
知识蒸馏 -- 简单代码 实现
知识蒸馏
还是先来简单回顾下知识蒸馏的基本知识。
知识蒸馏的核心思想就是:通过一个预训练的大的、复杂网络(教师网络)将其所学到的知识迁移到另一个小的、轻量的网络(学生网络)上,实现模型的轻量化。
目标: 以loss为标准,尽量的降低学生网络与教师网络之间的差异,实现学生网络学习教师网络所教授的知识。
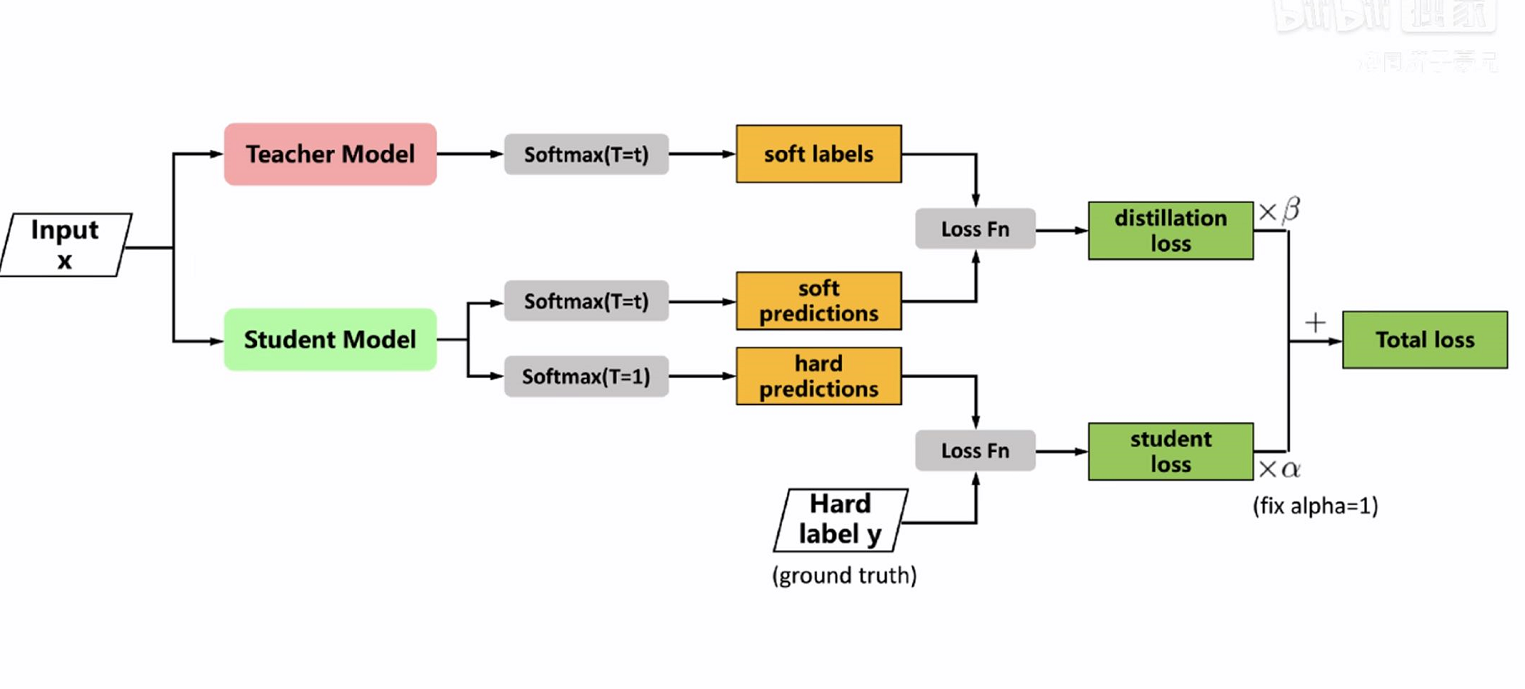
知识蒸馏流程
训练流程如下:
-
1、训练一个Teacher 网络Net-T
-
2、在高温T下,蒸馏 Teacher网络Net-T的知识到学生网络Net-S
高温蒸馏的过程
高温蒸馏过程的目标函数由distill loss(对应soft target)和student loss(对应hard target)加权得到。
示意图如下:
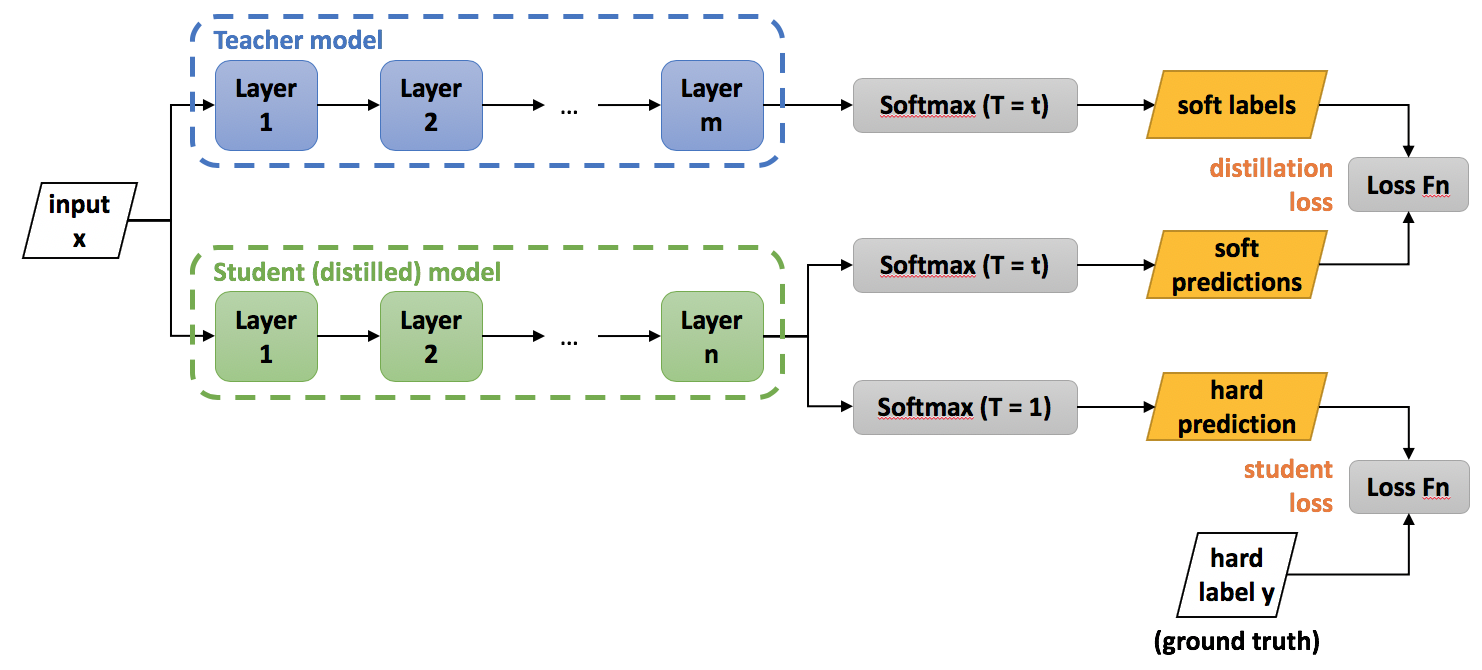
Net-T和Net-S同时输入transfer set(这里可以这里可以直接复用训练Net-T用到的training set),用Net-T产生的softmax distribution(with high temperature)来作为soft target
Net-S在相同温度T条件下的softmax输出和soft target的cross entropy就是Loss函数的一部分\(L_{soft}\)
Net-S在T=1的条件下的softmax输出和ground truth的cross entropy 就是Loss函数的第二部分:\(L_{hard}\)
第二部分Loss必要性其实很好理解:Net-T也有一定的错误率,使用round truth可以有效降低错误被传播给Net-S的可能。打个比方,老师虽然学识远远超过学生,但是他仍然有出错的可能,而这时候如果学生在老师的教授之外,可以同时参考到标准答案,
【注意】
在Net-S训练完毕后,做inference时其Softmax的温度T要恢复到1
其中,$q_j^l = \frac{exp(z_i)}{\sum_k^Nexp(z_k)} $
\(v_i:\)Net-T的logits
\(z_i:\)Net-S的logits
\(p_i^T:\)Net-T在温度T下的softmax输出的第i类上的值
\(q_i^T:\)Net-S在温度T下的softmax输出的第i类上的值
\(c_i:\)在第i类上的ground truth值,\(c_i\in{0,1}\),正标签去取1,负标签取0
\(N:\)总标签数量
最后,α和β 是关于\(L_{soft}\) 和 \(L_{hard}\)的权重,实验发现,当 \(L_{hard}\)权重较小时,能产生最好的效果,这是一个经验性的结论。
直接给出结论:\(L_{soft}\) 贡献的梯度大约为 \(L_{hard}\)的\(\frac 1 {T^2}\),因此在同时使用Soft-target和Hard-target的时候,需要在\(L_{soft}\) 的权重上乘以T2的系数,这样才能保证Soft-target和Hard-target贡献的梯度量基本一致。
代码实现
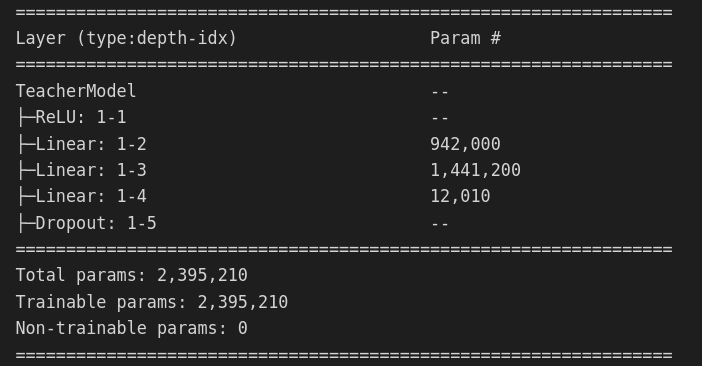
训练教师网络:
# Teacher model
class TeacherModel(nn.Module):
def __init__(self, in_channel=1, num_class=10):
super(TeacherModel, self).__init__()
self.relu = nn.ReLU()
self.fc1 = nn.Linear(784, 1200)
self.fc2 = nn.Linear(1200, 1200)
self.fc3 = nn.Linear(1200, num_class)
self.dropout = nn.Dropout(p = 0.5)
def forward(self, x):
x = x.view(-1, 784)
x = self.fc1(x)
x = self.dropout(x)
x = self.relu(x)
x = self.fc2(x)
x = self.dropout(x)
x = self.relu(x)
x = self.fc3(x)
return x
model = TeacherModel()
model = model.to(device)
summary(model)
# 设置损失函数与优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr = 1e-4)
# 训练
epochs = 6
for epoch in range(epochs):
model.train()
for data, target in tqdm(train_loader):
data = data.to(device)
targets = target.to(device)
# forward
preds = model(data)
loss = criterion(preds, targets)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
num_correct = 0
num_samples = 0
with torch.no_grad():
for x, y in test_loader:
x = x.to(device)
y = y.to(device)
preds = model(x)
predictions = preds.max(1).indices
num_correct += (predictions == y).sum()
num_samples += predictions.size(0)
acc = (num_correct/num_samples).item() # .item() return tensor value
# model.train()
print("Epoch:{}\t Accuracy:{:.4f}".format(epoch+1, acc))
学生网络
# Student Model
class StudentModel(nn.Module):
def __init__(self, in_channel=1, num_class=10):
super(StudentModel, self).__init__()
self.relu = nn.ReLU()
self.fc1 = nn.Linear(784, 20)
self.fc2 = nn.Linear(20, 20)
self.fc3 = nn.Linear(20, num_class)
self.dropout = nn.Dropout(p = 0.5)
def forward(self, x):
x = x.view(-1, 784)
x = self.fc1(x)
# x = self.dropout(x)
x = self.relu(x)
x = self.fc2(x)
# x = self.dropout(x)
x = self.relu(x)
x = self.fc3(x)
return x
techer_model.eval()
model = StudentModel()
model = model.to(device)
model.train()
temp = 10 # 温度
# hard loss
hard_loss = nn.CrossEntropyLoss()
alpha =0.3
# soft loss
soft_loss = nn.KLDivLoss(reduction="batchmean")
optimizer = torch.optim.Adam(model.parameters(), lr = 1e-4)
开始蒸馏
epochs = 3
for epoch in range(epochs):
model.train()
for data, target in tqdm(train_loader):
data = data.to(device)
targets = target.to(device)
# =========================核心=====================================
# teacher model
with torch.no_grad(): # 教师网络不用反向传播
techer_preds = techer_model(data)
# student model forward
student_preds = model(data)
student_loss = hard_loss(student_preds, targets)
ditillation_loss = soft_loss(
F.log_softmax(student_preds/temp, dim = 1),
F.softmax(techer_preds/temp, dim = 1)
)
loss = alpha * student_loss + (1 - alpha) * ditillation_loss * temp * temp # 温度的平方
# ====================================================================
# backward
optimizer.zero_grad() #梯度初始化为0
loss.backward() #反向传播
optimizer.step() #参数优化
model.eval()
num_correct = 0
num_samples = 0
test_loss = 0
with torch.no_grad():
for x, y in test_loader:
x = x.to(device)
y = y.to(device)
preds = model(x)
loss = hard_loss(preds, y)
if device == 'cuda':
loss = loss.cuda()
test_loss += loss.item()
predictions = preds.max(1).indices
num_correct += (predictions == y).sum()
num_samples += predictions.size(0)
acc = (num_correct/num_samples).item() # .item() return tensor value
loss = (test_loss/num_samples)
# model.train()
print("Epoch:{}\t Accuracy:{:.4f} Loss:{:.4f}".format(epoch+1, acc, loss))
这个网络很简单,目的就是理解、学习蒸馏网络具体是如何操作的。
如有需要可登陆Knowledge-Distillation-Zoo github网址,其中实现了不同的知识蒸馏实现方法
备选网址:https://gitee.com/noahj/Knowledge-Distillation-Zoo
https://zhuanlan.zhihu.com/p/444664308
1、log_softmax与softmax的区别在哪里?
softmax把数值压缩到(0,1)之间表示概率,一取对数那值域岂不是(-∞,0)
其实我们在做分类问题时一般用的都是CrossEntropyLoss, 而这个loss下的说明已经说的很清楚了:
This criterion combines nn.LogSoftmax() and nn.NLLLoss() in one single class.
所以,为什么使用log_softmax。 一方面是为了解决溢出的问题,第二个是方便CrossEntropyLoss的计算。所以不需要担心值域的变化。
2、nn.KLDivLoss
作用: 用于连续分布的距离度量;并且对离散采用的连续输出空间分布进行回归通常很有用;用label_smoothing就采用这个;
公式:

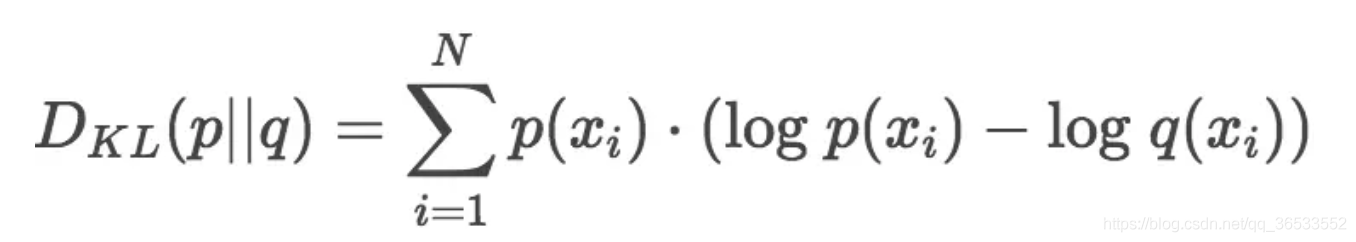
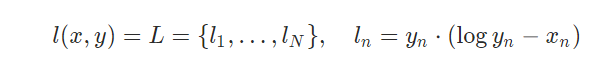

公式理解:
p(x)是真实分布,q(x)是拟合分布;实际计算时;通常p(x)作为target,只是概率分布;而\(x_n\)则是把输出做了LogSoftmax计算;即把概率分布映射到log空间;所以K-L散度值实际是看log(p(x))-log(q(x))的差值,差值越小,说明拟合越相近。
主要参数:reduction:none/sum/mean/batchmean;batchsize是在batchsize维度求平均值;
3、知识蒸馏loss的求解方法
hard label: 训练的学生模型结果与真实标签进行交叉熵loss,类似正常网络训练。
soft label:训练的学生网络与已经训练好的教师网络进行KL相对熵求解,可添加系数,如温度,使其更soft。
知乎回答:loss是KL divergence,用来衡量两个分布之间距离。而KL divergence在展开之后,第一项是原始预测分布的熵,由于是已知固定的,可以消去。第二项是 -q log p,叫做cross entropy,就是平时分类训练使用的loss。与标签label不同的是,这里的q是teacher model的预测输出连续概率。而如果进一步假设q p都是基于softmax函数输出的概率的话,求导之后形式就是 q - p。直观理解就是让student model的输出尽量向teacher model的输出概率靠近。
参考:https://www.cnblogs.com/tangjunjun/p/16028799.html
4、optimizer.step和scheduler.step
那么为什么optimizer.step()需要放在每一个batch训练中,而不是epoch训练中,这是因为现在的mini-batch训练模式是假定每一个训练集就只有mini-batch这样大,因此实际上可以将每一次mini-batch看做是一次训练,一次训练更新一次参数空间,因而optimizer.step()放在这里。
scheduler.step()按照Pytorch的定义是用来更新优化器的学习率的,一般是按照epoch为单位进行更换,即多少个epoch后更换一次学习率,因而scheduler.step()放在epoch这个大循环下。

