
编译原理:编译过程概述
编译原理概述
编译,就是一个把源代码变成目标代码的过程。
如果源代码编译后直接在操作系统上运行,那目标代码就是汇编代码,再通过汇编和链接的过程形成可执行文件,然后通过加载器加载到操作系统里执行
如果编译后在解释器中执行,那目标代码就可以不是汇编代码,而是一种解释器可以理解的中间形式的代码即可。
编译的各个阶段图示:
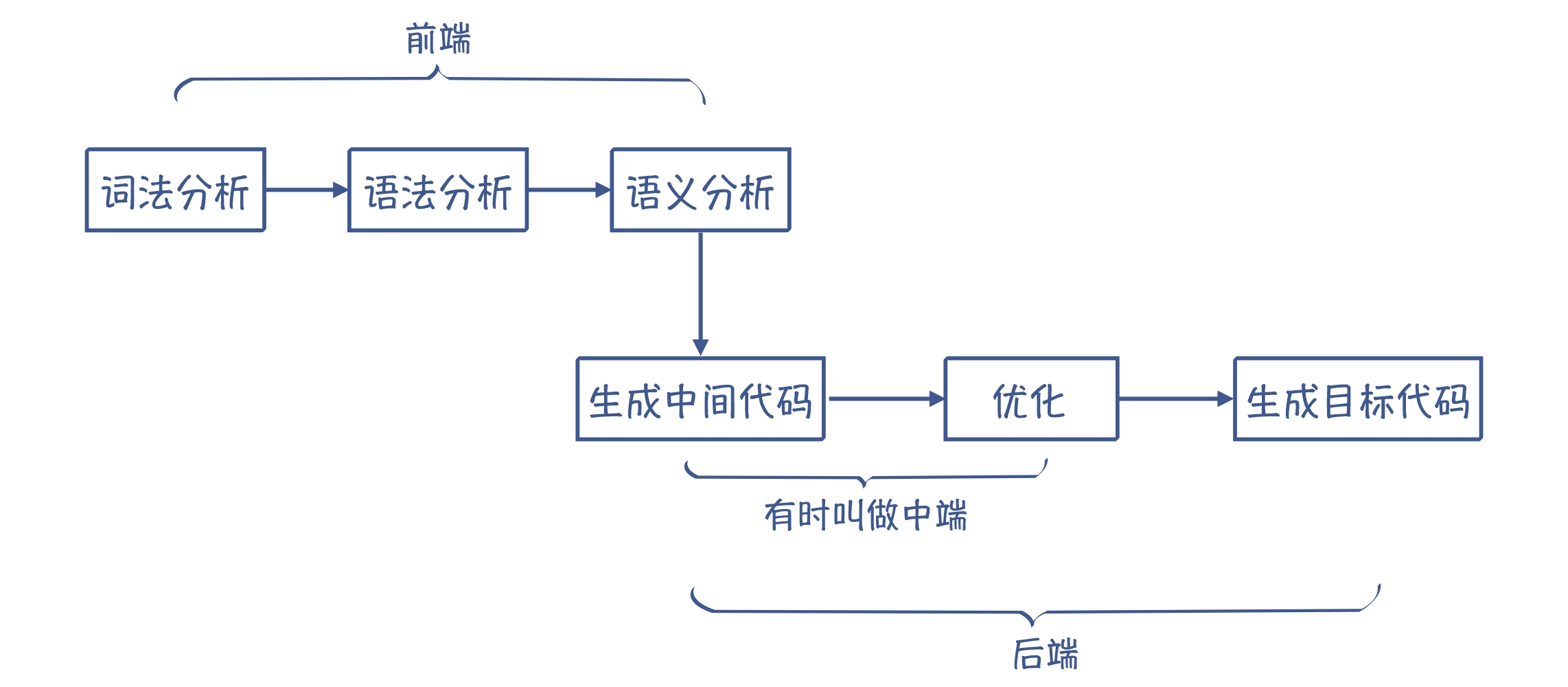
-
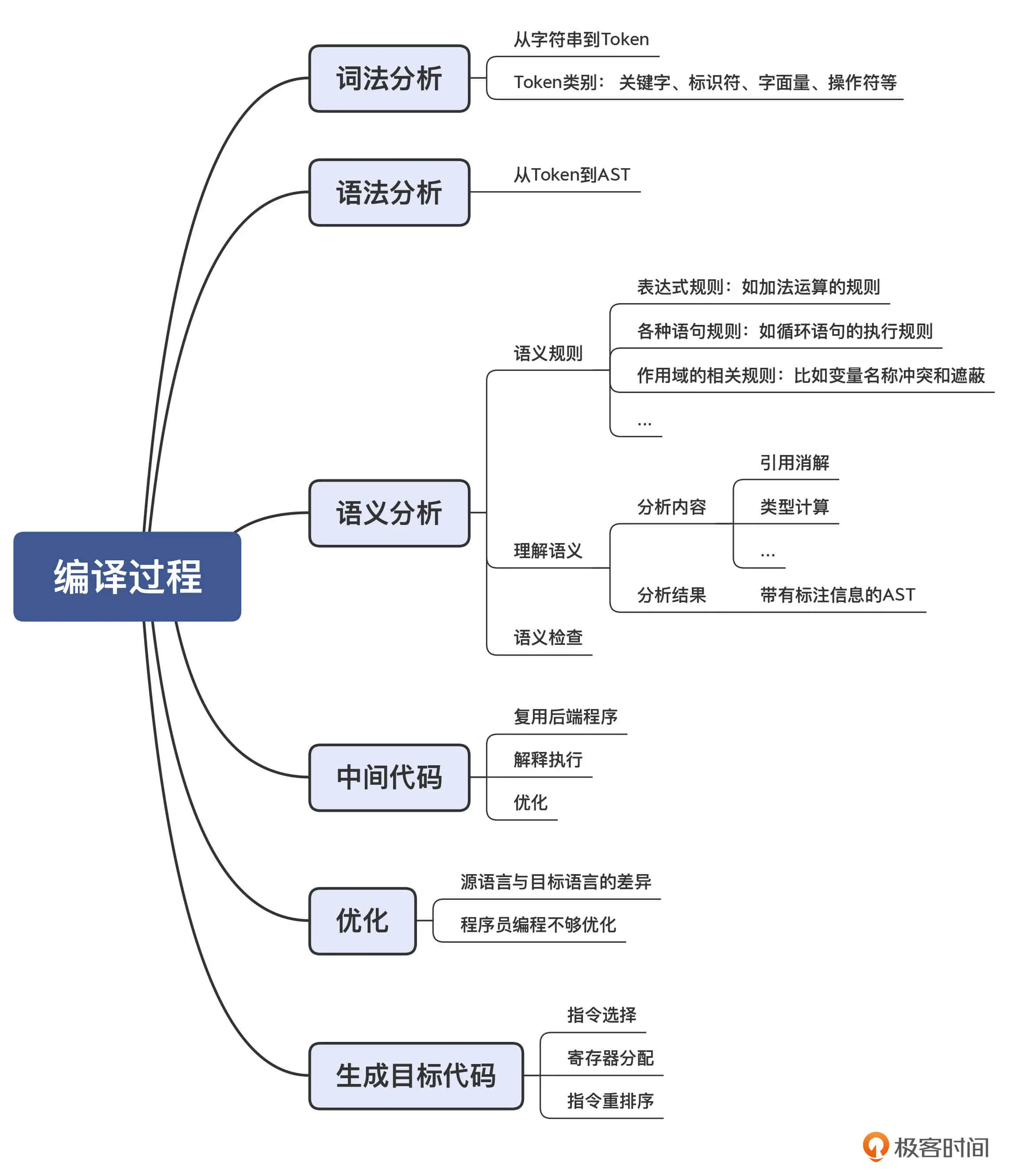
词法分析(Lexical Analysis)
将字符串转换为Token的这个过程就叫做词法分析
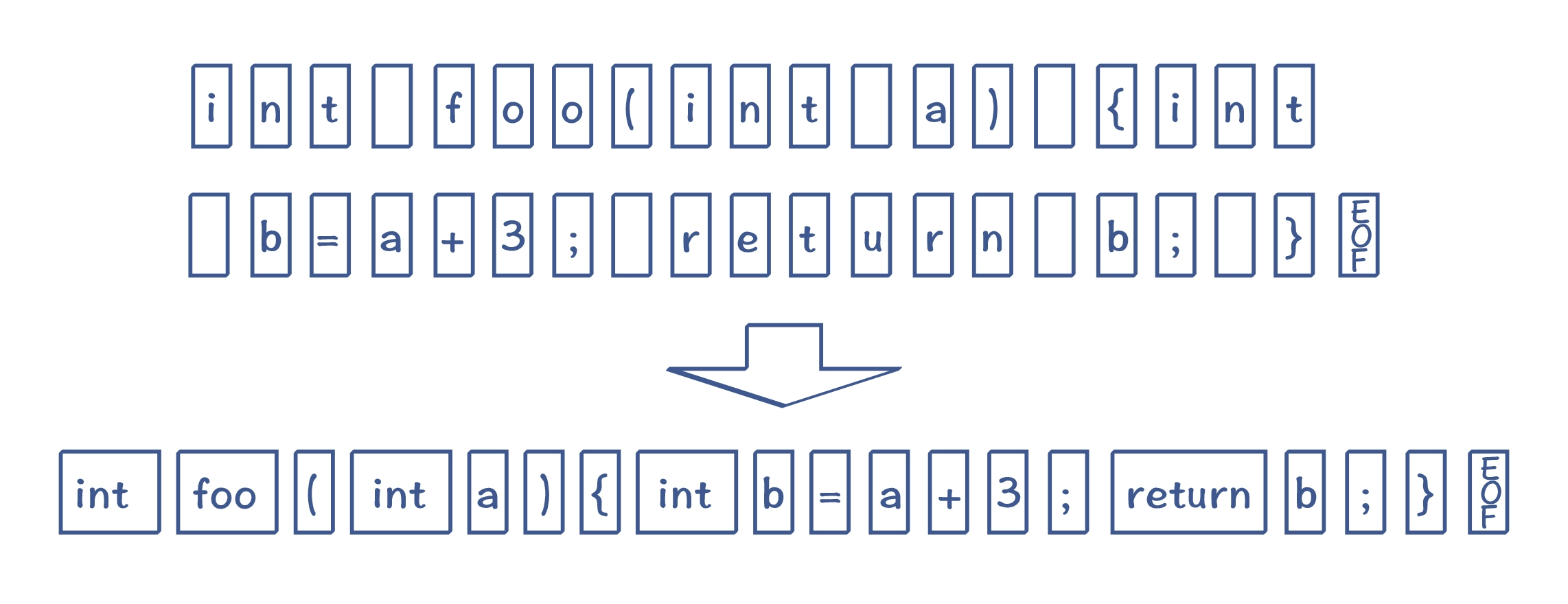
把字符串转换为 Token(注意:其中的空白字符,代表空格、tab、回车和换行符,EOF 是文件结束符) -
语法分析(Syntactic Analysis)
语法分析: 需要让编译器想理解自然语言一样,理解它的语法结构
比如说:“我喜欢又聪明又勇敢的你”,它的语法结构可以表示成下面这样的树状结构。
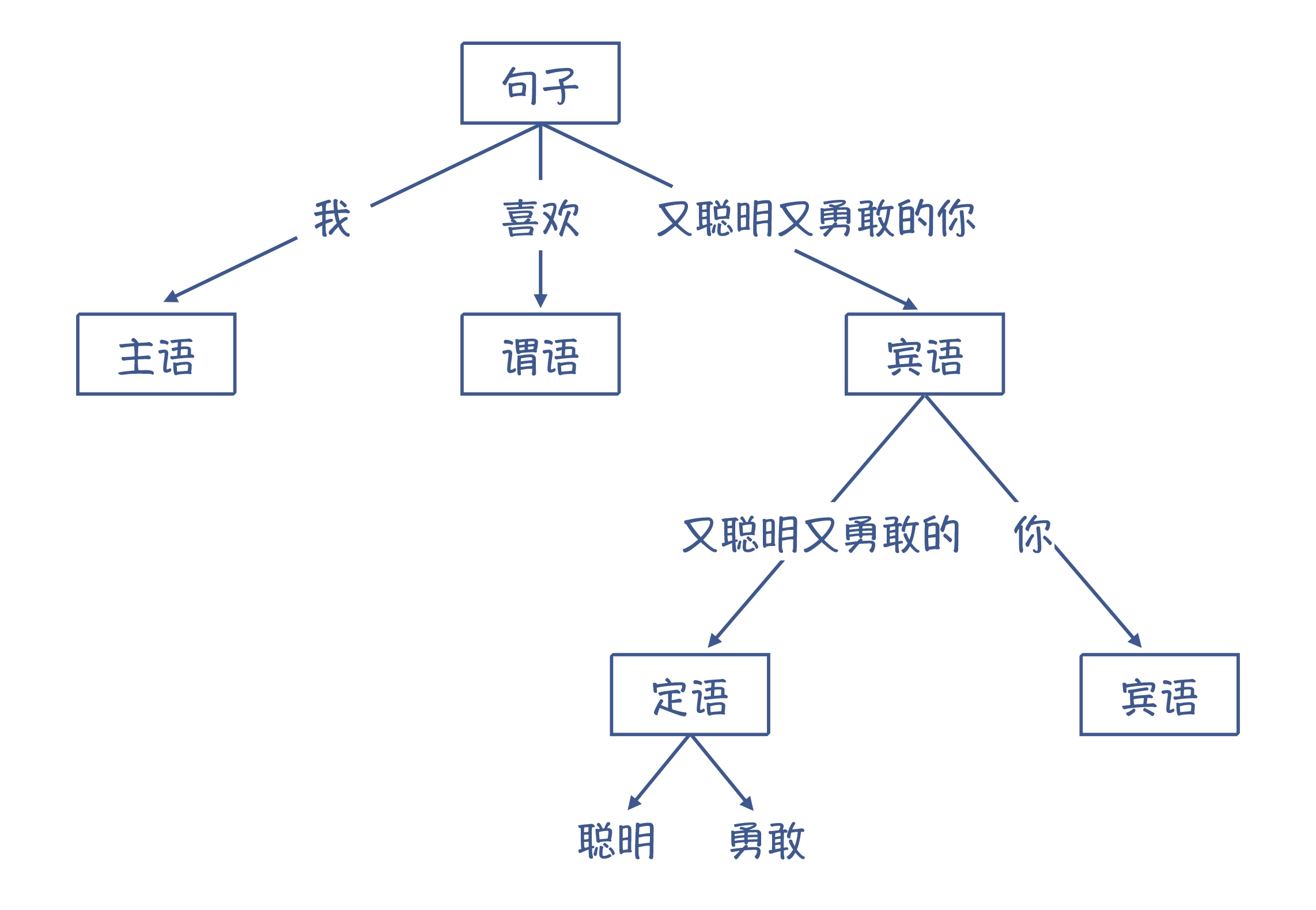
在编译器里,语法分析阶段会把Token串,转换成一个体现语法规则的/树状的数据结构,这个数据结构就叫做抽象语法树(AST, Abstract Syntax Tree)
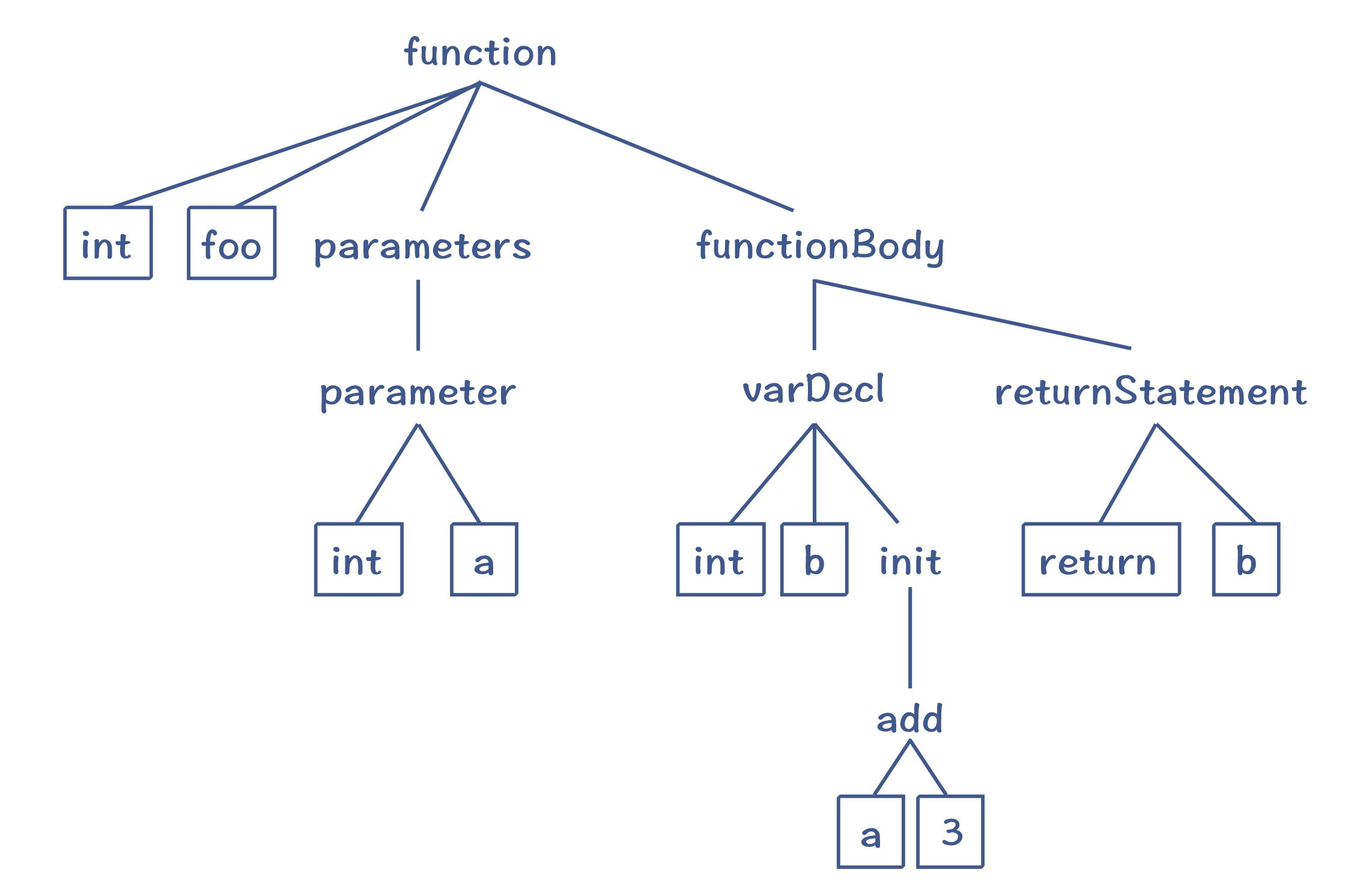
- 语义分析(Semantic Analysis)
语义分析的重要特点:做上下文相关的分析 。
引用消解需要在上下文中查找某个标识符的定义与引用的关系
引用消解,如函数参数中的局部变量a,和全局变量a,在调用函数计算a+3时,会调用那个a?肯定是函数体里的a了,这样能跟正确的变量定义关联的过程,就叫做引用消解(Resolve)
语义分析获得的一些信息(引用消解信息、类型信息等),会附加到 AST 上。这样的 AST 叫做带有标注信息的 AST(Annotated AST/Decorated AST),用于更全面地反映源代码的含义。
带有标注信息的AST:
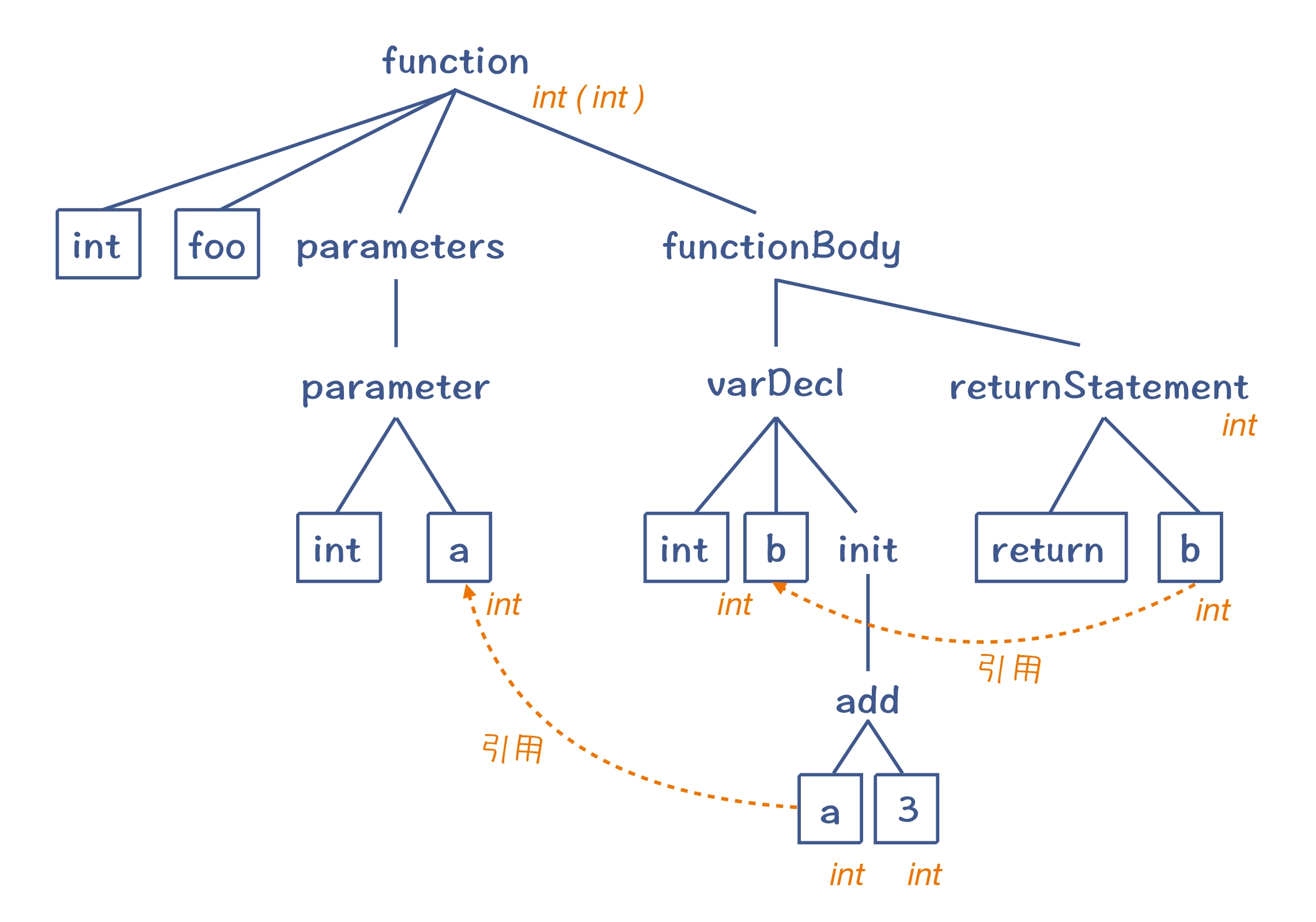
语义分析阶段,编译器会做语义理解和语义检查这两方面的工作。词法分析、语法分析和语义分析,统称编译器的前端,它完成的是对源代码的理解工作。
接下来工作
做完语义分析,此时编译器可以完全理解了程序的含义,并把他表示成带有语义信息的AST/符号表等数据结构
因程序最终要在目标设备上运行,那编译器就需要懂得目标语言以及目标语言的词法/语法和语义,才能保证翻译的正确性。生成目标代码的工作,就叫做后端工作
通常来说,目标代码指的是汇编代码,它是汇编器(Assembler)所能理解的语言,跟机器码有直接的对应关系。汇编器能够将汇编代码转换成机器码。
对于不同架构的 CPU,还需要生成不同的汇编代码,这使得我们的工作量更大。所以,我们通常要在这个时候增加一个环节:先翻译成中间代码(Intermediate Representation,IR)。
中间代码(Intermediate Representation)
中间代码IR,是处于源代码和目标代码之间的一种表示形式。
使用IR有两个原因:
-
是很多解释型的语言,可以直接执行 IR,比如 Python 和 Java。这样的话,编译器生成 IR 以后就完成任务了,没有必要生成最终的汇编代码。
-
在生成代码的时候,需要做大量的优化工作。而很多优化工作没必要基于汇编代码来做,而是可以IR,用统一的算法来完成。
优化(Optimization)
为什么需要优化工作呢?
- 是源语言和目标语言有差异
- 程序员写的代码不是最优的,而编译器会帮忙纠正
采用中间代码来编写优化算法的好处,是可以把大部分的优化算法,写成与具体 CPU 架构无关的形式,从而大大降低编译器适配不同 CPU 的工作量。并且,如果采用像 LLVM 这样的工具,我们还可以让多种语言的前端生成相同的中间代码,这样就可以复用中端和后端的程序了。
生成目标代码
编译器最后一个阶段的工作,是生成高效率的目标代码,也就是汇编代码。这个阶段,编译器也有几个重要的工作。
第一,是要选择合适的指令,生成性能最高的代码。
第二,是要优化寄存器的分配,让频繁访问的变量(比如循环变量)放到寄存器里,因为访问寄存器要比访问内存快 100 倍左右。
第三,是在不改变运行结果的情况下,对指令做重新排序,从而充分运用 CPU 内部的多个功能部件的并行计算能力。
目标代码生成以后,整个编译过程就完成了。
参考:[编译的全过程都悄悄做了哪些事情?] (https://time.geekbang.org/column/article/242479)

