CUDA简单介绍
并行计算
并行计算(parallel computing)是一种计算形式,它将大的问题分解为许多可以并行的小问题。
并行计算分为:任务并行(task parallel)和数据并行(data parallel)
- 任务并行指多个任务同时执行
- 数据并行指多个数据可以同时处理,每个数据由独立的线程处理
- 数据并行分块方法有:块分(block partitioning)和循环分块(cyclic partitioning)
PS:
块分和循环分块是两种不同的编程技术,用于将代码分成更小的块以提高代码的可读性和可维护性。
- 块分是指将一段代码分成多个块,每个块执行特定的任务。这些块可以是函数、方法或代码块。块分的目的是将代码逻辑分解为更小的部分,使得每个块只负责一个特定的功能。这样做的好处是可以更容易地理解和调试代码,也可以更方便地重用代码。块分还可以提高代码的可读性,因为每个块都有一个清晰的目的和功能。
- 循环分块是指在循环中将一段代码分成多个块,每个块在每次循环迭代时执行一次。循环分块的目的是将循环体内的代码逻辑分解为更小的部分,使得每个块只负责一个特定的功能。这样做的好处是可以更容易地理解和调试循环体内的代码,也可以更方便地重用代码。循环分块还可以提高代码的可读性,因为每个块都有一个清晰的目的和功能,并且可以更容易地理解循环的逻辑。
总结起来,块分和循环分块都是将代码分解为更小的部分的技术,以提高代码的可读性、可维护性和重用性。
块分适用于将整个代码分解为多个功能块,而循环分块适用于将循环体内的代码分解为多个功能块。无论是块分还是循环分块,都可以帮助我们更好地组织和管理代码。
异构计算
异构计算(heterogeneous computing)是对并行计算的延伸,是高性能计算发展的里程碑。
异构计算指在具有多种类型处理器(CPU和GPU)的系统中完成的计算。
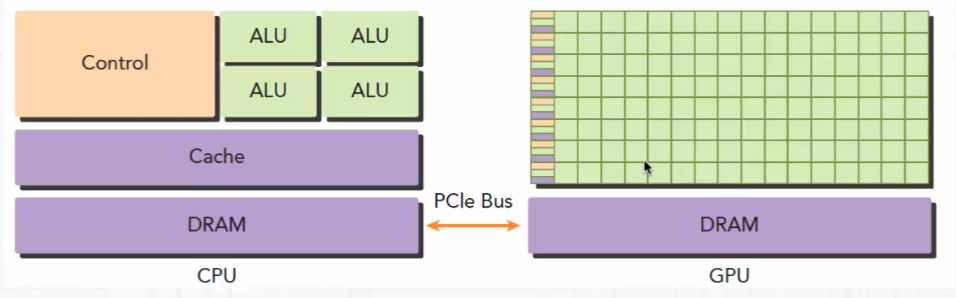
CPU擅长与逻辑处理,GPU擅长数据处理,在通用的异构计算结构中,两者可通过PCIe总线进行连接,使其发挥各自擅长的部分。
在异构计算的程序中,包含了运行在GPU的程序也包含了运行在CPU的程序
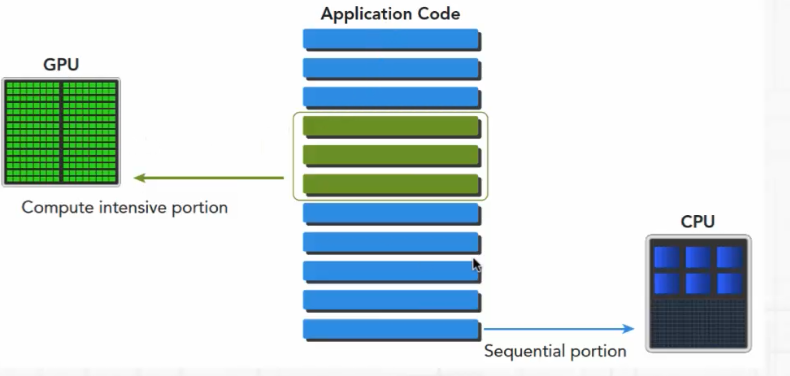
因GPU上有很多线程,因此在GPU上的执行是一个并行的数据处理
GPU性能指标
- GPU核心数(core number)
- GPU内存容量
- 计算峰值
每秒钟单精度或双精度运算能力
- 内存带宽
每秒钟读出或 写入GPU内存的数据量
CUDA
CUDA(Compute Unified Device Architecture)是英伟达公司推出的基于GPU的通用高性能计算平台和编程模型。
可以通过CUDA充分利用英伟达GPU的强大计算能力
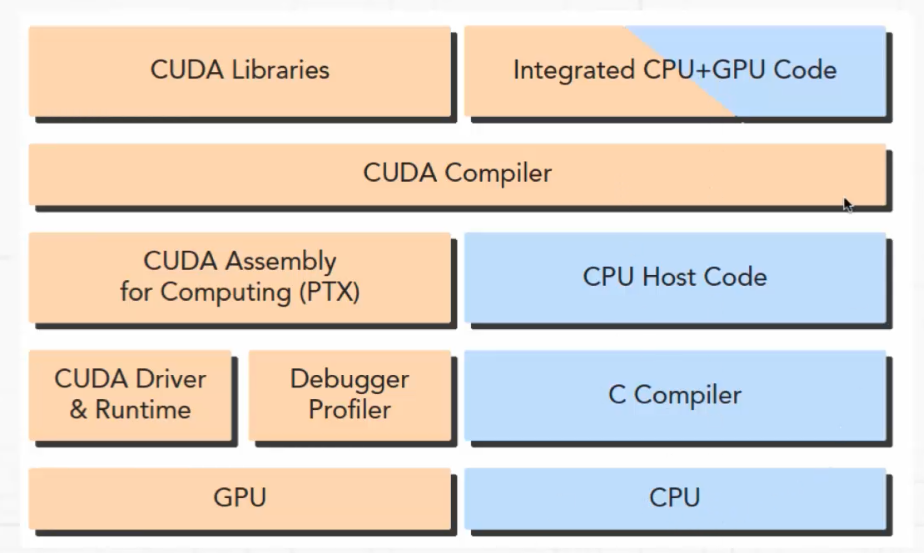
CUDA平台的架构如下图:
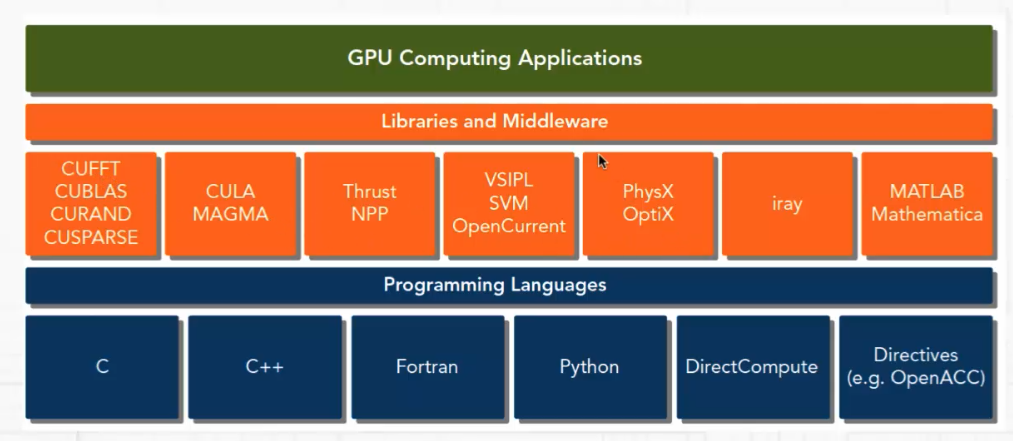
CUDA平台提供了驱动层接口(Driver API)和运行时接口(Runtime API)
基于运行时接口,CUDA的然见架构图如下:
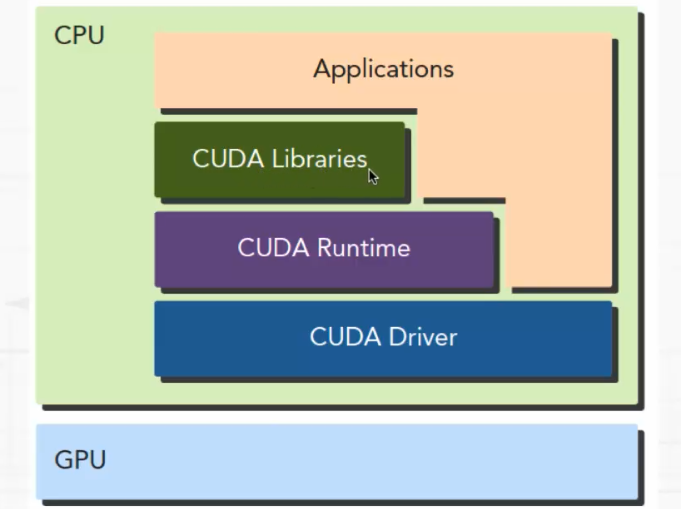
基于CUDA平台开发的程序包含了主机代码和设备代码
主机代码:主要执行流程控制或者是业务层控制
设备代码:主要是数据的并行计算
CUDA程序从程序代码层次的架构
PS:
建议:
在对cuda的学习中,要注意或掌握一下几点:
- CUDA C编程时只需要编写程序顺序执行的程序,在程序代码中不需要有多线程的处理。
- 需要深刻理解CUDA平台GPU的内存结构和线程架构,并掌握对其控制和优化方法
掌握CUDA平台的常用性能分析和调优工具:
1.NVIDIA Nsight
2.CUDA-GDB
3.其他一些图形化的性能分析工具
GPU相关的linux命令
查看GPU类型:
lspci | grep -i nvidia

lspci是一个用于显示计算机上PCI设备信息的命令。
uname -m && cat /etc/*release
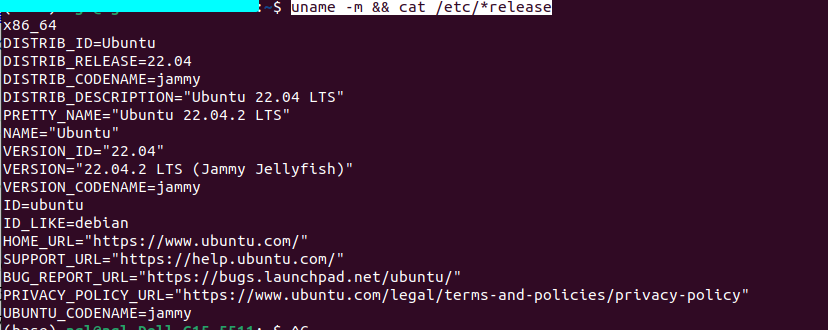
uname -m:这个命令用于获取机器的硬件架构信息。它会返回一个字符串,表示机器的架构类型,比如 x86_64、i686 等。
cat /etc/*release:这个命令用于查看操作系统的发行版信息。/etc/*release是一个文件路径模式,它会匹配所有以 release 结尾的文件。在大多数 Linux 发行版中,这些文件包含了操作系统的版本和其他相关信息。
nvidia-smi -q
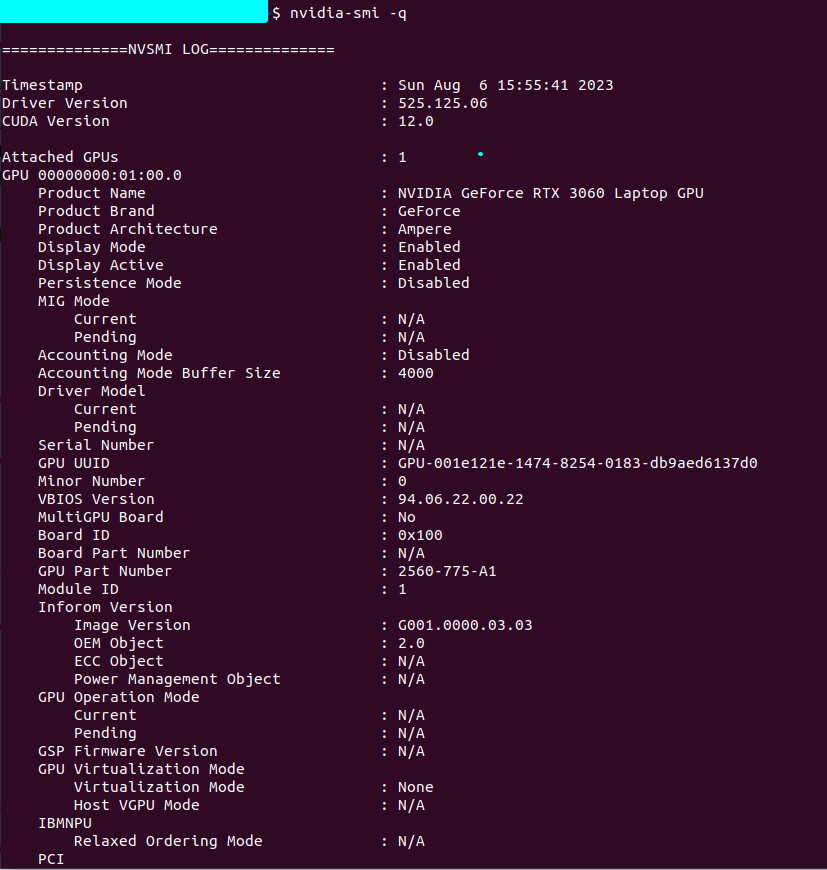
nvidia-smi -q是一个用于查询NVIDIA GPU的命令行工具。它提供了有关GPU硬件和驱动程序的详细信息,包括GPU的型号、驱动程序版本、温度、功耗、内存使用情况等。
nvidia-smi -L

nvidia-smi -L是一个用于显示系统中所有 NVIDIA GPU 设备的命令。它可以帮助您确定系统中有多少个 NVIDIA GPU 设备以及它们的标识符。
当您运行 nvidia-smi -L 命令时,它会返回一个类似于以下格式的输出:GPU 0: GeForce GTX 1080 (UUID: GPU-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx)
GPU 1: GeForce GTX 1060 (UUID: GPU-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx)
每个 GPU 设备都有一个唯一的标识符(UUID),以及一个友好的名称(例如 "GeForce GTX 1080")。通过这些信息,您可以确定系统中有多少个 GPU 设备,并使用它们进行编程或其他操作。
编程模型
编程模型是对底层计算机硬件架构的抽象表达
编程模型作为应用程序和底层架构的桥梁
编程模型体现在程序开发语言和开发平台中
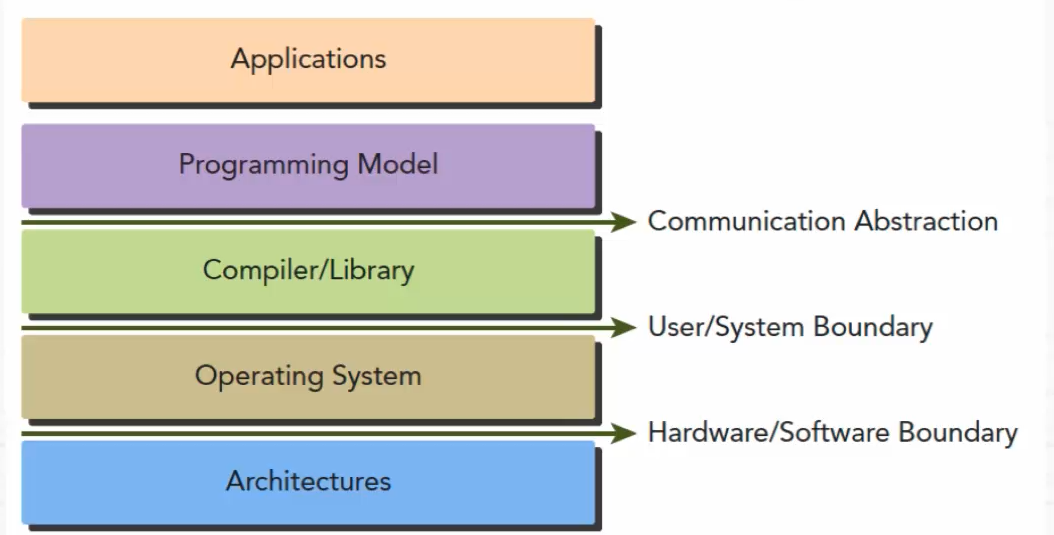
CUDA平台编程模型的特点:
CUDA平台对线程的管理
CUDA 平台提供了线程抽象接口控制GPU中的线程
CUDA平台对内存访问的控制
- 主机内存和GPU设备内存
- GPU和CPU之间内存数据传递
内核函数(kernel function)
- 内核函数本身不包含任何并行性,由GPU协调处理线程执行内核
- CPU 和 GPU处于异步执行状态
运行时GPU信息查询相关API
API接口方法:
获取GPU数量:cudaGetDeviceCount
设置需要使用的GPU:cudaSetDevice
获取GPU信息:cudaGetDeviceProperties

 浙公网安备 33010602011771号
浙公网安备 33010602011771号