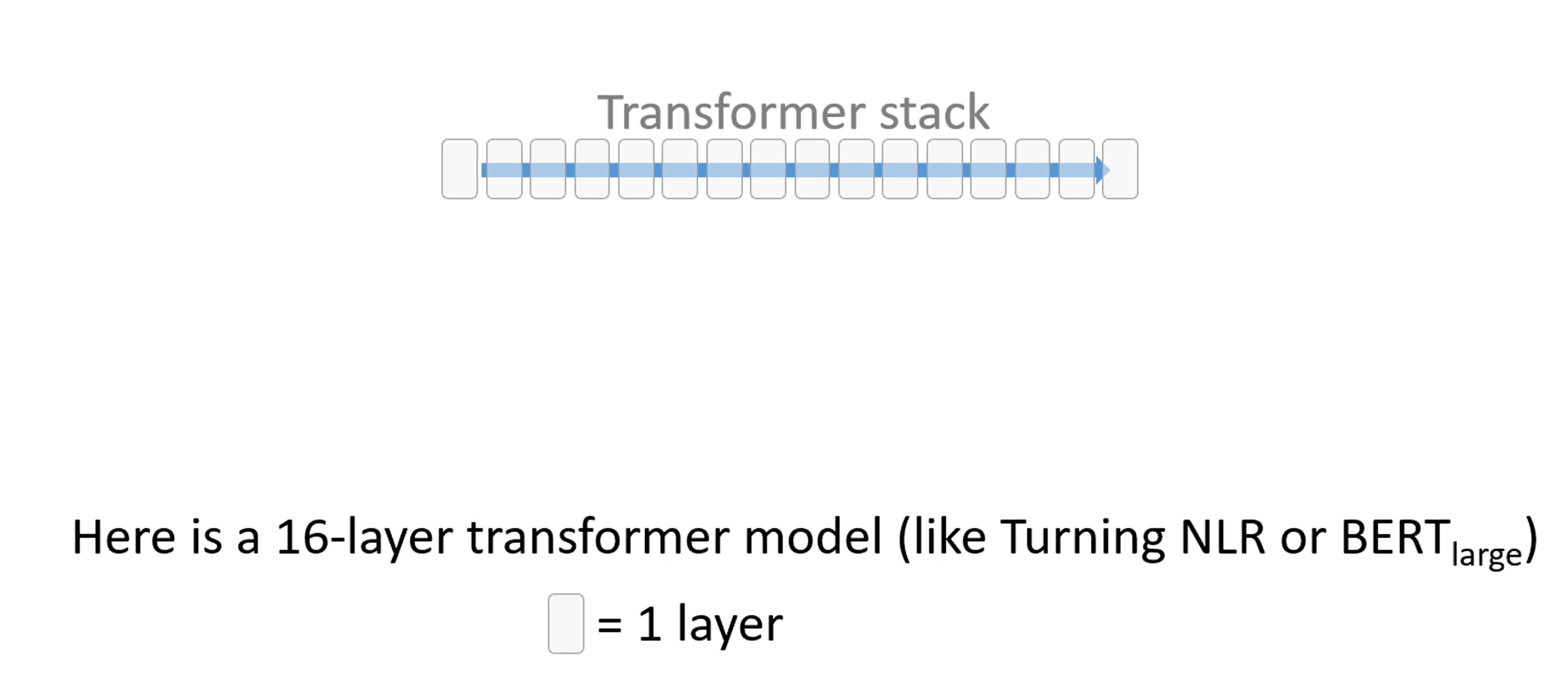
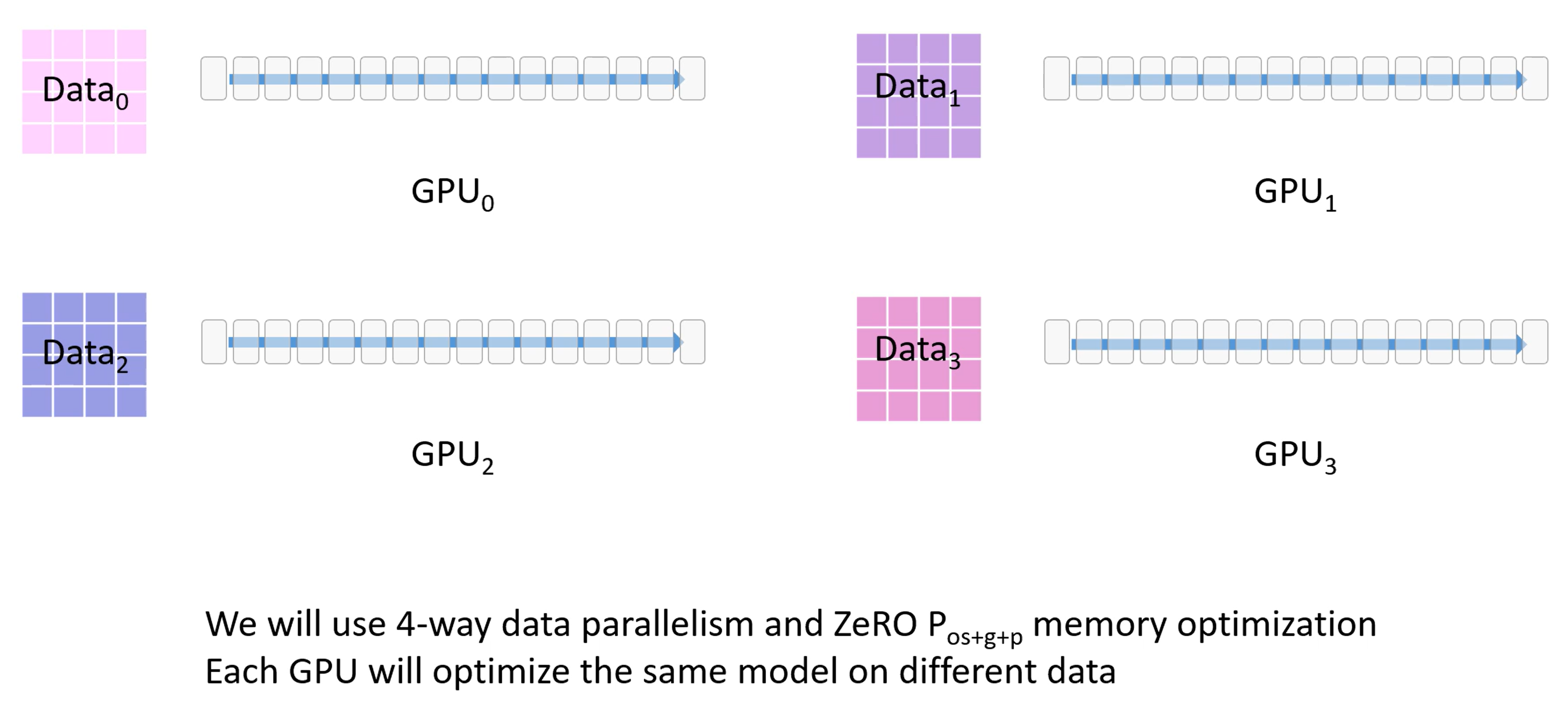
官方给出了一个五分钟的解释视频,我们一张张截取看一下:
-
首先我们有一个16个Transformer块构成的模型,每一个块都是一个Transformer块。
-
有一个很大的数据集和四个GPU

-
使用三阶段策略,将OPG和数据都进行拆分放在四张卡上。
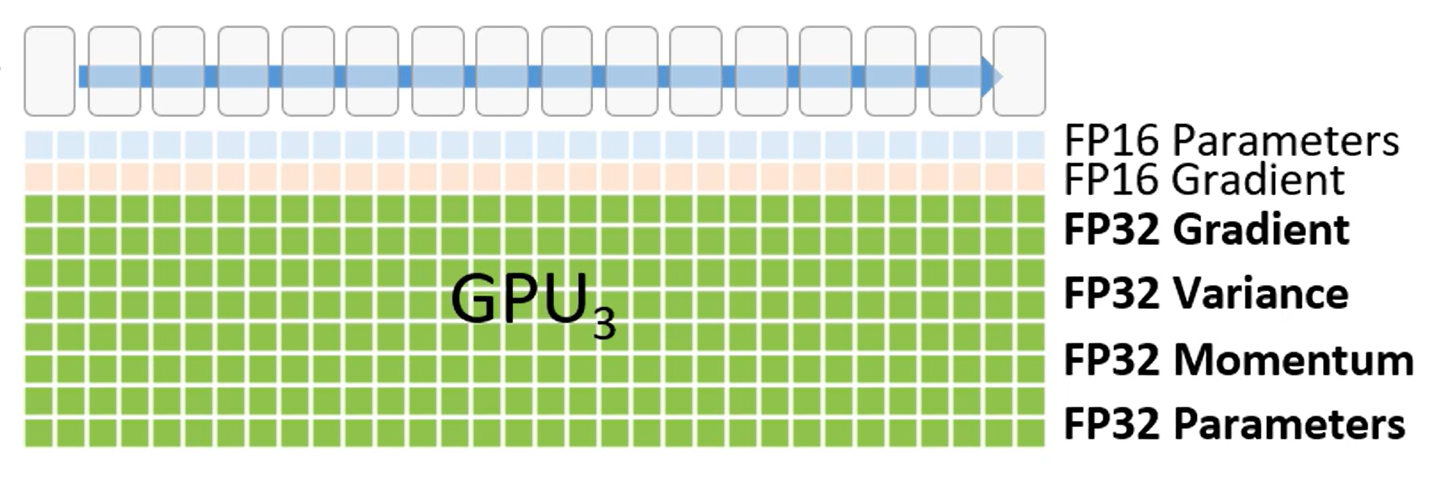
-
每个模块下的格子代表模块占用的显存。
第一行是FP16版本的模型权重参数
第二行是FP16的梯度,用来反向传播时更新权重,
剩下的大部分绿色部分是优化器使用的显存部分,包含(FP32梯度,FP32方差,FP32动量,FP32参数),它只有在FP16梯度计算后才会被使用。
ZeRO3使用了混合精度,因此前向传播中使用了半精度的参数。

-
每个模块还需要一部分空间用于存放激活值,也就是上面蓝色的部分。

-
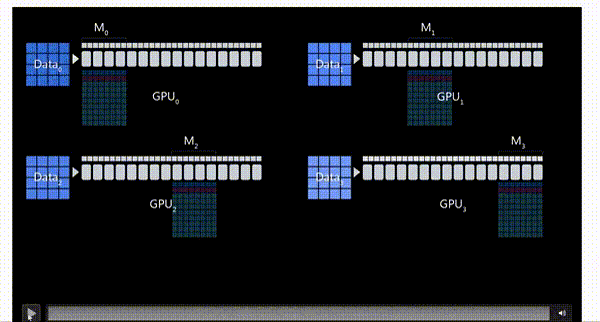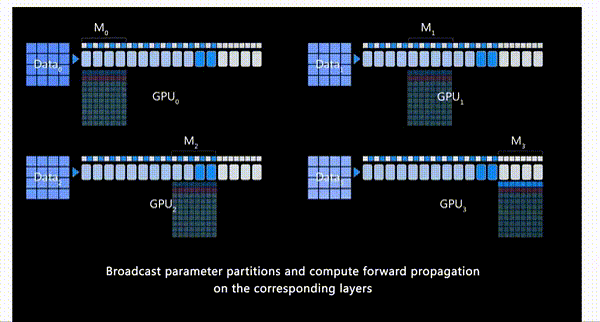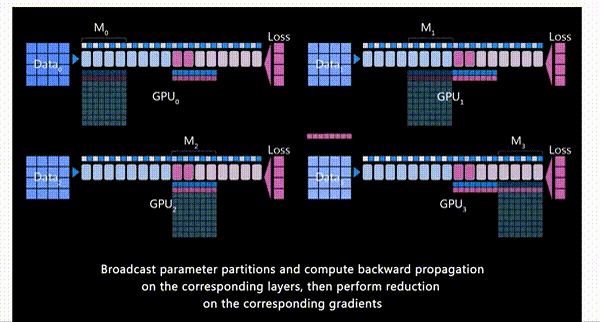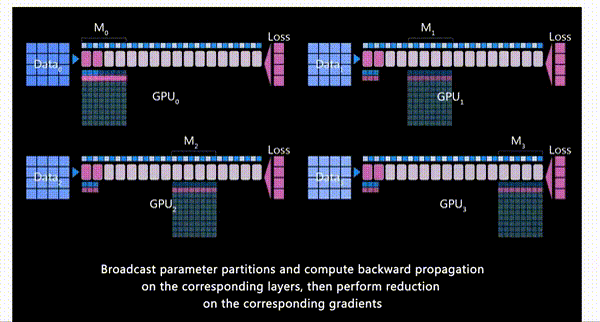
每个GPU都会负责模型的一部分,也就是图中的 \(M_0 - M_3\)
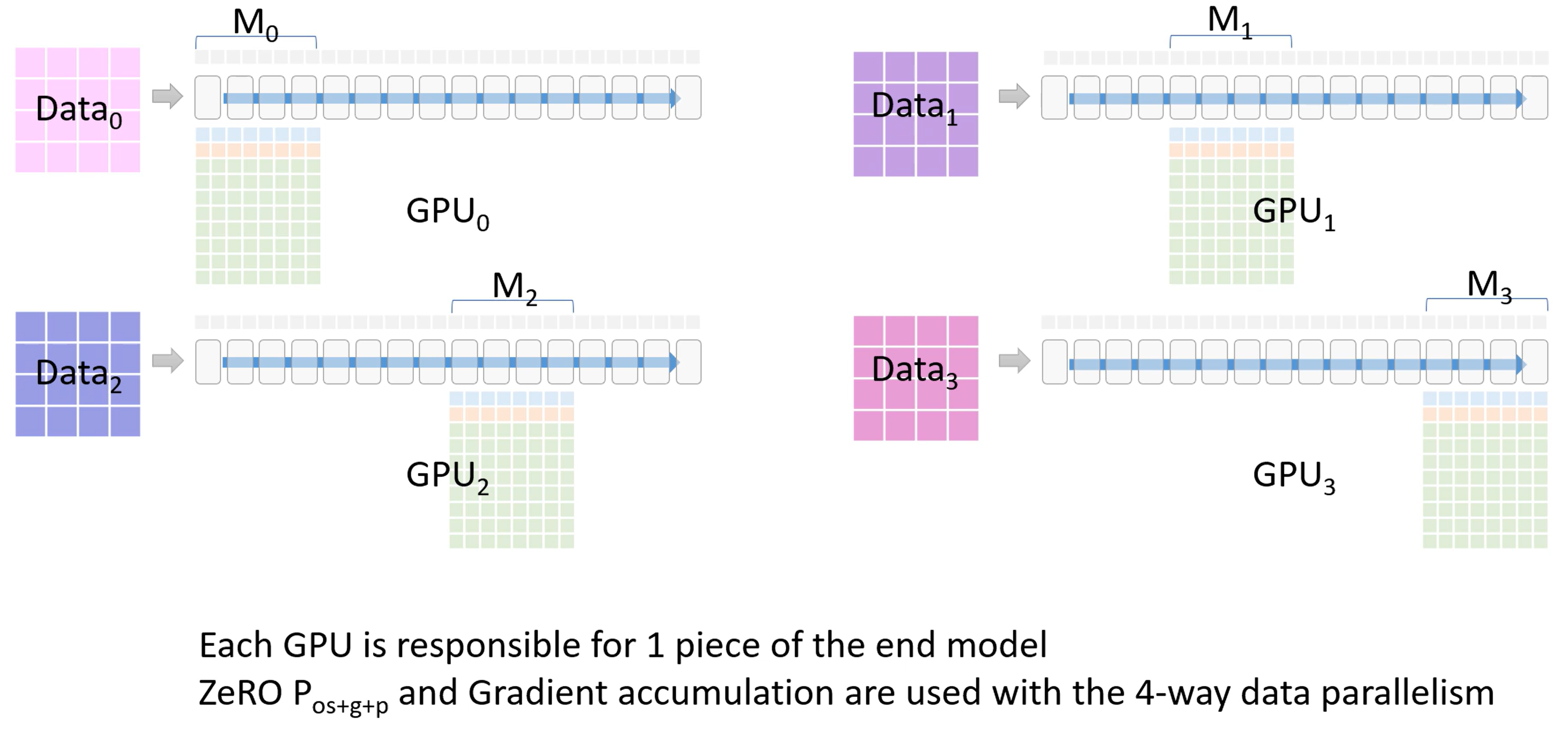
-
现在进入ZeRO3的一个分布式训练流程:
-
首先,GPU_0将自身已经有的模型部分权重\(M_0\)通过broadcast发送到其他GPU。
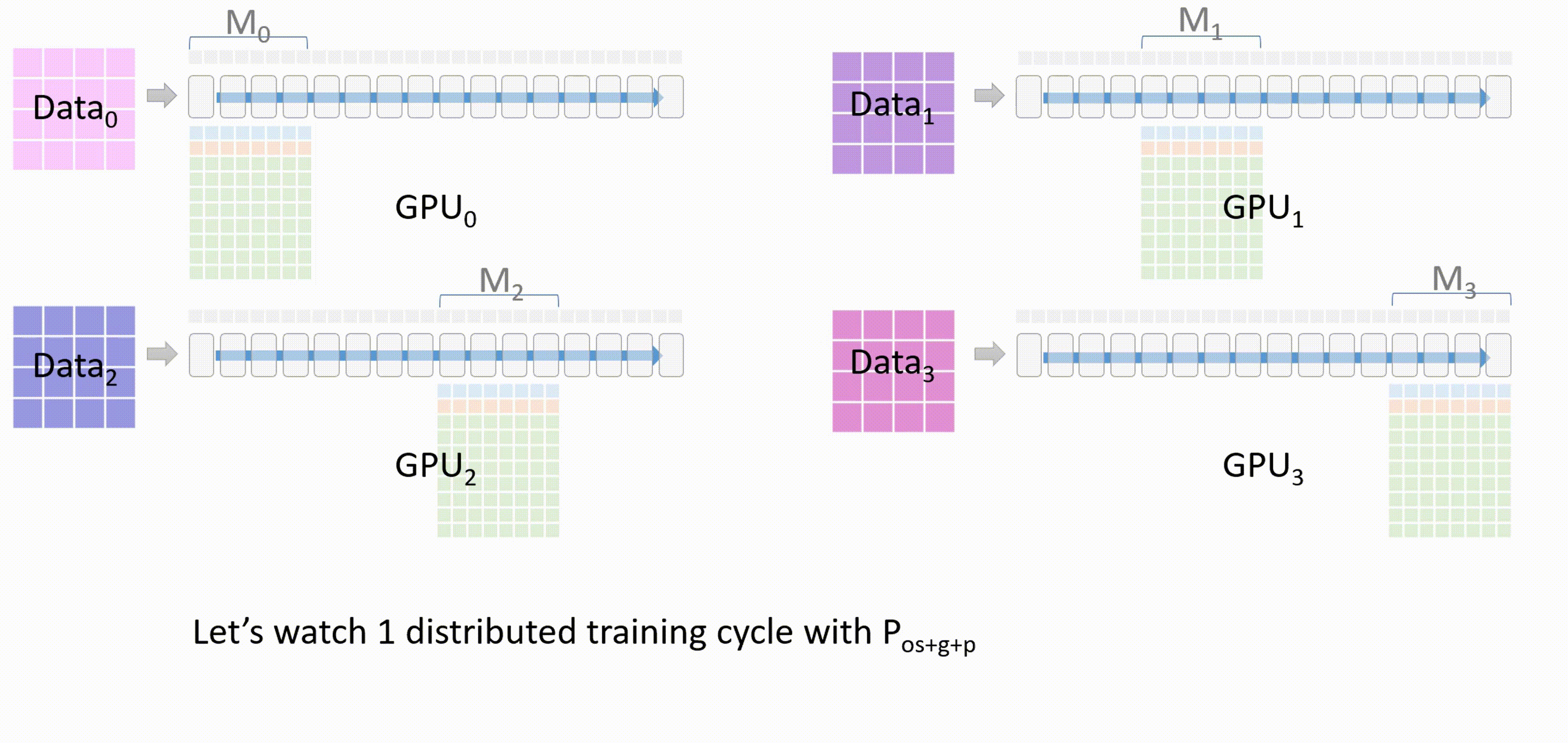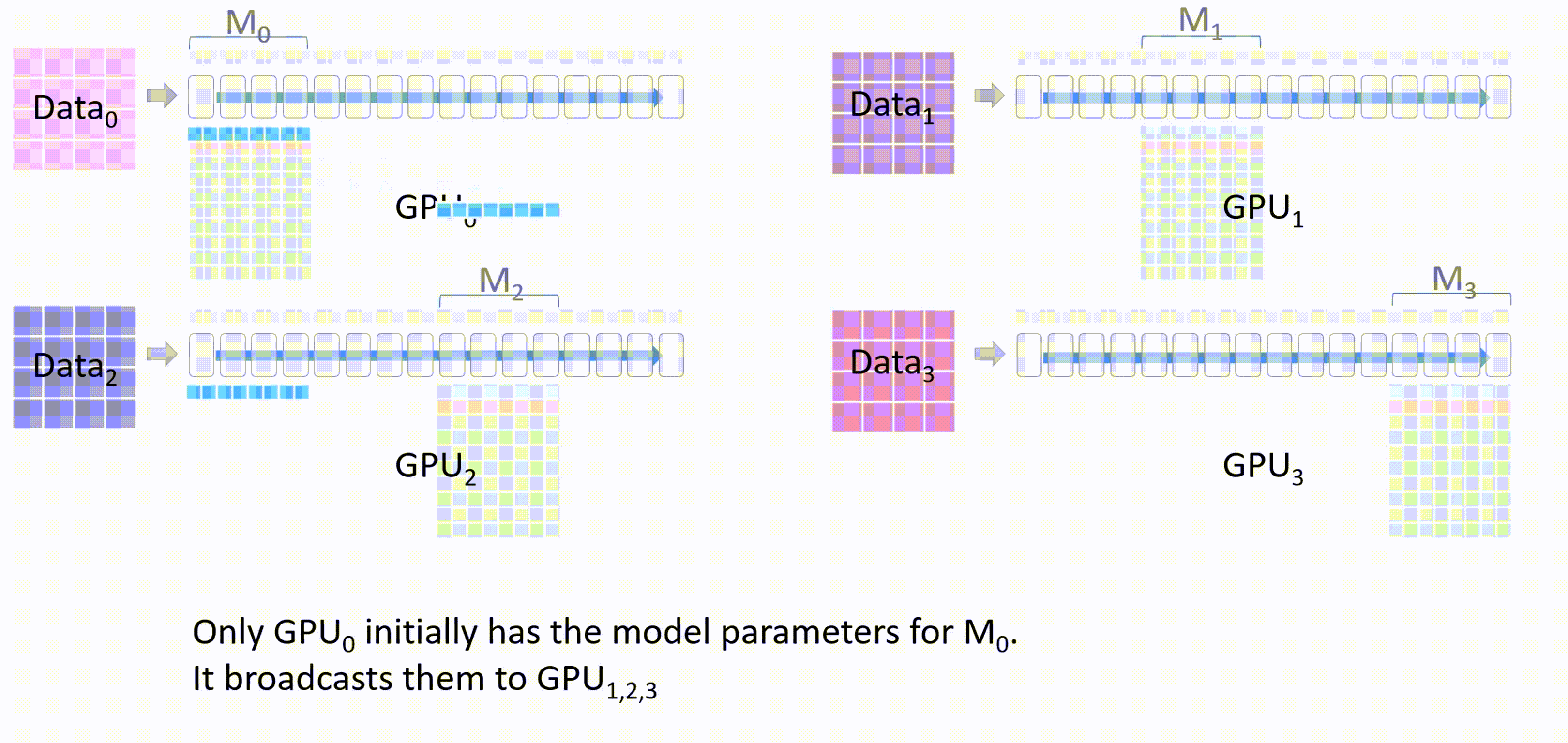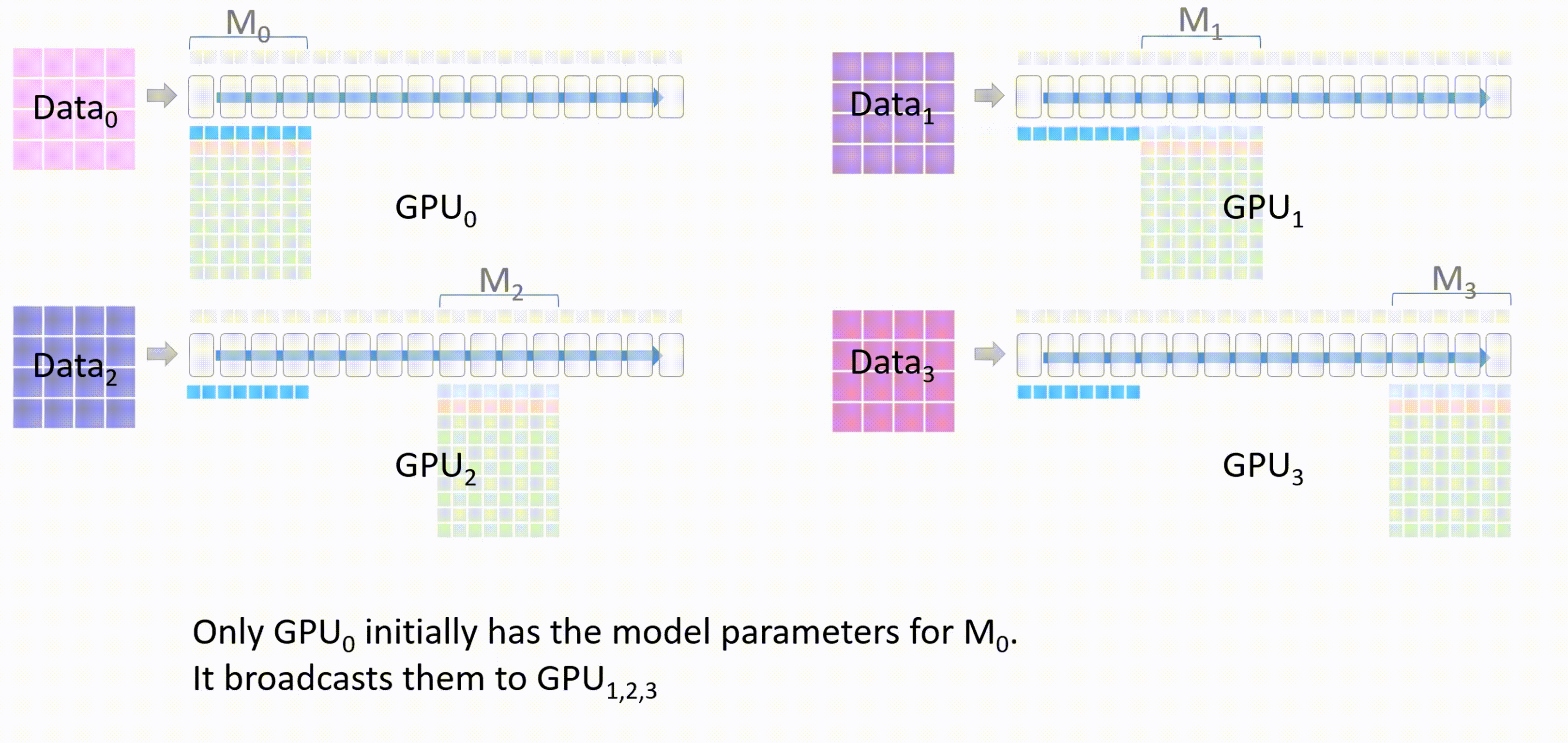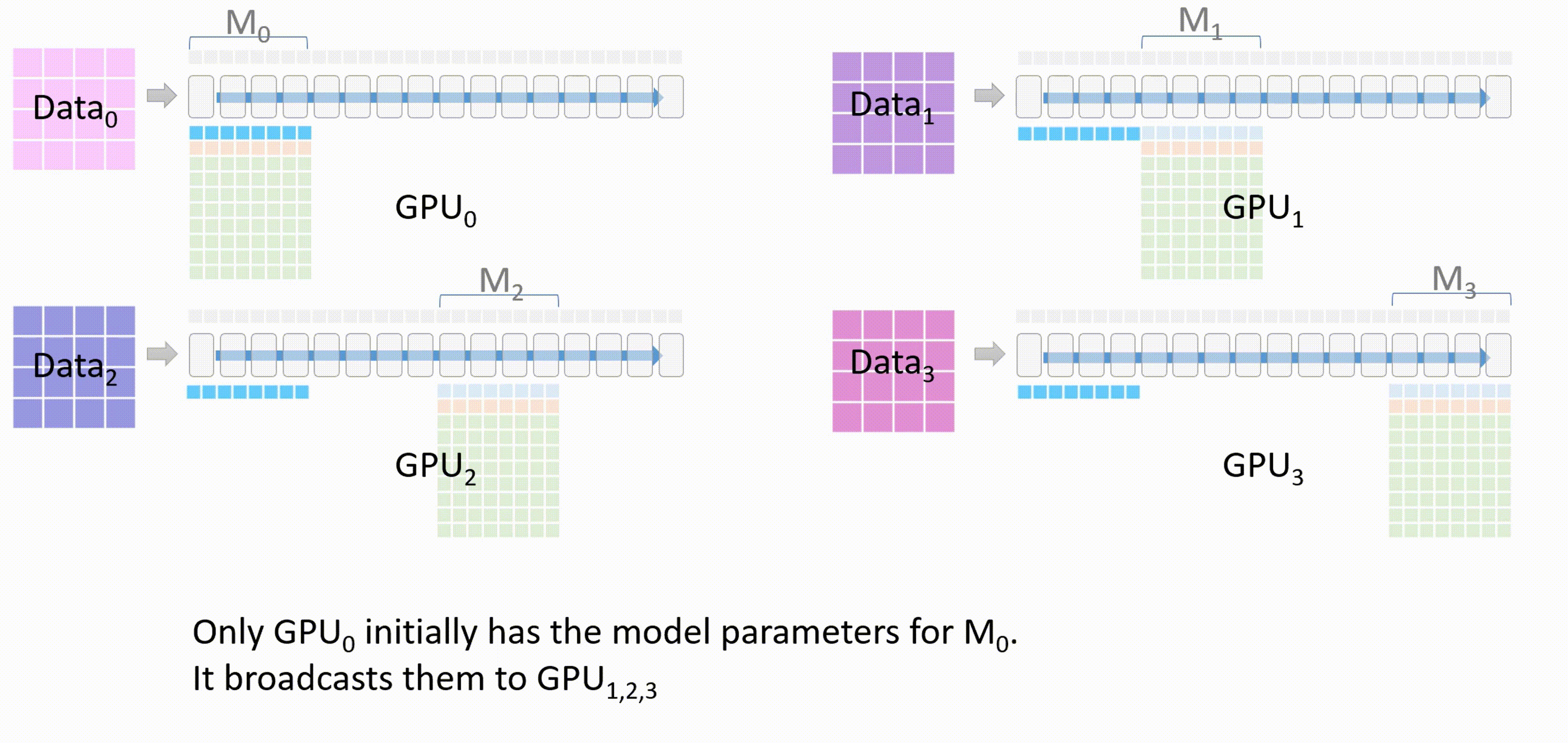
-
当所有GPU都有了权重\(W_0\)后,除了GPU_0以外的GPU会将它们存储在一个临时缓存中
-
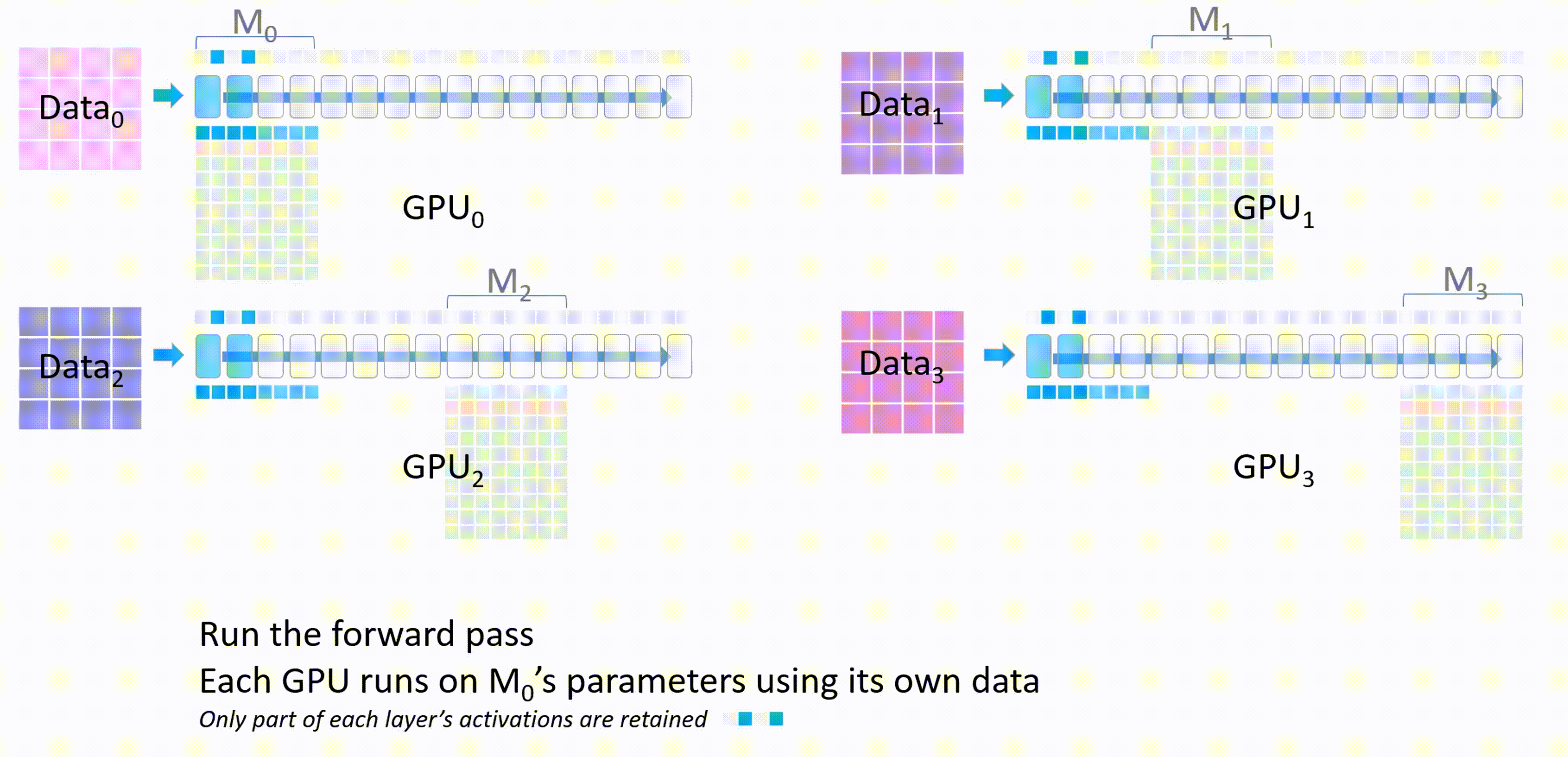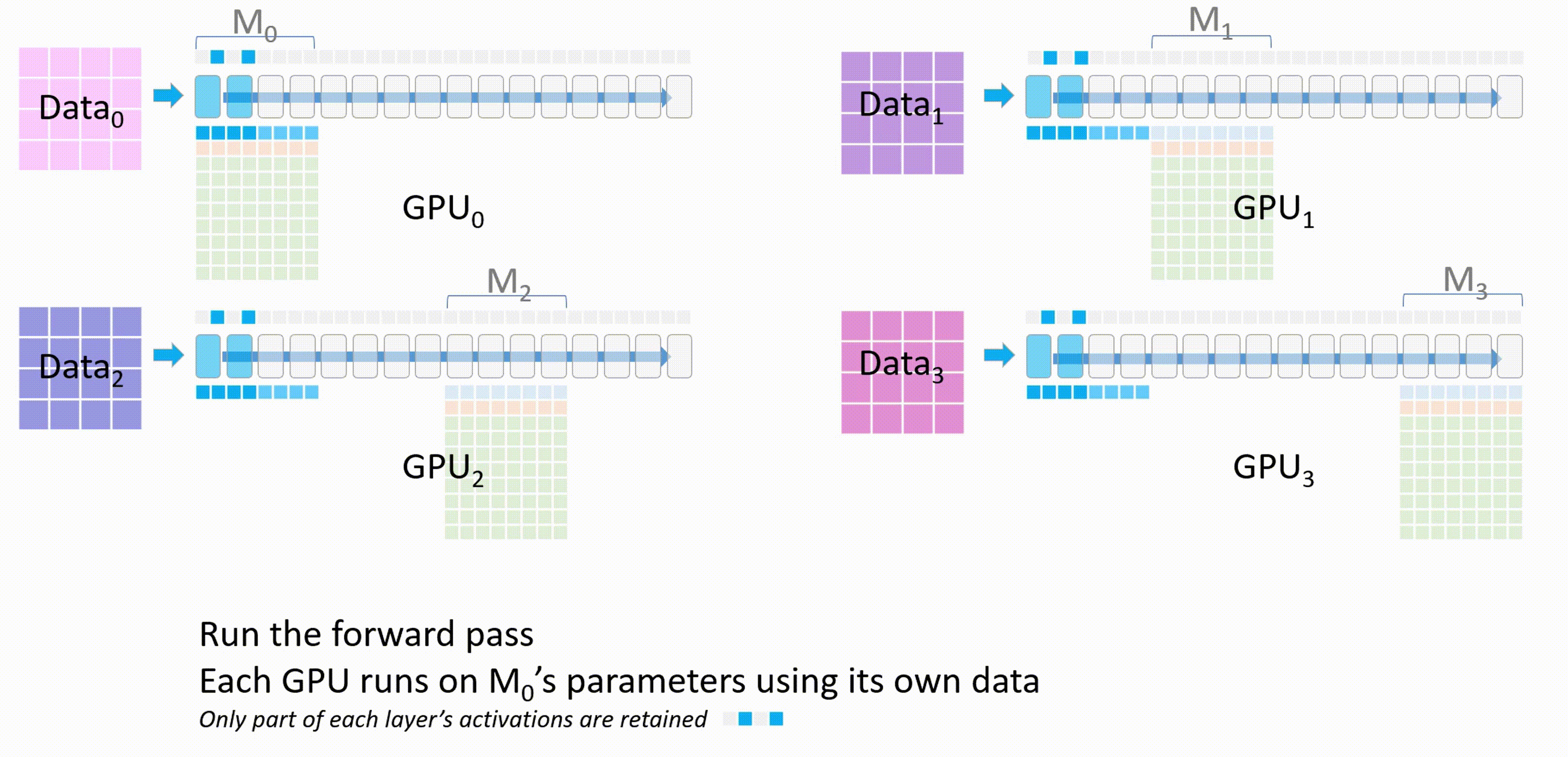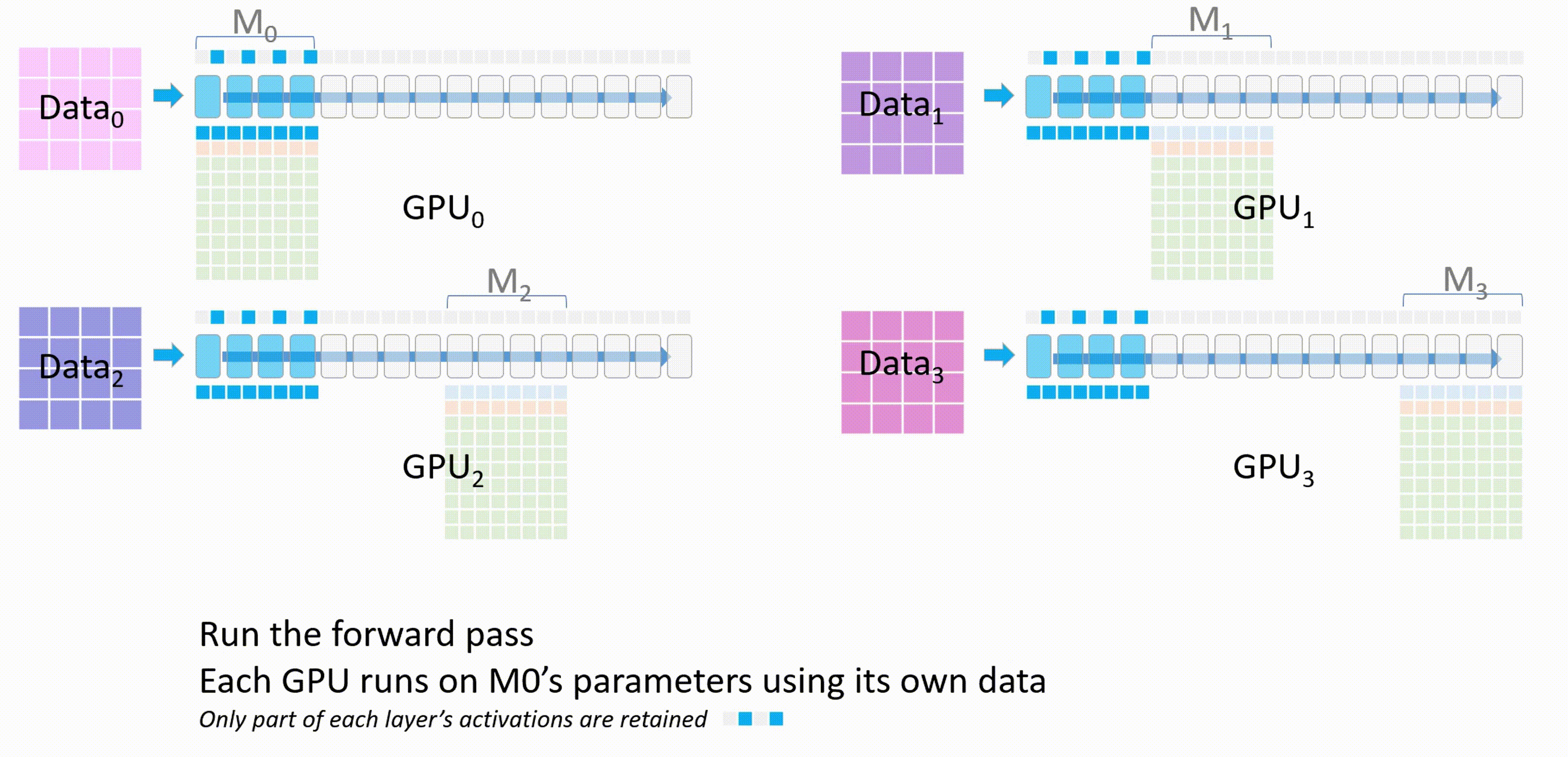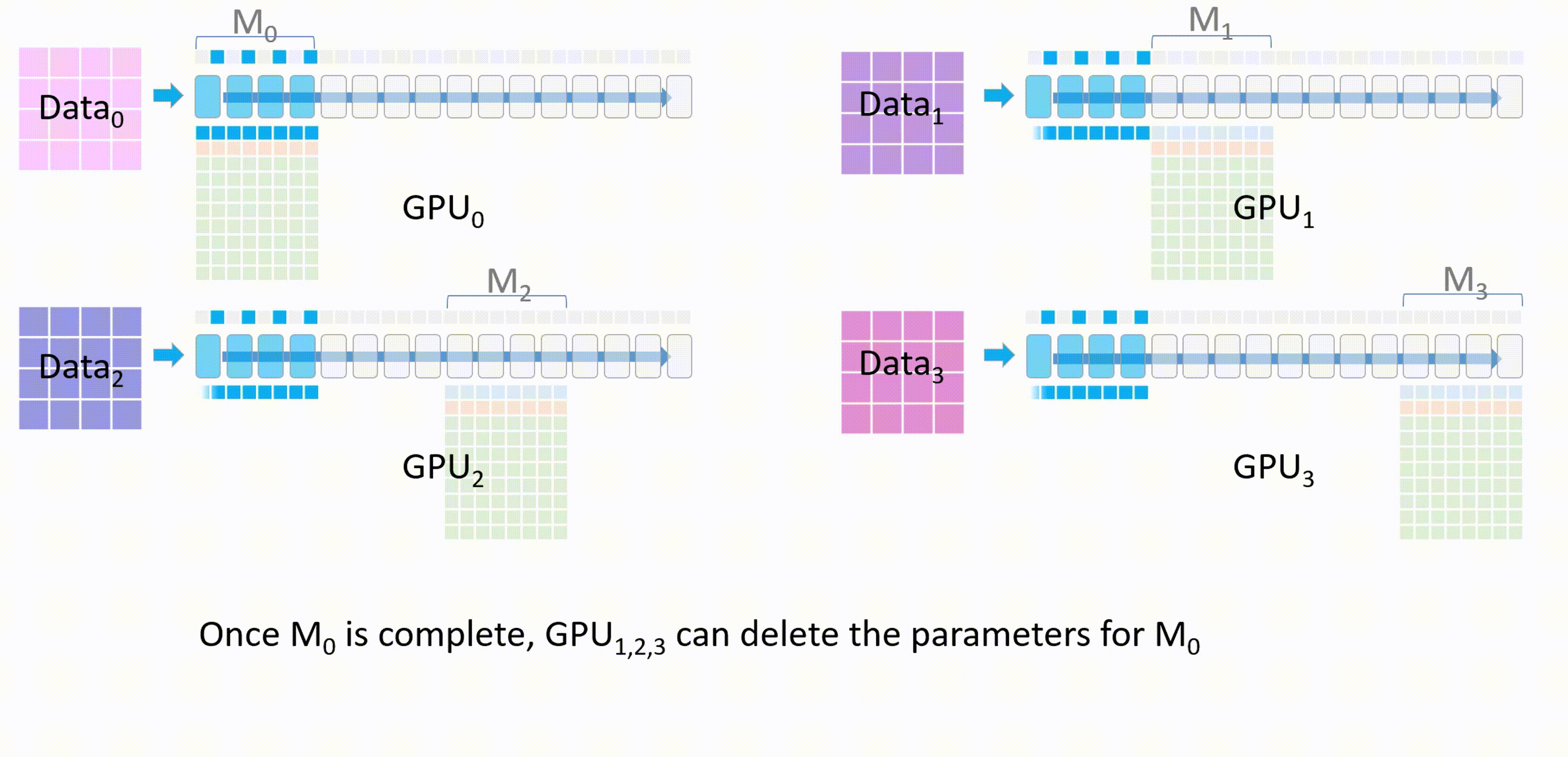
进行前向传播,每个GPU都会使用\(M_0\)的参数在自己的进程的数据上进行前向传播,只有每个层的激活值会被保留
-
\(M_0\)计算完成后,其他GPU删除这部分的模型参数。
-
接下来,GPU_1将自己的模型权重\(M_1\)广播发送到其他GPU。所有GPU上使用\(M_1\)进行前向传播
-
\(M_1\)计算完成后,其他GPU删除这部分的模型参数。
-
以此类推,将每个GPU上的各自的模型权重都训练完。
-
前向传播结束后,每个GPU都根据自己数据集计算一个损失
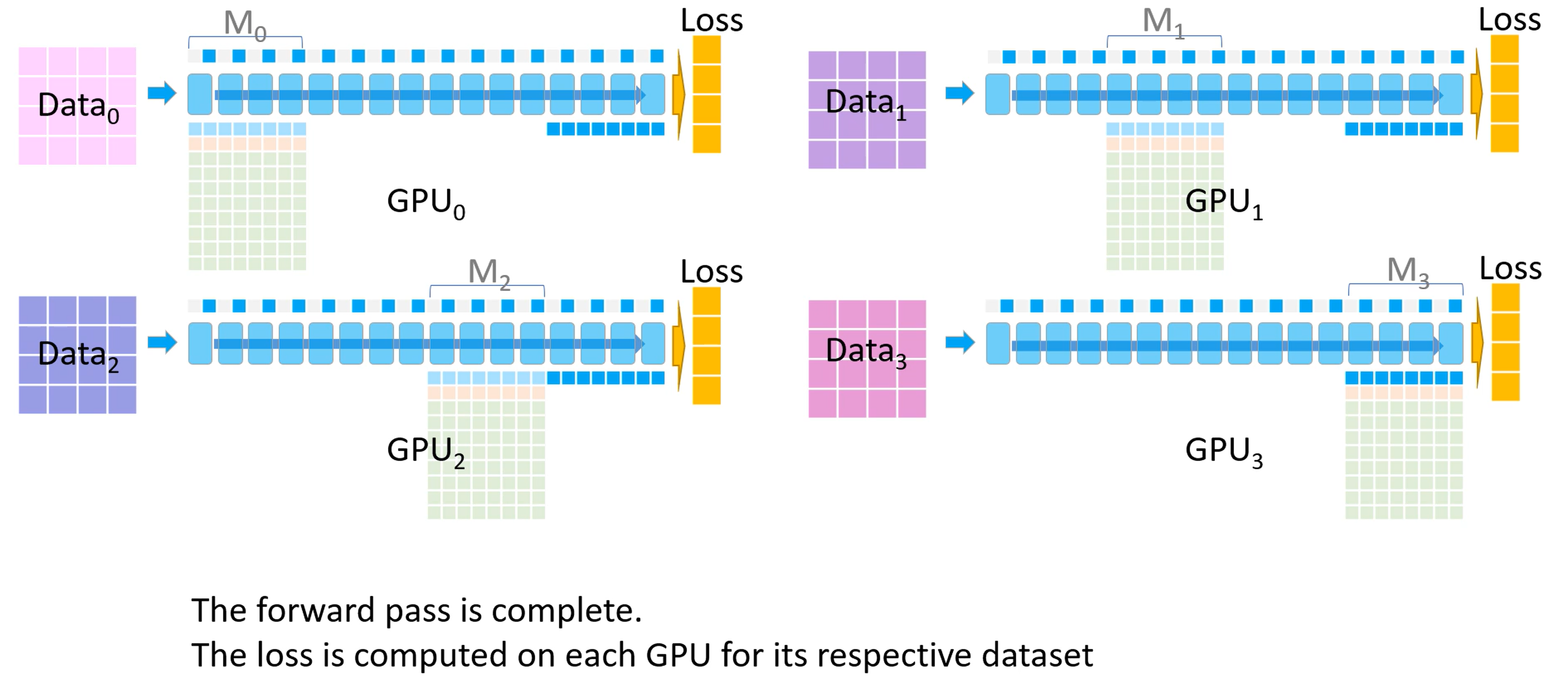
-
开始反向传播。首先所有GPU都会拿到最后一个模型分块(也就是\(M_3\))的损失。反向传播会在这块模型上进行,\(M_3\)的激活值会从保存好的激活值上进行计算。

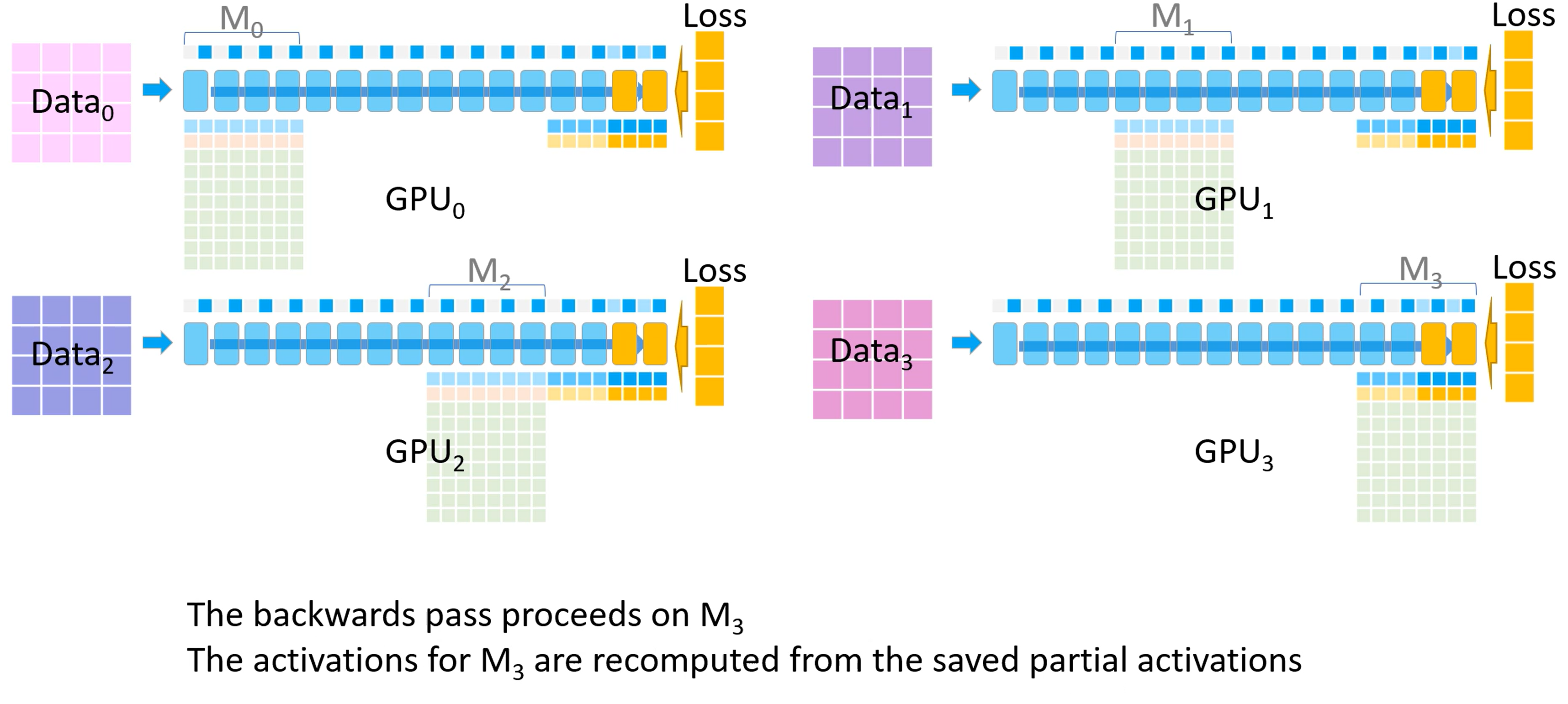
-
其他GPU将自己计算的\(M_3\)的梯度发送给GPU_3进行梯度累积,最后在GPU_3上更新并保存最终的\(M_3\)权重参数。
备注:梯度累积,将几个小批次的数据的梯度累积,累加够一个大批次后更新模型权重。
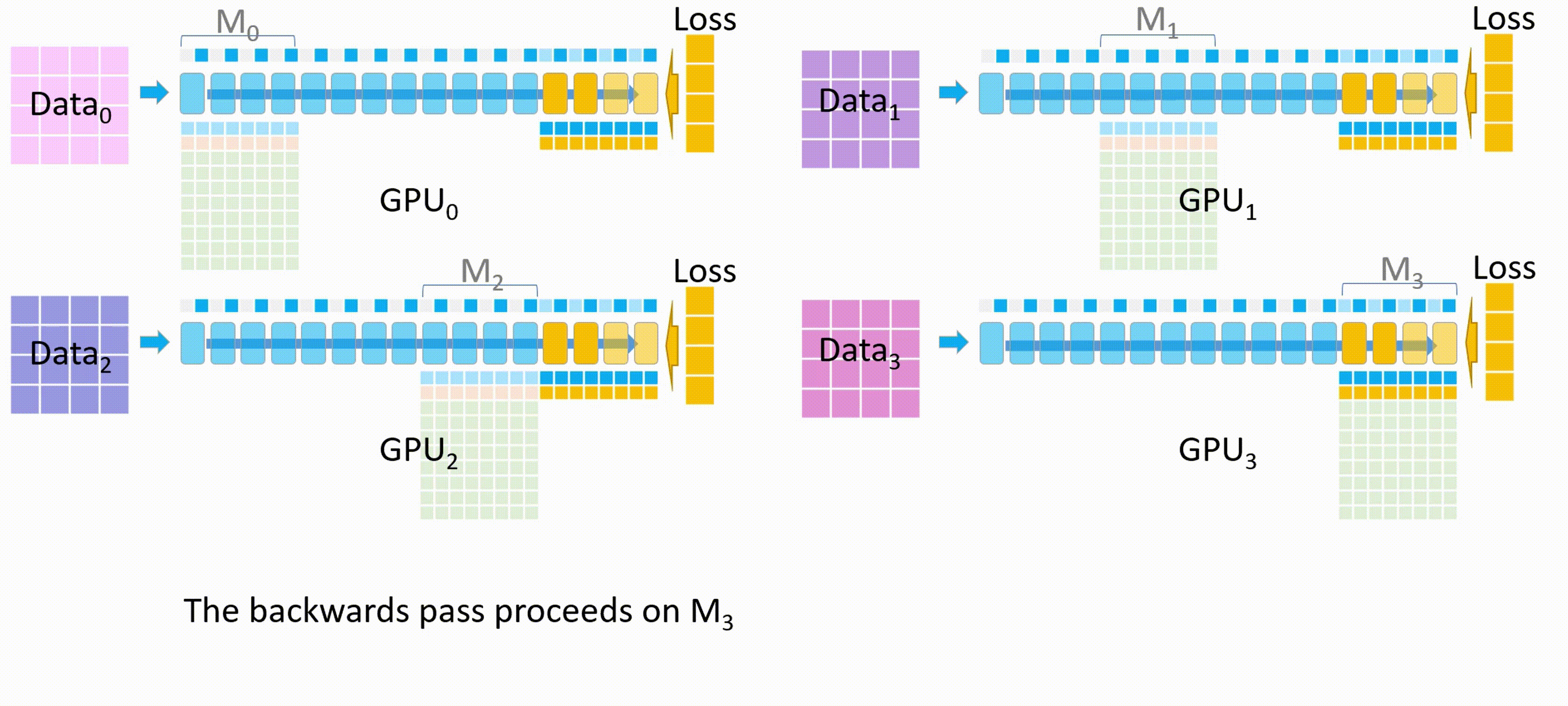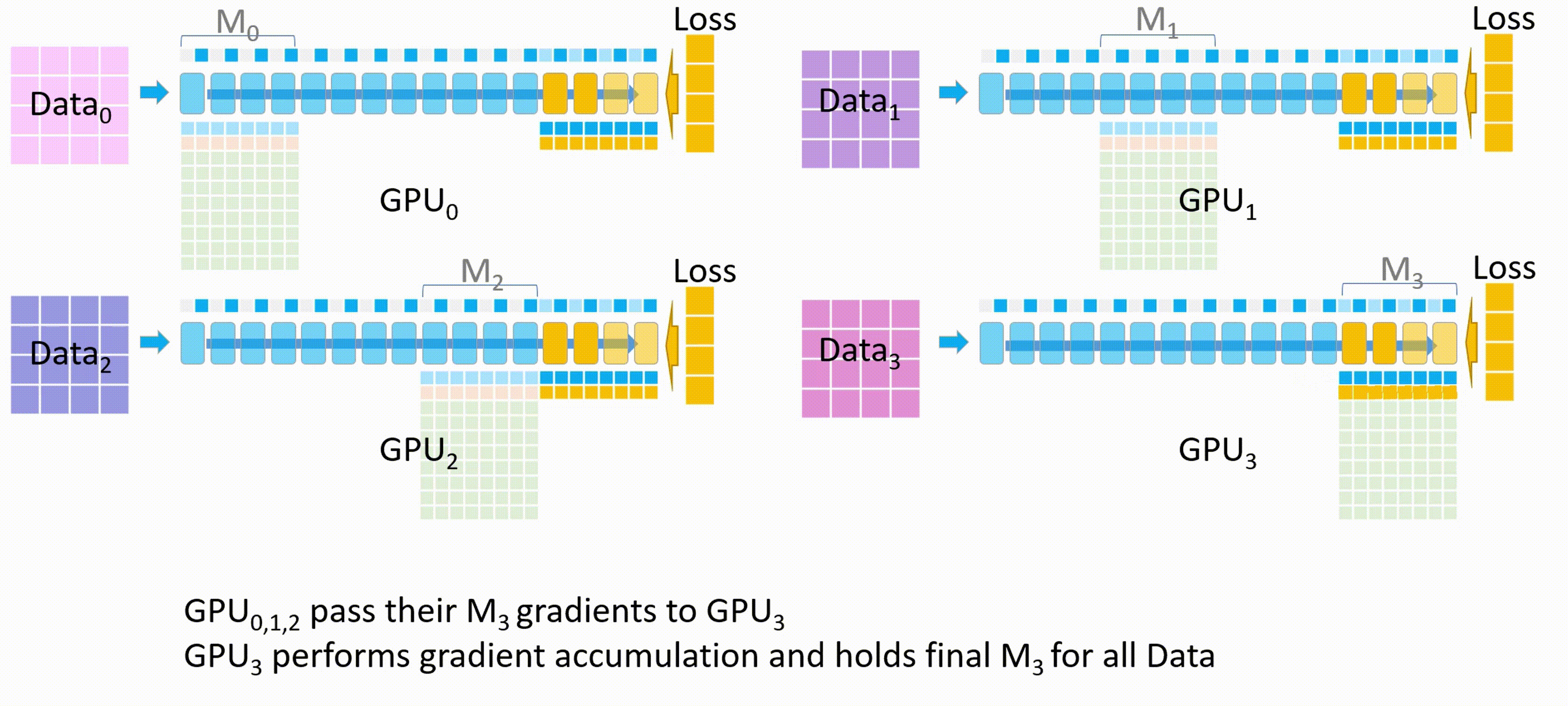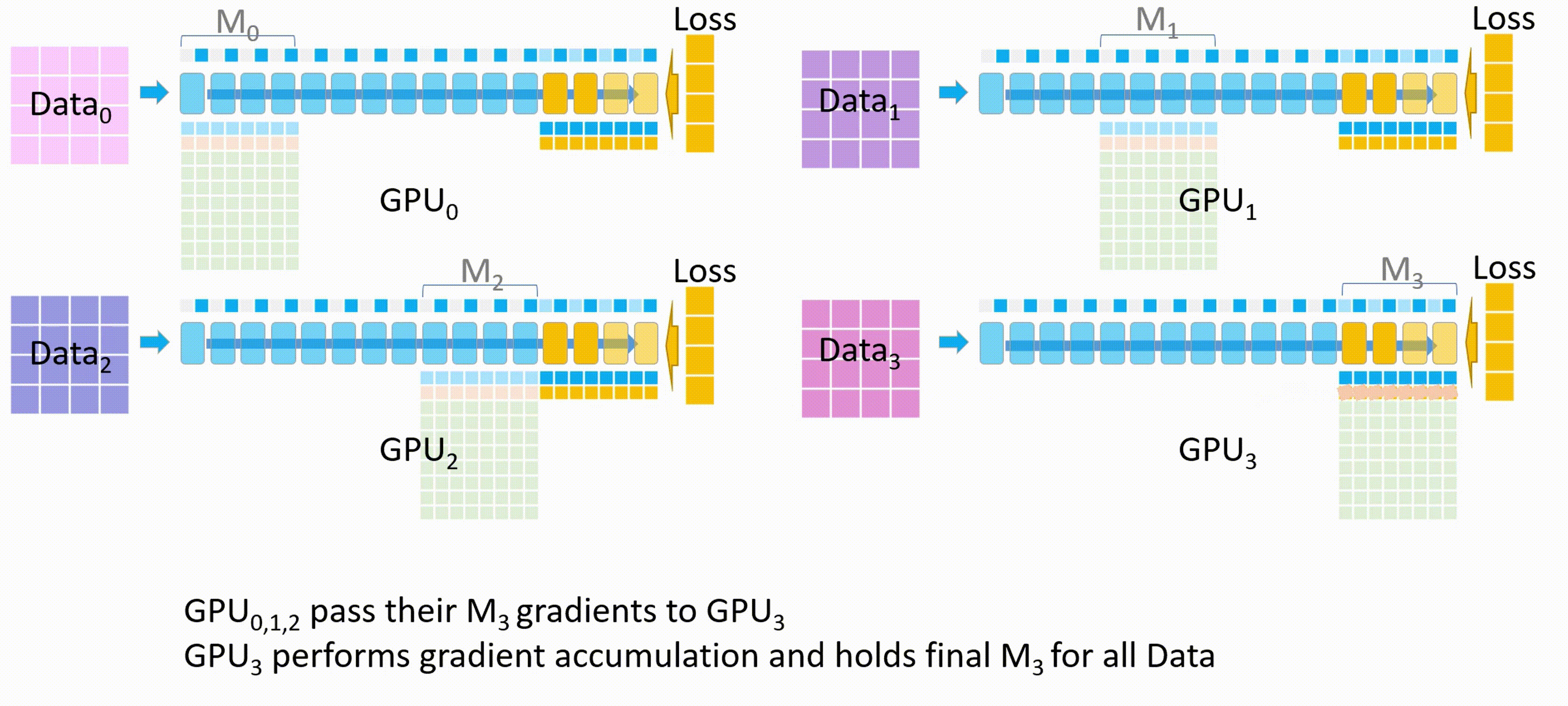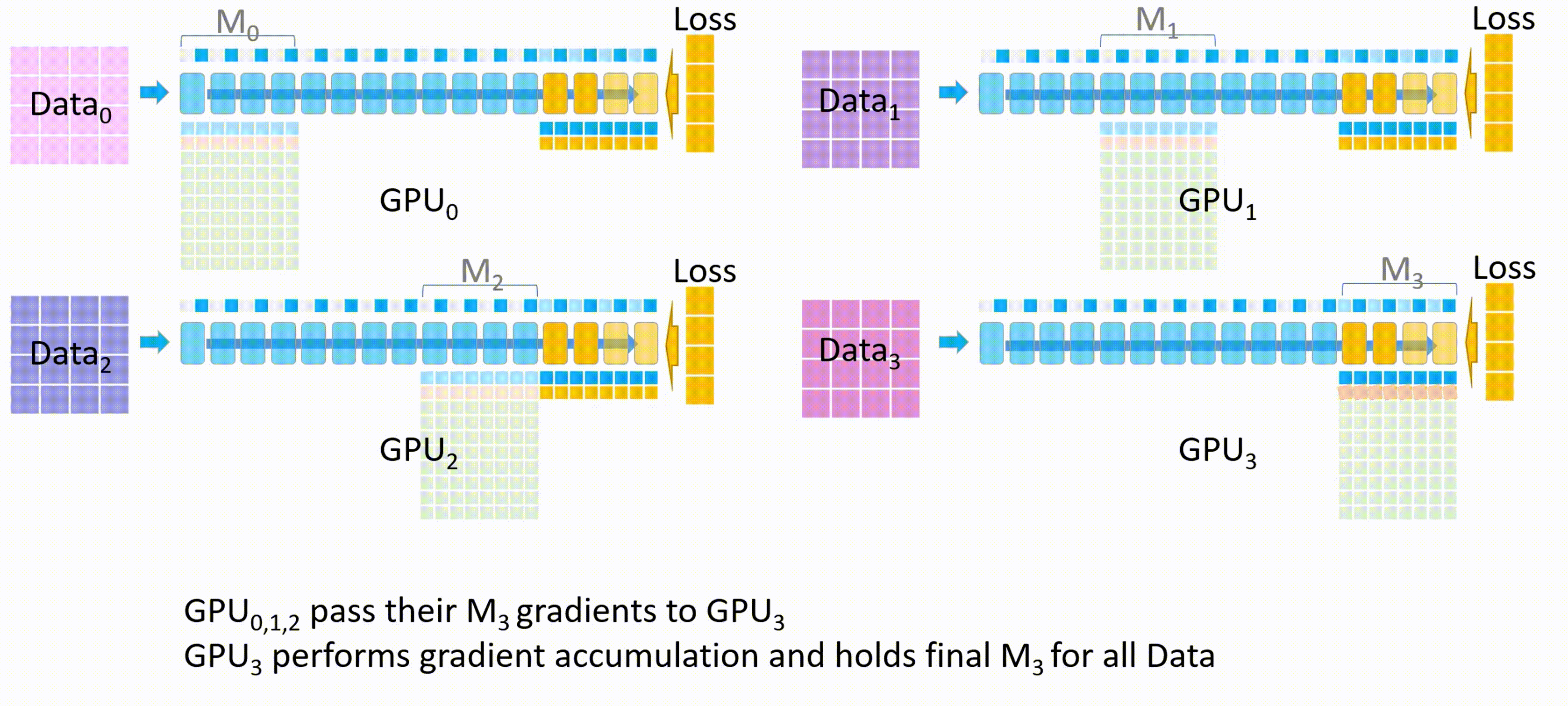
-
其他GPU删除临时存储的\(M_3\)权重参数和梯度,所有GPU都删除\(M_3\)的激活值
-
GPU_2 发送\(M_2\)参数到其他GPU,以便它们进行反向传播并计算梯度
-
以此类推,直到每个GPU上自己部分的模型参数都更新完。
-
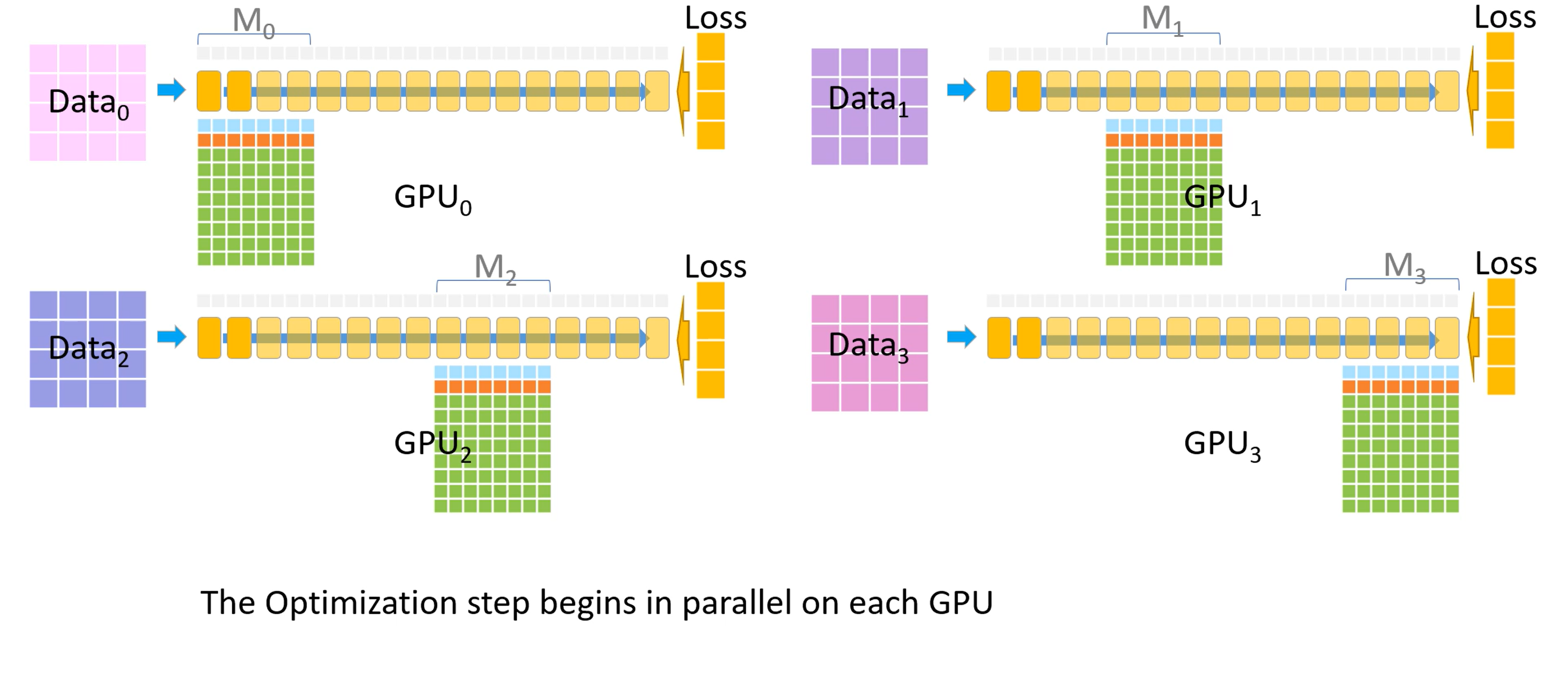
现在每个GPU都有自己的梯度了,开始计算参数更新
-
优化器部分在每个GPU上开始并行
-
优化器会生成FP32精度的模型权重,然后转换至FP16精度
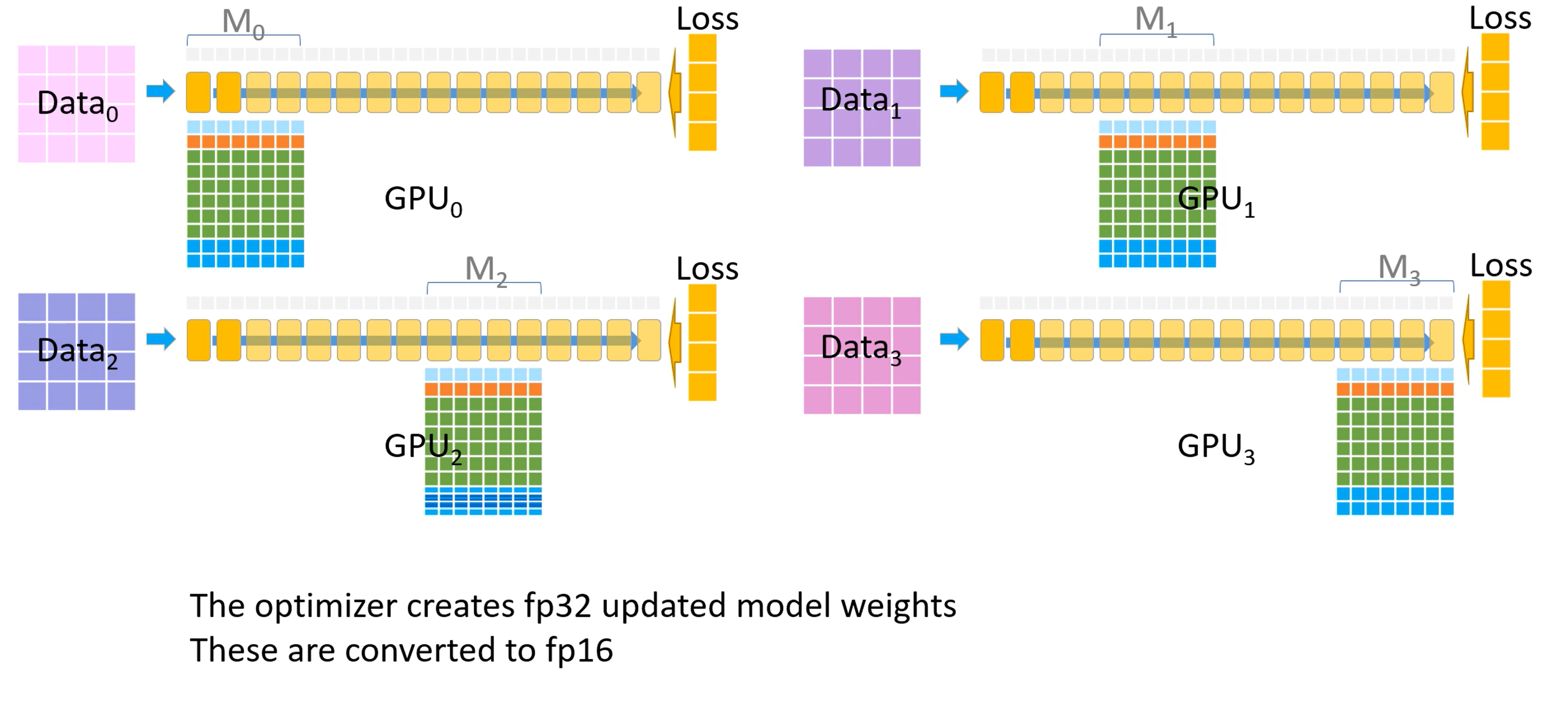
-
FP16精度的权重成为了下一个迭代开始时的模型参数,至此一个训练迭代完成。
整个流程视频如下:
下面来看下ZeRO-3在DeepSpeed中的具体实现思路和方式:
探索一下 ZeRO-3 是如何实现Model Parameter分布式存储的
初始化:分割 & 收集机制 -> submodule收集 -> submodule释放
1. 初始化 - 模型参数分割
参数的分割遵循每个进程雨露均沾的原则
首先,为了防止内存爆照,巨大的Model Parameters 必须在加载之间就被拆分并打道各个进程中。
ZeRO-3 在模型初始化就通过class Init 对其进行了分摊和切割。
python model = zero.Init(module=model)
zero.Init()初始化过程中对传入的module做了如下四步:
- 1、判定传入ZeRO-3 的module 非None
- 2、在一个for loop中,便利其下submodule中的所有参数
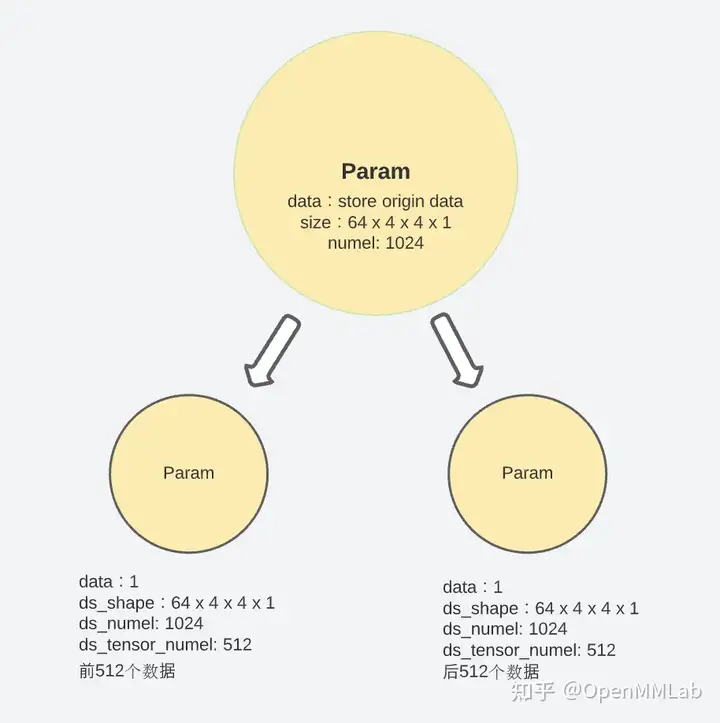
- 3、在tensor的data 分割改变之前,对每一个Parameter tensor套一层
_convert_to_deepspeed_param的马甲用于记录tensor的特征(shape,numel,etc),防止后期因为padding和partition导致原始数据特性的丢失 - 4、参数完成
_convert_to_deepspeed_param之后,param.partition()对其进行均分割并分摊给各个进程
param.partition()中会按照如下步骤进行参数切分:
- 根据进程数量(self.world_size)来计算 parameter partition 之后的 size:
- 创建一个
partition_size大小的空白tensor
partitioned_tensor = torch.zeros(partition_size, dtype=param.dtype, device=self.remote_device)
- 计算partition需要截取和存储的数据区间
start = partition_size * self.rank
end = start + partition_size
- 把原始param拉成一维后,按照进程自己的rank来决定偏移量的start和end,计算出截取的区间并放进partitioned_tensor里,把找个新创建的tensor挂在原始的
param.ds_tensor下
one_dim_param = param.contiguous().view(-1)
src_tensor = one_dim_param.narrow(0, start, partition_size)
param.ds_tensor.copy_(src_tensor)
- 把原始的
param.data减少到1个scalar tensor:
# 因为param.data已经被分散储存在param.ds_tensor下,
# 所以这一部分会将param.data释放掉,修改为只储存一个scalar的形式参数。
# 这也是为什么要通过_convert_to_deepspeed_param的马甲记录下原始信息的原因。
param.data = torch.ones(1).half().to(param.device)
通过以上五个步骤,每个 module 中的参数就被拆分并储存到了不同的进程中,当这一步结束时,原始在param.data长度变为了 1,分段后的参数则放在param.ds_tensor中。
假设有\(N_d\)个GPUs,某一个model parameter的数据量(numel)为T,则其会被para.partition()成\(N_d\)个小数据块分发到\(N_d\)个进程中,每个进程中保持\(T/N_d\) 一小段数据。
在需要重建完成tensor进行计算时,ZeRO-3通过之前记录下 原始 shape、numel等特性对参数进行完整的重构。
2. 初始化 - 模型参数收集初始化
根据每个submodule需求做到更精细化的参数收集与释放
拆分好model parameter 之后,下一步需要考虑的就是如何在需要时快速的找到这些分摊存储的参数,并且重新组合成完整的参数进行运算。参数的收集与释放虽然发生在每次的forward 与 backward中,但需要再初始化就建立好控制信息,针对这个目的,ZeRO-3中创建了另外两个class:class PartitionedParameterCoordinator 和 class PrefetchCoordinator
这两个class 用户负责在forward 和backward时协调modul parameters的获取和释放
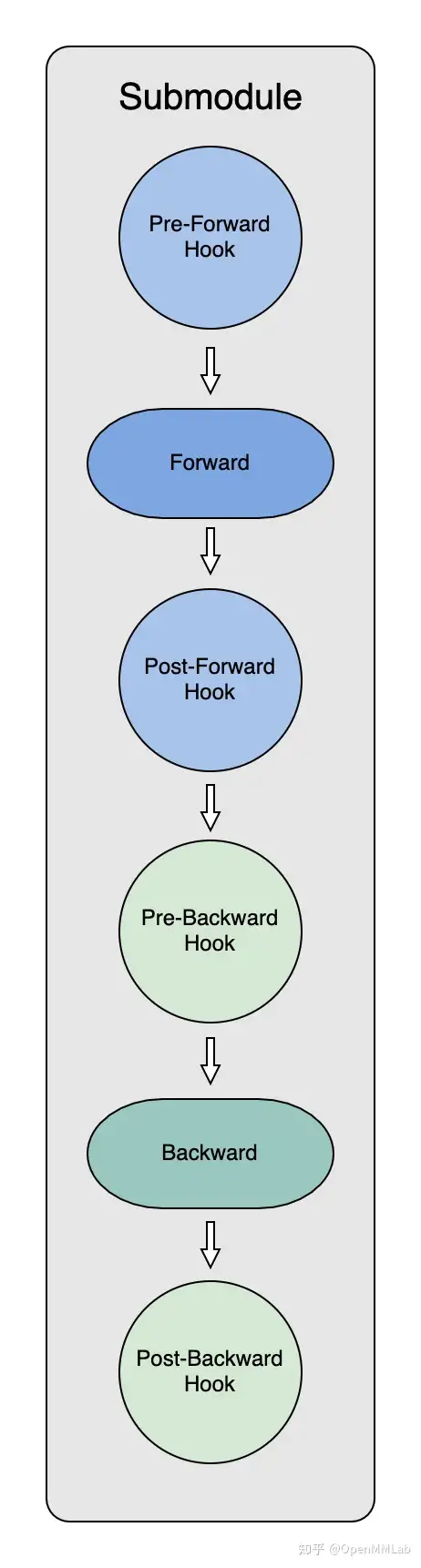
为了能够在模型forward和backward中及时拿到模型参数,ZeRO初始化过程的一个重要环节就是给每个submodule创建 hooks。
首先来一起了解一下 PyTorch 中的 hook。 根据 PyTorch 的文档的介绍:
"You can register a function on a Module or Tensor. The hook can be a forward hook or a backward hook. The forward hook will be executed when a forward call is executed. The backward hook will be executed in the backward phase. "
通过使用hook,可以在保留网络输入输出结构的同时,方便地获取、改变网络中间层变量的值和梯度。
ZeRO-3 Optimizer初始化的过程中,代码通过递归的方式,对module下的每个submodule都挂上了四个 hook:
_pre_forward_module_hook,在submodule的 forward开始前负责 module parameters获取;_post_forward_module_hook,在submodule的forward结束后负责module parameters释放;_pre_backward_module_hook,在submodule的backward开始前负责module parameters获取;_post_backward_module_hook,在submodule的backward结束后负责module parameters释放;
在每个submodule的forward和backward计算前,hook会调用:class PartitionedParameterCoordinator中的fetch_sub_module 和 all_gather 收集重建自己需要的parameter。class PrefetchCoordinator中的prefetch_next_sub_modules则最大化利用通讯带宽,提前all_gather收集到未来submodule需要的parameter,为之后的计算做好准备。
计算完成后,hook 则通过:class PartitionedParameterCoordinator 中的release_sub_module再次释放当前submodule的parameters。
通过这样的方式,在每一个iteration中,各个submodule就可以对自己需要的参数做出计算前的获取和计算后的释放。
3.前向传播中的ZeRO-3
- 前向传播中 Model Parameter 的获取(Pre-Forward Hook)
Pre-Forward Hook
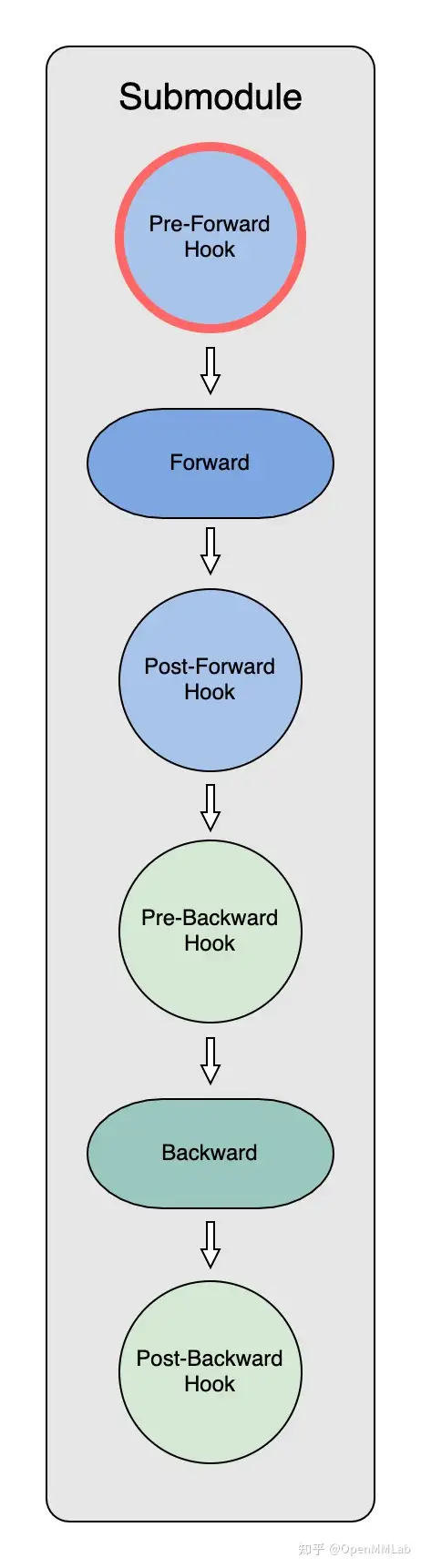
在初始化时,ZeRO-3 Optimizer 把全部module parameter分散partition到了不同的 GPU 上。因此,在每个submodule做forward之前,需要:
- 明确submodule所需要的parameter
- 通过进程间通讯拿到分散储存的partitioned parameter
- 重新构造出原始parameter进行运算
而整个流程都是通过 PartitionedParameterCoordinator 和 PrefetchCoordinator 实现的。
每个submodule在Pre-forward hook中进行了四步操作:
- 1、
param_coordinator.record_trace在第一个iteration时,record_trace会通过param_coordinator记录下一份model的完整运行记录trace,也就是各nn.module的执行顺序。在之后的iteration,运行记录已经创建好了,record_trace就不再发挥作用。 - 2、
param_coordinator.fetch_sub_module因为module forward会逐层进行,当获得submodule的信息后:
- 通过
submodule.named_parameters()收集当前需要的全部partitioned parameters- 通过
all_gather,各个进程中的partitioned parameters会被重新组合构建成原始parameter- 利用原始parameter进行
submodule.forward的计算
-
3、
param_coordinator.prefetch_next_sub_modules为了节省通讯时间,提高效率,Pre-Forward Hook中也会提前预取当前submodule后的submodule的参数,并对其标记以便后续调用。 -
4、
param_coordinator.increment_stepStep会更新当前Submodule在trace中走到了哪一步,从而确定之后prefetch_next_sub_modules的起点。
在最后,经过以上的三步处理,便实现了: -
完成submodule计算所需的所有parameter重建。
-
完成下一个submodule计算的准备。
-
submodule加入most_recent_sub_module_step字典中并做记录。
在第一个iteration后,通过之前创建好的trace,在之后计算过程中按照trace中的顺序,从当前step进行对参数的fetch和eager prefetch。
通过以上完整的四个步骤,就实现了一个submodule在Pre-forward hook中的操作。在实际过程中,因为module可以逐层分成多个submodule,所以整个module的forward过程中会不断的对各submodule重复以上操作。
- 前向传播中 Model Parameter 的分割释放(Post-Forward Hook)
Post-Forward Hook:

当submodule完成正向传播计算后,post_forward_hook会释放掉当前的subomdule,参数也会再次被 partition。但与初始化partition不同的是,此时每个进程中已经有了自己的小段data,所以此时partition只需要把计算前重建的完整大tensor再次释放掉:
# param.data does not store anything meaningful in partitioned state
param.data = torch.ones(1, dtype=self.dtype).to(param.device)
通过这样的方式,每个进程中 submodule 只需要在计算前收集参数,计算后释放参数,从而大大减少了冗余空间占用。
当module所有的submodule都完整正向传播完成后,engine会将记录submodule执行顺序的step_id重新归为0,重新回到整个计算trace最初起点,准备下一次计算流程的开始。
4. 反向传播中的ZeRO-3
- 反向传播中 Model Parameter 的获取(Pre-Backward Hook)
Backward Hooks:
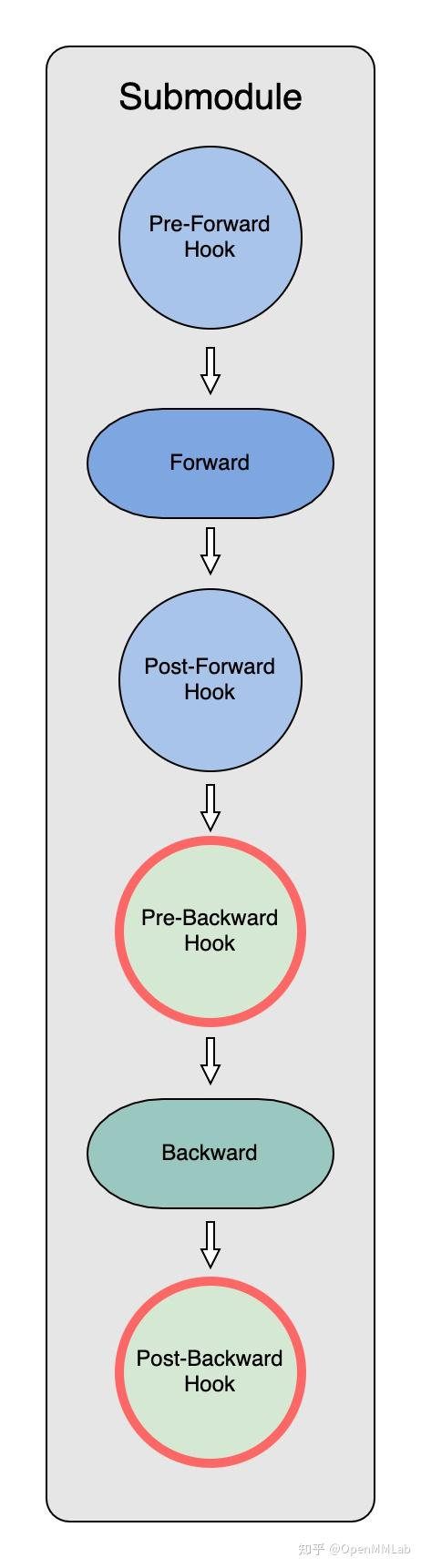
pre-backward_hook也是通过record_trace, fetch_sub_module, prefetch_next_sub_modules和next_step来实现过程的记录、参数的获取,并为下一步准备。
但是,由于 PyTorch 不支持Pre Backward Hook,因此这里得曲线救国一下:使用register_forward_hook挂上一个autograd.Function,这样就可以实现在 module backward 之前执行自定义的操作。在backward前,参数收集和分割的操作通过torch.autograd.Function挂在了各个submodule的tensor上。
当该tensor反向传播计算时,autograd的backward会调用ctx.pre_backward_function(ctx.module)依次完成:
-
1
record_trace -
2
fetch_sub_module -
3
prefetch_next_sub_modules -
4
next_step
这四步操作也与Pre-Forward Hook中的四步操作一致。 -
反向传播中 Model Parameter 的分割释放(Post-Backward Hook)
当backward结束之后,PostBackward hook中的PostBackward Function也会和post_forward_function一样将parameter释放,从而减少model parameter的空间占用
参考链接:
分布式训练:了解Deepspeed中的ZeRO1/2/3
Optimizer state sharding (ZeRO)

