延迟分配:提供内存利用率的三种机制
为了提供内存利用率,有一些奇妙的机制,本节就来介绍下:写时复制,请求调页和mmap系统调用
写时复制
写时复制,可概括为写时复制是一种计算机编程领域中的优化技术(Copy-on-Write,简称COW)
其核心原理是,如果有多个应用同时请求相同资源,会共同获取相同的指针,指向相同的资源。这个资源或许是内存中的数据,又或许是硬盘中的文件,直到某个应用真正需要修改资源的内容时,操作系统才会真正复制一份该资源的专用副本给该应用,而其他所见的最初资源仍然保持不变,操作系统使得该过程对其他应用都是透明的。
COW的优点:如果应用没有修改该资源,就不会产生副本,因此多个应用只是在读取操作时可以共享同一份资源,从而节省内存空间。
下面来看下实际的Linux系统是如何应用COW的。
Linux下对COW最直接的应用就是fork系统使用,fork是建立进程的系统调用。
在Linux系统中,一个应用调用fork创建另一个应用时,会复制一些当前应用的数据结构,比如task_struct(代表一个运行中的应用)、mm_struct(代表应用的内存)、vm_area_struct(代表应用的虚拟内存空间)、files_struct(应用打开的文件)等等。
但是创建的时候,并不会把当前应用所有占用的内存页复制一份,而是先让新建应用与当前应用共用相同的内存页。只有新建应用或者当前应用中的一个,对内存页进行修改时,Linux 系统才会分配新的页面并进行数据的复制。
举例:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
pid_t pid;
printf("当前应用id = %d\n",getpid());
pid = fork();
if(pid > 0){
printf("这是当前应用,当前应用id = %d 新建应用id = %d\n", getpid(), pid);
}else if(pid == 0){
printf("这是新建应用,新建应用id = %d\n", getpid());
}
return 0;
}
fork 代表分叉。这里 fork 以应用 A 为蓝本,复制出应用 B。因为当 fork 返回之前,系统中已经存在应用 A 和应用 B 了,所以应用 A 会从 fork 返回,应用 B 也会从 fork 返回。对于应用 A,fork 返回的是应用 B 的 ID;对于应用 B,fork 返回的是 0,系统通过修改应用 B 的 CPU 上下文数据,就能做到这一点。而 getpid 返回的是调用它的应用的 ID。
运行结果如下:
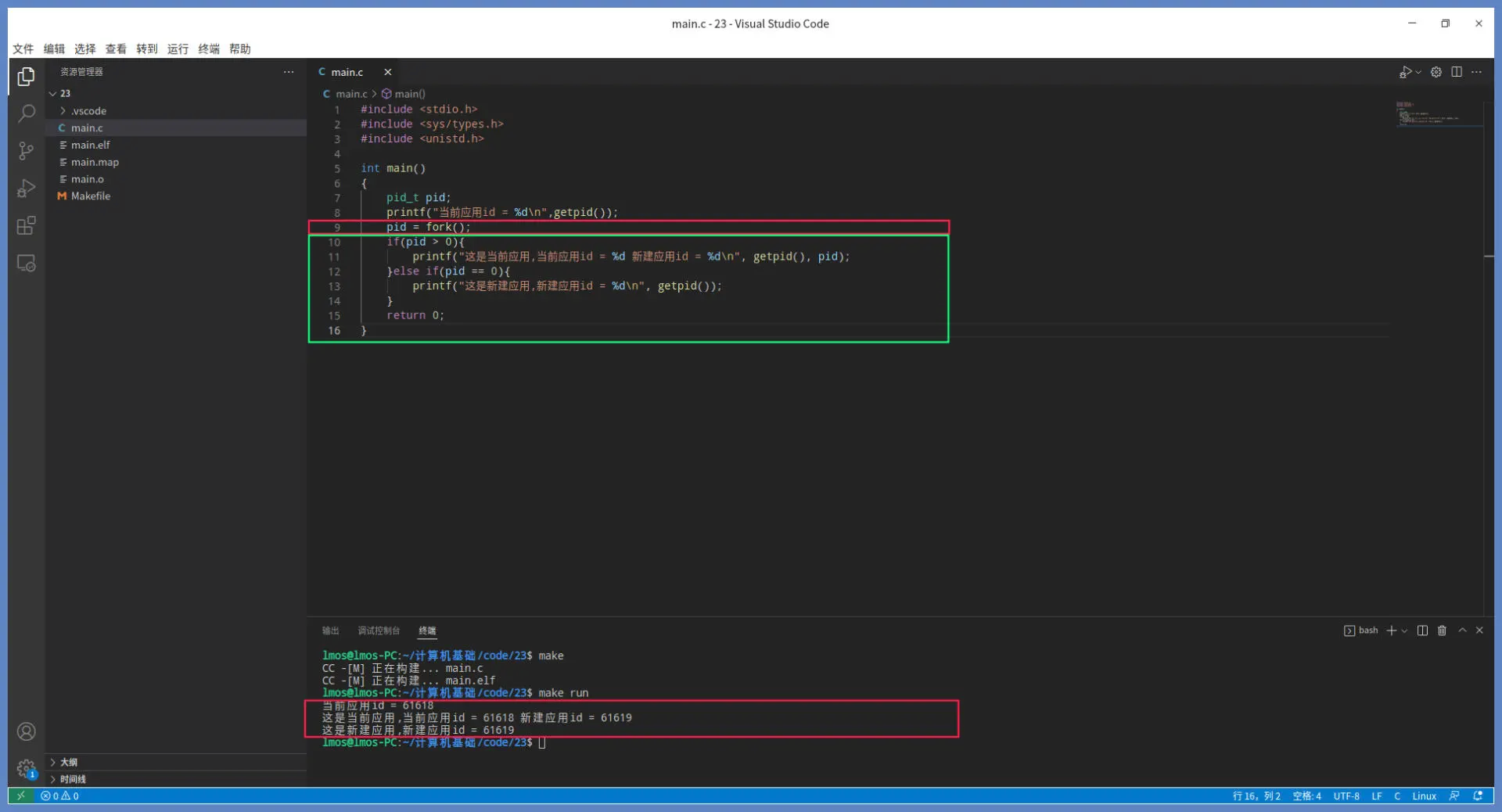
图中绿色部分是应用 A 和应用 B 都会运行的代码片段。应用A调用fork返回的pid与应用B调用getpid返回的pid,是完全一样的,这验证了之前对fork的描述。
只不过第一个 printf 函数来自于应用 A 的运行,而第二个 printf 函数来自应用 B 的运行,为什么会出现这种情况呢?
这就是 fork 的妙处了,fork 会复制应用 A 的很多关键数据,但不会复制应用 A 对应的物理内存页面,而是要监测这些物理内存的读写,只有这样才能让应用 A 和应用 B 正常运行。
该过程可参考下图:
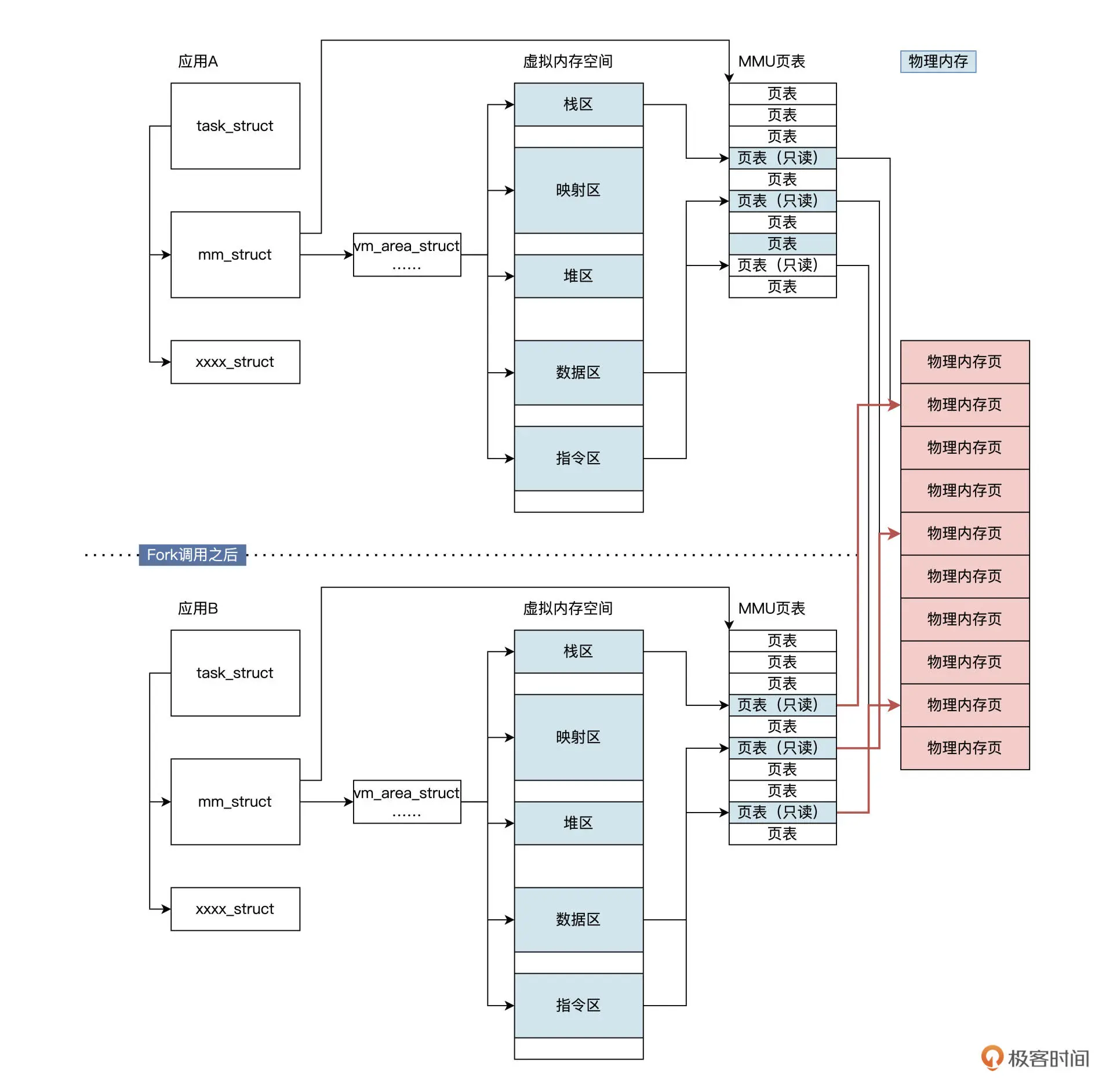
fork 把应用 A 的重要数据结构复制了一份,就生成了应用 B。有一点很重要,那就是应用 A 与应用 B 的页表指向了相同的物理内存页,并对其页表都设置为只读属性。
可能会想"这不是相当于共享内存了吗?",这样想对也不对,得分成应用写入数据和读取数据这两种情况来讨论。
写入数据时,无论是应用A还是应用B去写入数据,这里假定应用B向它的栈区、数据区、指令区等虚拟内存空间写入数据,结果一定是产生MMU转换地址失败。
这是因为对应的页表是只读的,不允许写入。此时MMU会继续通知CPU产生缺页异常中断,进而引起Linux内核缺页处理程序运行起来,然后,缺页处理程序执行完相应的检查,发现问题出在COW机制上,这时候才会把一页物理内存也分配给相应的相应的应用,解除页表的只读属性,并且把应用A对应的物理内存页的数据,复制到新分配的物理内存页中。
该过程可见下图:COW机制过程:
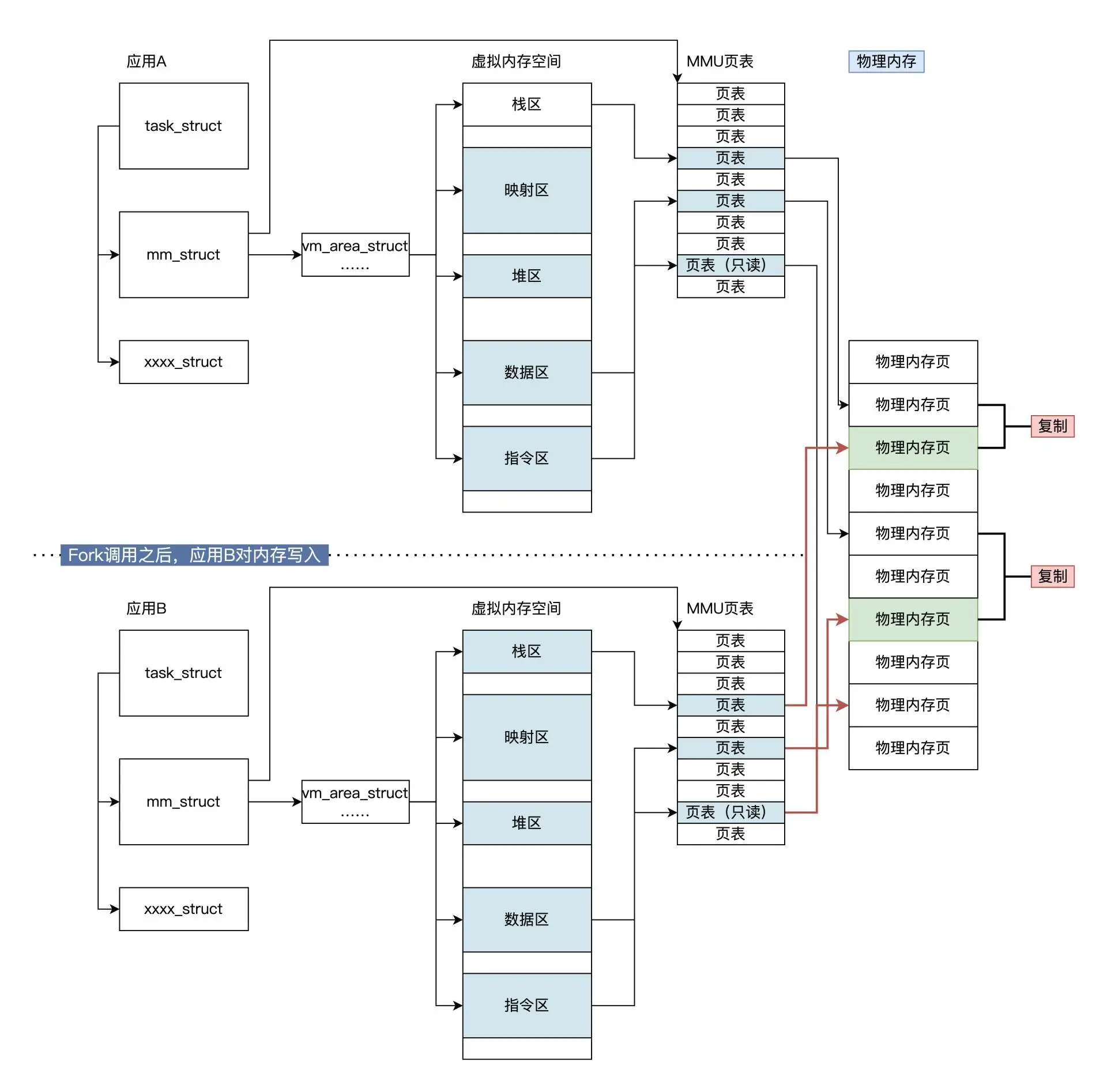
COW 的机制保证了应用最终真正写入数据的时候,才能分配到宝贵的物理内存资源,只要不是写入数据,系统坚决不分配新的内存。
请求调页
请求调页是一种动态内存分配技术,更是一种优化技术,它把物理内存页面的分配推迟到不能再推迟为止。
请求调页之所以能实现,是因为应用程序开始运行时,并不会访问虚拟内存空间中的全部内容。
由于程序的局部性原理,使得应用程序在执行的每个阶段,真正使用的内存页面只有一小部分,对于暂时不用的物理内存页,就可以分配由其他应用程序使用。因此,在不改变物理内存页面数量的情况下,请求调页能够提高系统的吞吐量。
请求调页和写时复制的区别是什么?
当MMU转换失败,CPU产生缺页异常时,在相关页表中请求调页没有对应的物理内存页面,需要分配一个新的物理内存页面,再填入到页表中;
而写时复制有对应的物理内存页面,只不过是只读共享的,也需要分配一个新的物理内存页面填入页表中,并进行复制。
写代码验证下:
int main()
{
size_t msize = 0x1000 * 1024;
void* buf = NULL;
printf("当前应用id = %d\n",getpid());
buf = malloc(msize);
if(buf == NULL)
{
printf("分配内存空间失败\n");
}
printf("分配内存空间地址:%p 大小:%ld\n", buf, msize);
//防止程序退出
waitforKeyc();
return 0;
}
上述代码主要是用 malloc 函数分配了 1000 个页面的内存。这 1000 个页面的内存空间是虚拟内存空间,而 waitforkeyc 函数的作用是让应用程序不要急着退出
可通过sudo cat /proc/55285/smaps > main.smap 命令,观察相应的统计数据。
上述代码运行结果如下:
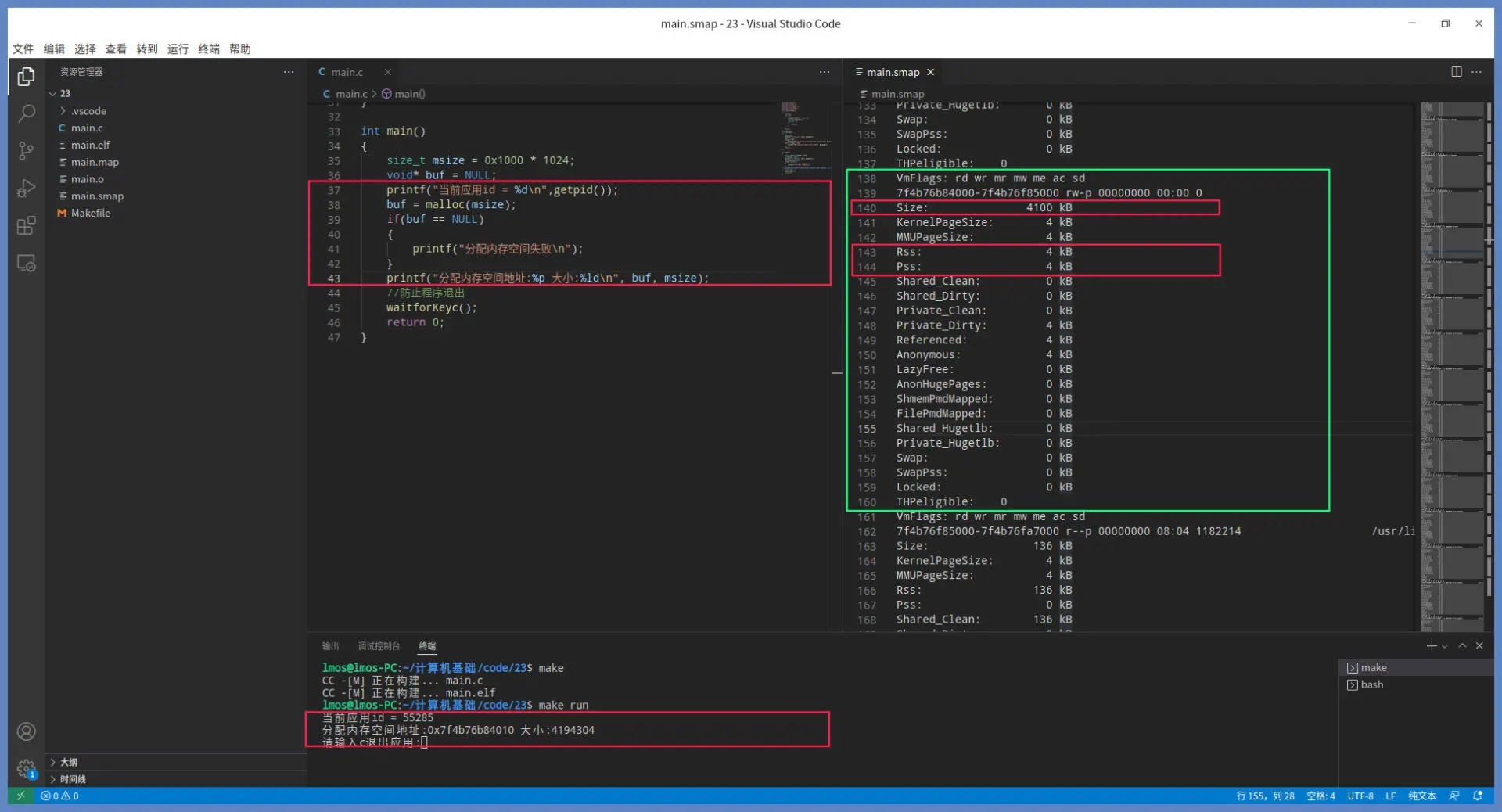
上图绿色方框里就是 malloc 分配的虚拟内存空间。可以看到,这次 malloc 没有在堆中分配,它选择了在映射区分配这个内存空间。绿色方框中 size 为 4100KB,这正是我们分配内存的大小(多出的大小是为了存放管理信息和对齐)。
需要重点关注的是其中的 RSS,它代表的是实际分配的物理内存,这部分物理内存现在已经分配好了,因此使用过程不会产生缺页中断。
同时,RSS 也包含了应用的私有内存和共享内存。我们看到这里已经分配了 4KB,即一个页面。按常理应该分配 1024 个物理内存页面,可是这里才分配了一个页面,这是为什么呢?
把这个问题想清楚,请求调页的原理你就明白了。如果你不向该内存中写入数据,它就不会真正分配物理内存,并且一次只分配一个物理内存页面,当你继续写入下一个虚拟内存页面时,它才会继续分配下一个物理内存页面。
继续验证:
int main()
{
size_t msize = 0x1000 * 1024;
void* buf = NULL;
printf("当前应用id = %d\n",getpid());
buf = malloc(msize);
if(buf == NULL)
{
printf("分配内存空间失败\n");
}
memset(buf, 0xaf, msize);
printf("分配内存空间地址:%p 大小:%ld\n", buf, msize);
//防止程序退出
waitforKeyc();
return 0;
}
代码中加入 memset 函数,用于把 malloc 函数分配的空间全部写入为 0xaf。
运行结果如下:
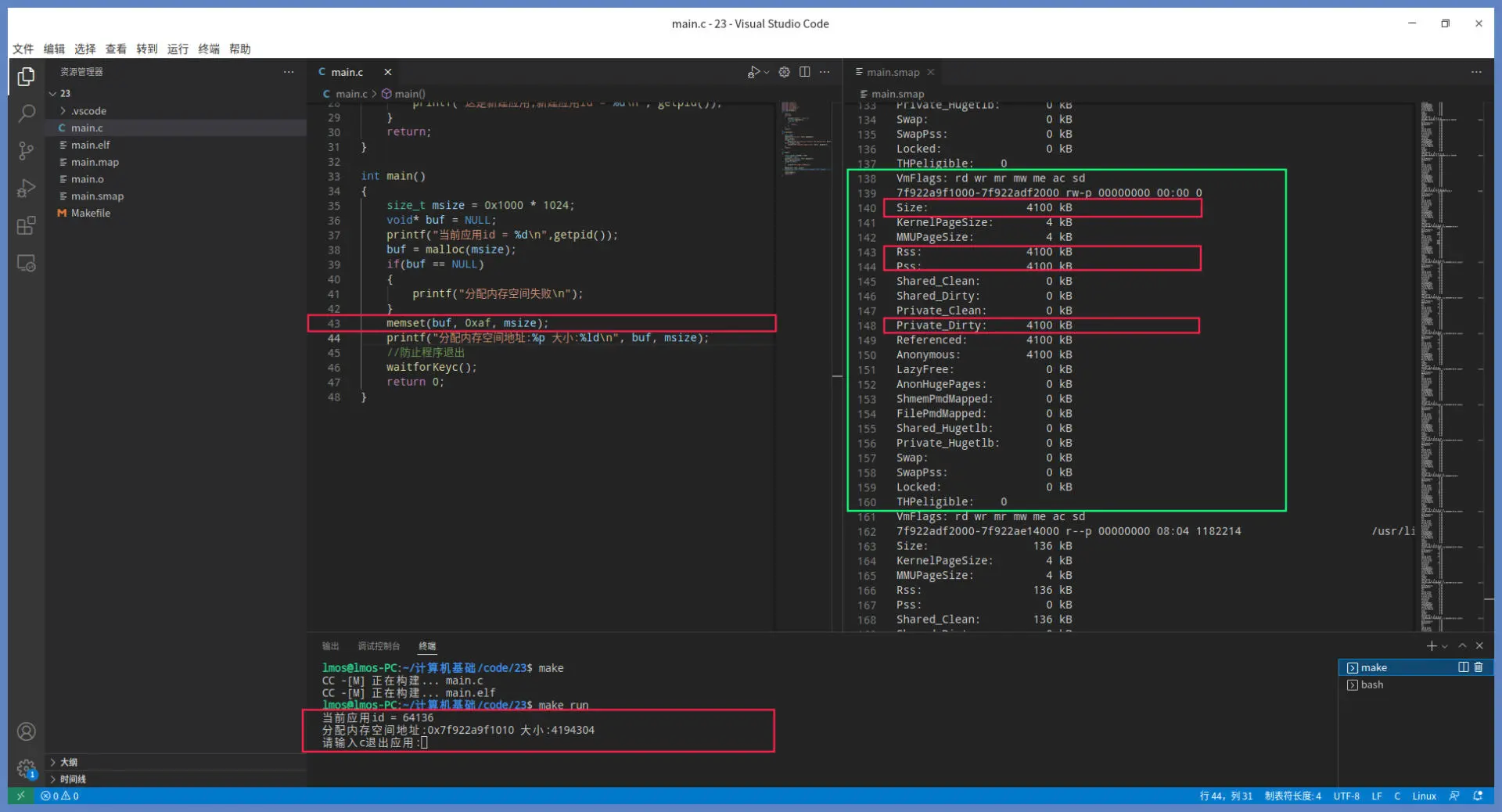
看到绿色方框中的有些数据发生了变化。RSS 代表的应用占用的物理内存,现在变成了 4100KB,而 ** Private_Dirty 代表应用的脏内存(即写入数据的内存)的大小**,也是 4100KB,转换成页面刚好是 1025 个页面。1025 个页,减去 malloc 分配时写入的 1 个页,刚好和我们分配的 1024 页面是相等的。
请求调页是虚拟内存下的一个优化机制。在分配虚拟内存空间时,并不会直接分配相应的物理内存页面,而是由访问虚拟内存引起缺页异常,驱动操作系统分配物理内存页面,将物理内存分配推迟到使用的最后一刻,这就是请求调页。
映射文件
在Linux等通用操作系统中,请求调页还有一个更深层次的应用,即映射文件
一般情况下,我们操作文件要反复调用 read、write 等系统调用。而映射文件的方式能让我们像读写内存一样读写,就是我们只要读写一段内存,其数据就会反映在相应的文件中,这样操作文件就更加方便了。
在 Linux 中有个专门的系统调用,来实现这个映射文件的功能,它就是 mmap 调用。
mmap的函数原型声明:
void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);
参数解释如下:
start:指定要映射的内存地址,一般设置为NULL,以便让操作系统自动分配合适的内存地址。
length:指定映射内存空间的字节数。
prot:指定映射内存的访问权限。可取如下几个值:PROT_READ(可读), PROT_WRITE(可写), PROT_EXEC(可执行), PROT_NONE(不可访问)。
flags:指定映射内存的类型:MAP_SHARED(共享的) MAP_PRIVATE(私有的), MAP_FIXED(表示必须使用 start 参数作为开始地址,如果失败不进行修正),其中,MAP_SHARED , MAP_PRIVATE必选其一,而 MAP_FIXED 则不推荐使用。
fd:指定要映射的打开的文件句柄。
offset:指定映射文件的偏移量,一般设置为 0 ,表示从文件头部开始映射。
mmap内部的原理与机制:
当调用mmap()时,Linux会在当前应用(由task_struct表示)的虚拟内存(mm_struct表示)中,创建一个vm_area_struct结构,让其指向虚拟内存中的某个内存区,并且把其中vm_file成员指向要映射的文件对象(file)
然后,调用文件对象的mmap对象就会对vm_area_struct结构的vm_ops成员进行初始化。接着,vm_ops成员会初始化具体文件系统的相关函数。
这里不需要深入到文件系统,只要明白后面这个逻辑就行:当应用访问这个 vm_area_struct 结构表示的虚拟内存地址时,会产生缺页异常。随即在这个缺页异常的驱动下,最终会调用 vm_ops 中的相关函数,读取文件数据到物理内存页中并进行映射。
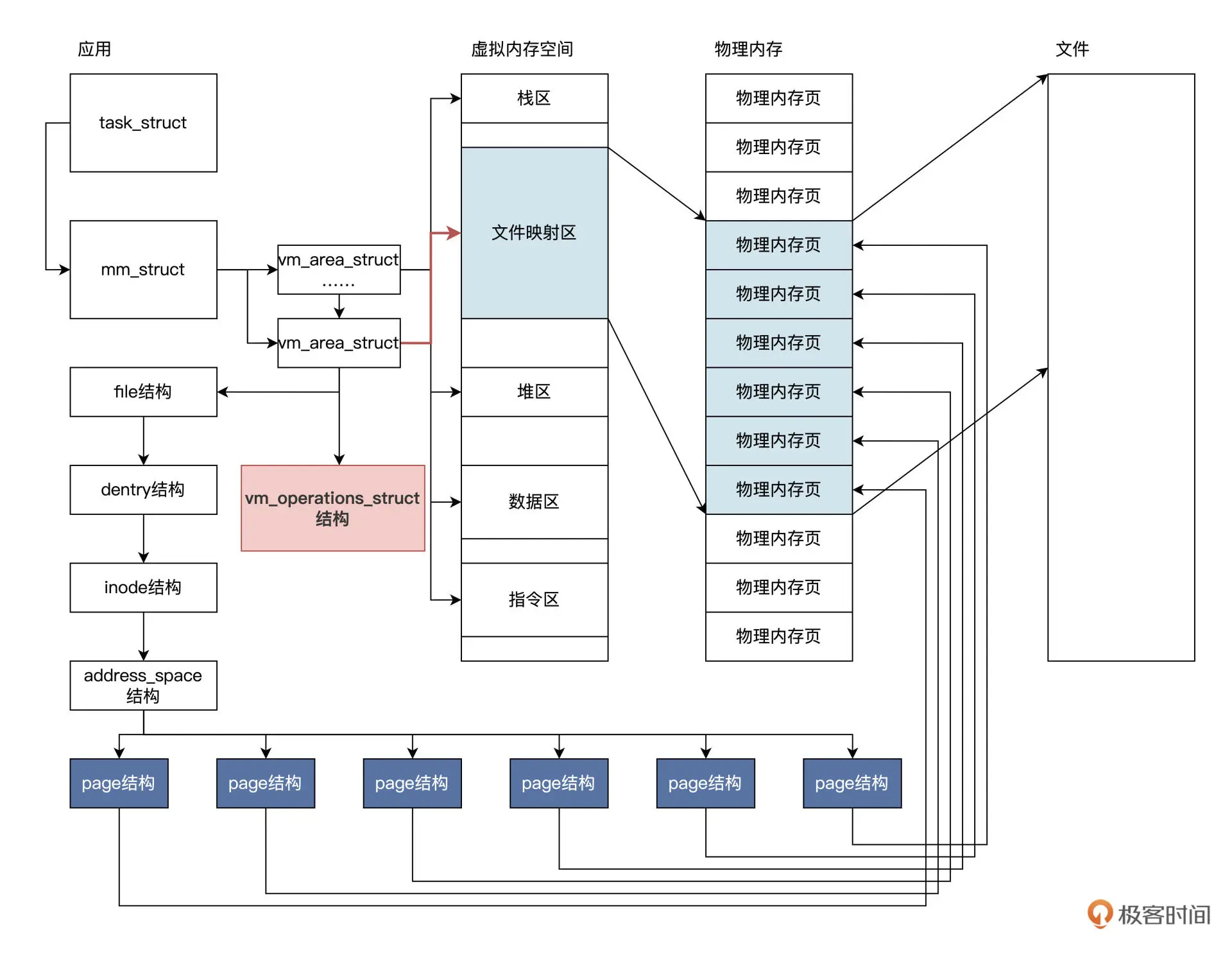
Linux 内核在调用 open 函数打开文件时,会在内存中建立诸如 file、dentry、inode、address_space 等数据结构实例,用来表示一个文件及其文件数据。
有了 open 返回的 fd 文件句柄,mmap 就可以工作了。mmap 调用首先会建立一个 vm_area_struct 结构,表示文件映射的虚拟内存。然后,根据参数 fd 文件句柄,找到打开的文件,即 file 结构,并且让它们关联起来。
最后,应用访问 mmap 函数返回的一个地址,应用程序访问这个地址就会导致缺页异常。在缺页异常处理程序的驱动下,CPU 会找到这个地址对应的 vm_operations_struct 结构,这个结构中封装了大量的虚拟内存操作 。
虚拟内存的操作是什么?
第一次缺页异常处理时,会调用 vm_operations_struct 中的 map_pages 函数,用来给文件分配相应的物理内存页。不过这时虽然有了物理内存页,但里面并没有文件数据,所以内核会在页表上做标记,标记该页不存在于内存里,这样还是会导致缺页异常。
接下来这次异常操作就不同了,这次会调用 vm_operations_struct 结构中的 fault 函数,读取对应的文件数据,并和 address_space 结构联系起来。最终,CPU 就能访问文件的内容,一步步通过前面讲过的请求调页方式,把对应文件的内容加载到物理内存中了。
测试代码:
int main()
{
size_t len = 0x1000;
void* buf = NULL;
int fd = -1;
printf("当前应用id = %d\n",getpid());
//当前目录下打开或者建立testmmap.bin文件
fd = open("./testmmap.bin", O_RDWR|O_CREAT, 777);
if(fd < 0)
{
printf("打开文件失败\n");
return 0;
}
//建立文件映射
buf = mmap(NULL, len, PROT_READ|PROT_WRITE, MAP_PRIVATE, fd, 0);
if(buf == NULL)
{
printf("映射文件失败\n");
return 0;
}
printf("映射文件的内存地址:%p 大小:%ld\n", buf, len);
//防止程序退出
waitforKeyc();
return 0;
}
上述代码中先调用 open 函数,这个函数带有 O_CREAT 标志,表示打开一个 testmmap.bin 文件,若文件不存在,就会新建一个名为 testmmap.bin 的文件。接着会调用 mmap 函数建立文件映射,虚拟内存区间由操作系统自动选择,长度为 4KB,该区间可以读写,而且是私有的,从文件头开始映射。 请注意,这里我们没有对文件映射区进行任何操作。
查看对应进程的smaps文件信息,如下所示:
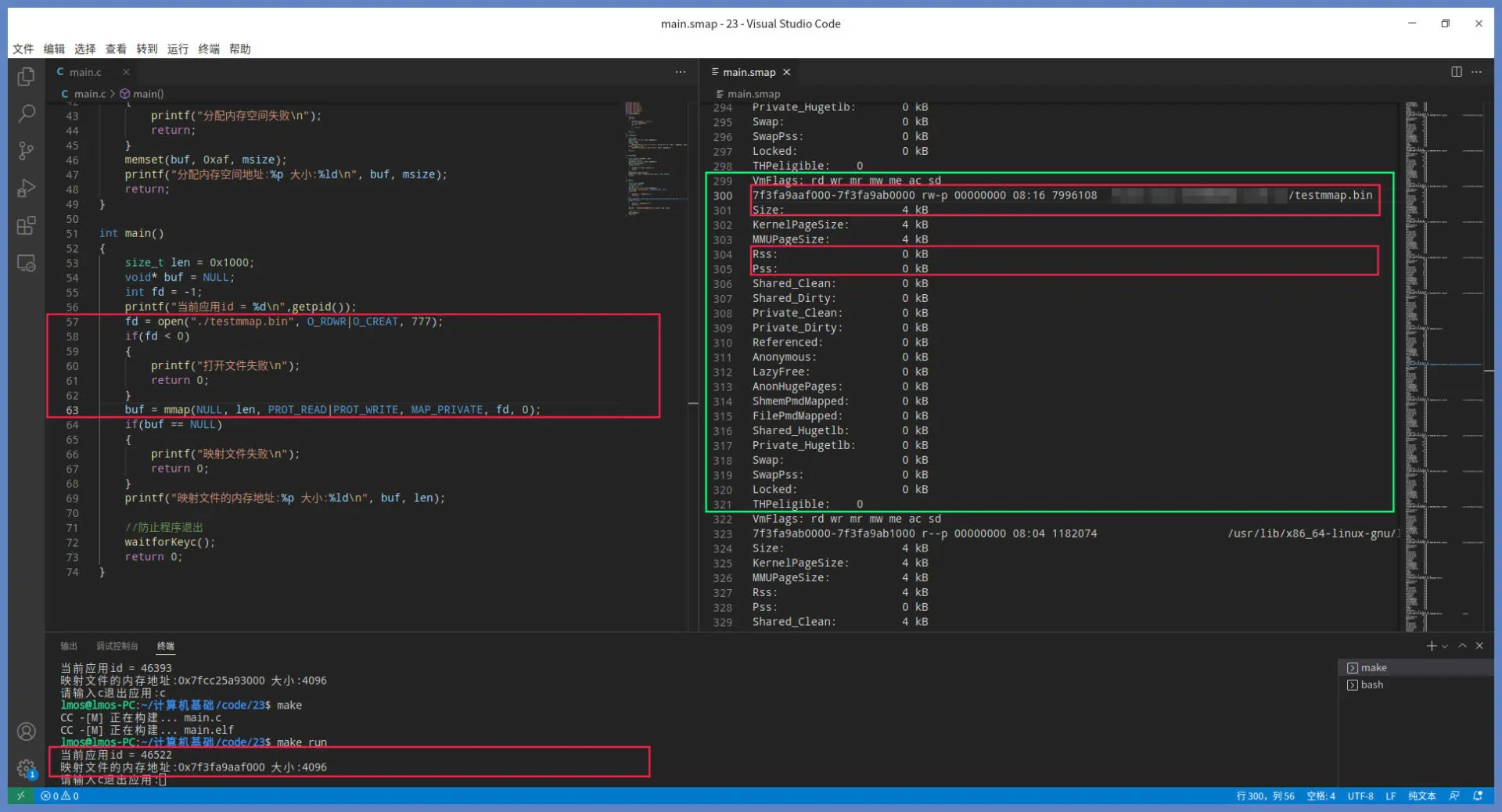
mmap 返回的地址是 0x7f3fa9aaf000,大小为 4KB。对照右边绿色方框中的信息,刚好吻合。其中 RSS 为 0,说明此时没有分配物理内存,因为我们没有这个虚拟内存区间做任何操作。
往虚拟内存区间写入数据,代码如下:
int main()
{
size_t len = 0x1000;
void* buf = NULL;
int fd = -1;
printf("当前应用id = %d\n",getpid());
fd = open("./testmmap.bin", O_RDWR|O_CREAT|O_TRUNC, S_IRWXU|S_IRWXG|S_IRWXO);
if(fd < 0)
{
printf("打开文件失败\n");
return 0;
}
//因为mmap不能扩展空文件,空文件没有物理内存页,所以先要改变文件大小,否则会产生总线错误
ftruncate(fd, len);
buf = mmap(NULL, len, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0);
if(buf == NULL)
{
printf("映射文件失败\n");
return 0;
}
printf("映射文件的内存地址:%p 大小:%ld\n", buf, len);
//向文件映射区间写入0xff
memset(buf, 0xff, len);
close(fd);
//防止程序退出
waitforKeyc();
return 0;
}
和前面代码相比,这里我们只是增加了扩展文件大小的功能,接着 mmap 文件,最后调用 memset 函数文件映射区的虚拟内存地址 buf 处,写入 0x1000 个 0xff。
运行结果如下:
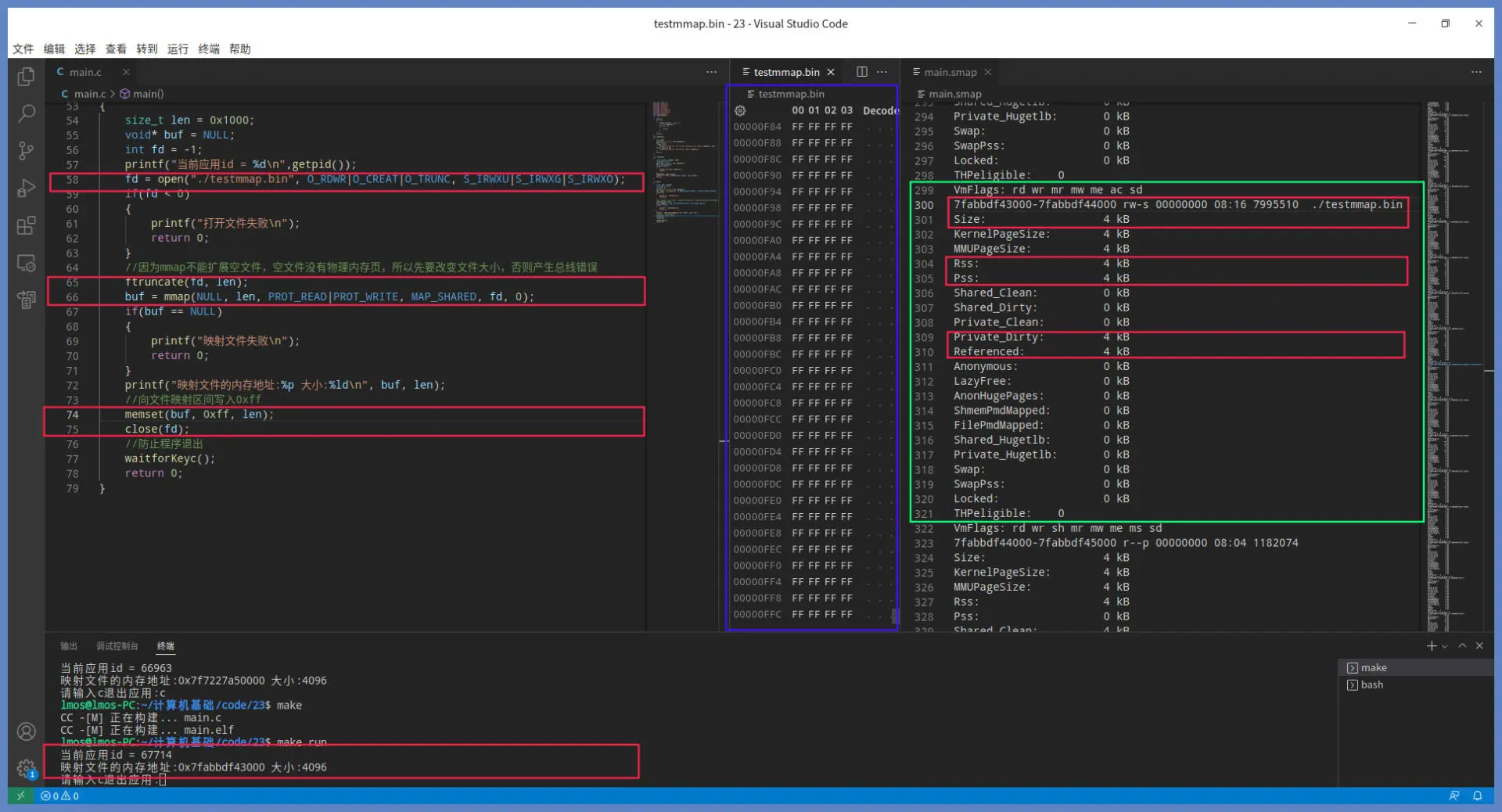
对比前一张图,我们可以看出绿色方框的 RSS 中,Private_Dirty 的数据有所变化。这是因为 memset 函数写入数据导致缺页异常,从而分配物理内存页并关联到 testmmap.bin 文件。当 close 函数被调用时,物理内存页中的数据就会同步到硬盘中。我们可以打开 testmmap.bin 文件查看一下,即上图中蓝色方框中的数据。
mmap 函数的底层原理就是对请求调页的扩展。这种方式在处理超大文件的随机读写过程中,性能相当不错。当只有文件中一部分被读写的时候,就不必读取整个文件,占用大量内存了。
对内存资源“精打细算”的操作系统通过文件映射的机制,让物理内存页的分配管理更加精细了,等到应用实际要用到文件的哪一部分,系统才会去分配真正的物理内存。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号