机器学习编译:张量程序抽象
元张量函数
上一节:机器学习编译 -- 什么是机器学习编译 和官方文档:概述介绍机器学习编译的过程可以被看作张量函数之间的变换。一个典型的机器学习的执行包含许多步将输入张量之间转化为最终预测的计算步骤,其中的每一步都被称为元张量函数(primitive tensor function)
元张量函数:

在上面这张图中,张量算子 linear, add, relu 和 softmax 均为元张量函数。特别的是,许多不同的抽象能够表示(和实现)同样的元张量函数(正如下图所示)。我们可以选择调用已经预先编译的框架库(如 torch.add 和 numpy.add)并利用在 Python 中的实现。在实践中,元张量函数被例如 C 或 C++ 的低级语言所实现,并且在一些时候会包含一些汇编代码。
同一个元张量函数的不同形式:

许多机器学习框架都提供机器学习模型的编译过程,以将元张量函数变换为更加专门的、针对特定工作和部署环境的函数。
元张量函数间的变换:
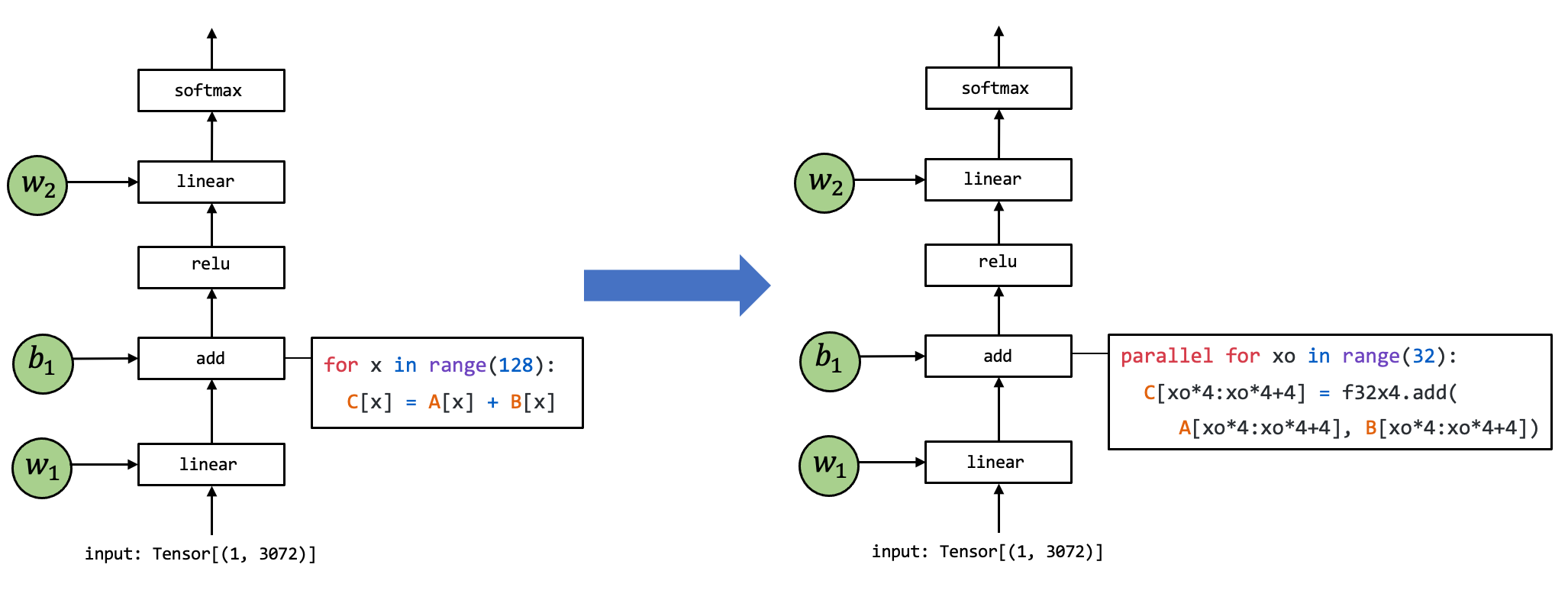
上面这张图展示了一个元张量函数 add 的实现被变换至另一个不同实现的例子,其中在右侧的代码是一段表示可能的组合优化的伪代码:左侧代码中的循环被拆分出长度为 4 的单元,f32x4.add 对应的是一个特殊的执行向量加法计算的函数。
张量程序抽象
为了让我们能够更有效地变换元张量函数,我们需要一个有效的抽象来表示这些函数。
通常来说,一个典型的元张量函数实现的抽象包含了一下成分:存储数据的多维数组,驱动张量计算的循环嵌套以及计算部分本身的语句。
元张量函数中的典型成分:
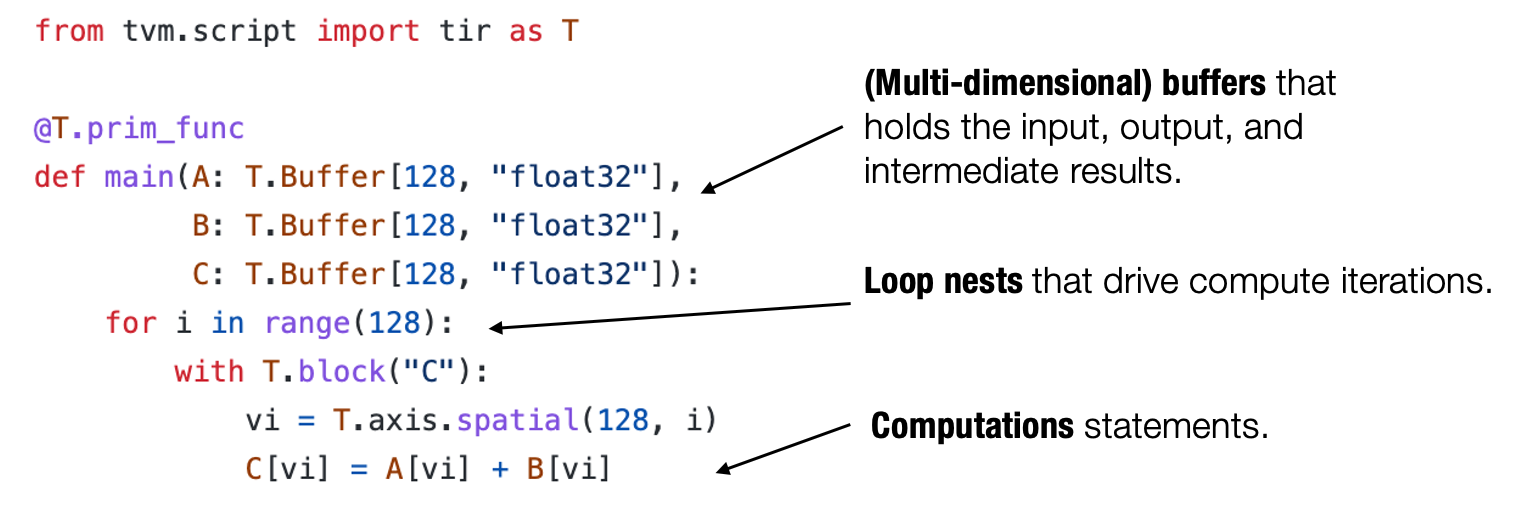
我们称这类抽象为 张量程序抽象。张量程序抽象的一个重要性质是,他们能够被一系列有效的程序变换所改变。
一个元张量函数的序列变换:
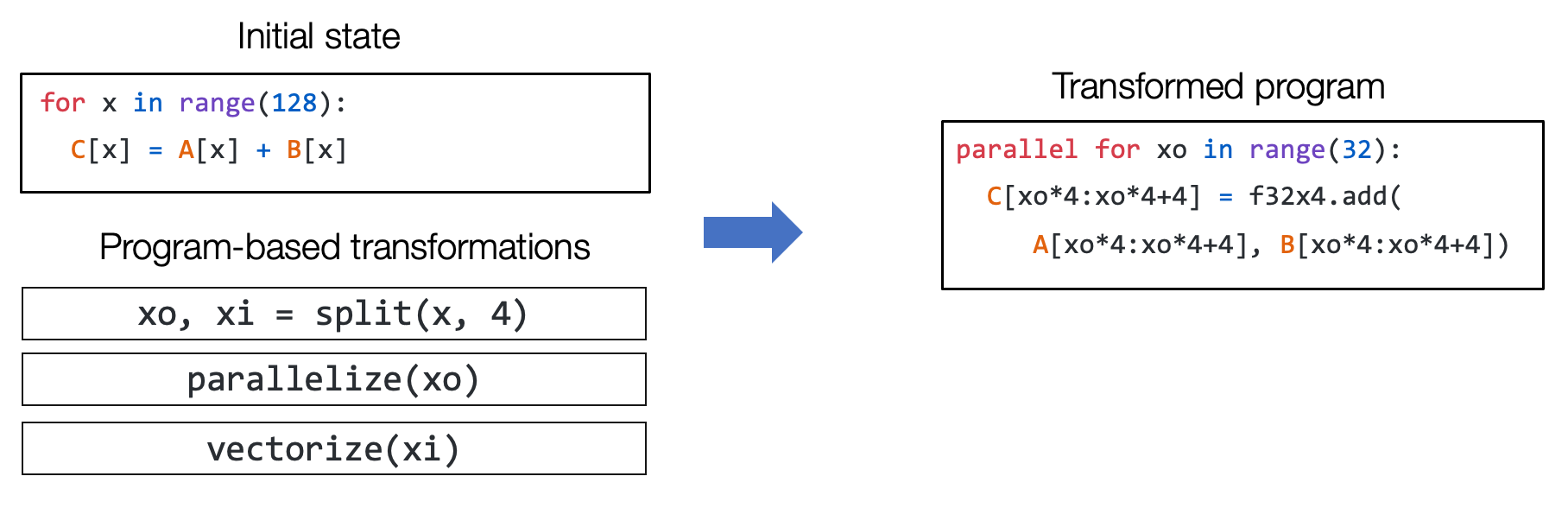
例如,我们能够通过一组变换操作(如循环拆分、并行和向量化)将上图左侧的一个初始循环程序变换为右侧的程序。
张量程序抽象中的其它结构
重要的是,我们不能任意地对程序进行变换,比方说这可能是因为一些计算会依赖于循环之间的顺序。但幸运的是,我们所感兴趣的大多数元张量函数都具有良好的属性(例如循环迭代之间的独立性)。
张量程序可以将这些额外的信息合并为程序的一部分,以使程序变换更加便利。
循环迭代作为张量程序的额外信息:

举个例子,上面图中的程序包含额外的 T.axis.spatial 标注,表明 vi 这个特定的变量被映射到循环变量 i,并且所有的迭代都是独立的。这个信息对于执行这个程序而言并非必要,但会使得我们在变换这个程序时更加方便。在这个例子中,我们知道我们可以安全地并行或者重新排序所有与vi有关的循环,只要实际执行中 vi 的值按照从 0 到 128 的顺序变化。
小结
元张量函数表示机器学习模型计算中的单个单元计算。
- 一个机器学习编译过程可以有选择地转换元张量函数的实现。
张量程序是一个表示元张量函数的有效抽象。
- 关键成分包括: 多维数组,循环嵌套,计算语句。
- 程序变换可以被用于加速张量程序的执行。
- 张量程序中额外的结构能够为程序变换提供更多的信息。
整个过程:
练习:
二维卷积
二维卷积。这是图像处理中的常见操作。
NCHW布局的卷积的数学定义:
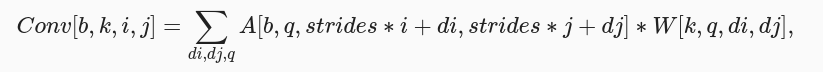
其中,A 是输入张量,W是权重张量,b是批次索引,k是输出通道,i和j是图像高度和宽度的索引,di和dj是权重的索引,q是输入通道,strides是过滤器窗口的步幅(步长)
这里采用步长strides =1,padding = 0
PS:卷积后尺寸计算:

根据计算公式:可得到输出数据的尺寸:
N, CI, H, W, CO, K = 1, 1, 8, 8, 2, 3
OUT_H, OUT_W = H - K + 1, W - K + 1
data = np.arange(N*CI*H*W).reshape(N, CI, H, W)
weight = np.arange(CO*CI*K*K).reshape(CO, CI, K, K)
# torch version
import torch
data_torch = torch.Tensor(data)
weight_torch = torch.Tensor(weight)
conv_torch = torch.nn.functional.conv2d(data_torch, weight_torch)
conv_torch = conv_torch.numpy().astype(np.int64)
conv_torch
输出结果:
array([[[[ 474, 510, 546, 582, 618, 654],
[ 762, 798, 834, 870, 906, 942],
[1050, 1086, 1122, 1158, 1194, 1230],
[1338, 1374, 1410, 1446, 1482, 1518],
[1626, 1662, 1698, 1734, 1770, 1806],
[1914, 1950, 1986, 2022, 2058, 2094]],
[[1203, 1320, 1437, 1554, 1671, 1788],
[2139, 2256, 2373, 2490, 2607, 2724],
[3075, 3192, 3309, 3426, 3543, 3660],
[4011, 4128, 4245, 4362, 4479, 4596],
[4947, 5064, 5181, 5298, 5415, 5532],
[5883, 6000, 6117, 6234, 6351, 6468]]]])
现使用IRModule MyConv并运行代码以查看实现结果
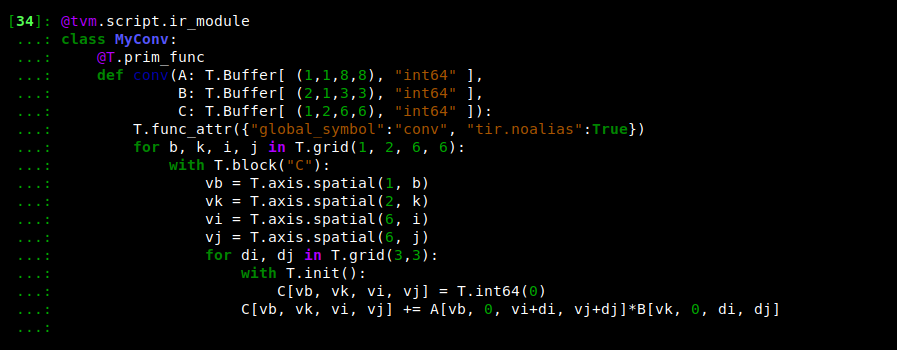
指定target目标编译并运行:
rt_lib = tvm.build(MyConv, target="llvm")
data_tvm = tvm.nd.array(data)
weight_tvm = tvm.nd.array(weight)
conv_tvm = tvm.nd.array(np.empty((N, CO, OUT_H, OUT_W), dtype=np.int64))
rt_lib["conv"](data_tvm, weight_tvm, conv_tvm)
np.testing.assert_allclose(conv_tvm.numpy(), conv_torch, rtol=1e-5)
并行化/向量化与循环展开
介绍parallel/vectorize和unroll,这三个原语被用于循环上,指示循环应当如何执行,实例如下:
@tvm.script.ir_module
class MyAdd:
@T.prim_func
def add(A: T.Buffer[(4, 4), "int64"],
B: T.Buffer[(4, 4), "int64"],
C: T.Buffer[(4, 4), "int64"]):
T.func_attr({"global_symbol": "add"})
for i, j in T.grid(4, 4):
with T.block("C"):
vi = T.axis.spatial(4, i)
vj = T.axis.spatial(4, j)
C[vi, vj] = A[vi, vj] + B[vi, vj]
sch = tvm.tir.Schedule(MyAdd)
block = sch.get_block("C", func_name="add")
i, j = sch.get_loops(block)
i0, i1 = sch.split(i, factors=[2, 2])
sch.parallel(i0)
sch.unroll(i1)
sch.vectorize(j)
IPython.display.Code(sch.mod.script(), language="python")
输出结果:
@tvm.script.ir_module
class Module:
@T.prim_func
def add(A: T.Buffer[(4, 4), "int64"], B: T.Buffer[(4, 4), "int64"], C: T.Buffer[(4, 4), "int64"]) -> None:
# function attr dict
T.func_attr({"global_symbol": "add"})
# body
# with T.block("root")
for i_0 in T.parallel(2):
for i_1 in T.unroll(2):
for j in T.vectorized(4):
with T.block("C"):
vi = T.axis.spatial(4, i_0 * 2 + i_1)
vj = T.axis.spatial(4, j)
T.reads(A[vi, vj], B[vi, vj])
T.writes(C[vi, vj])
C[vi, vj] = A[vi, vj] + B[vi, vj]
变换批量矩阵乘法程序
bmm 的定义:
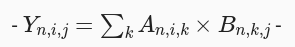
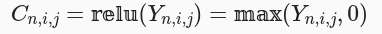
提供 lnumpy 函数作为提示:
def lnumpy_mm_relu_v2(A: np.ndarray, B: np.ndarray, C: np.ndarray):
Y = np.empty((16, 128, 128), dtype="float32")
for n in range(16):
for i in range(128):
for j in range(128):
for k in range(128):
if k == 0:
Y[n, i, j] = 0
Y[n, i, j] = Y[n, i, j] + A[n, i, k] * B[n, k, j]
for n in range(16):
for i in range(128):
for j in range(128):
C[n, i, j] = max(Y[n, i, j], 0)
tensorIR张量函数表示如下:
@tvm.script.ir_module
class MyBmmRelu:
@T.prim_func
def bmm_relu(A: T.Buffer[(16, 128, 128), "float32"],
B: T.Buffer[(16, 128, 128), "float32"],
C: T.Buffer[(16, 128, 128), "float32"]):
T.func_attr({"global_symbol": "bmm_relu", "tir.noalias": True})
Y = T.alloc_buffer((16, 128, 128), dtype="float32")
for n, i, j, k in T.grid(16, 128, 128, 128):
with T.block("Y"):
vn = T.axis.spatial(16, n)
vi = T.axis.spatial(128, i)
vj = T.axis.spatial(128, j)
vk = T.axis.reduce(128, k)
with T.init():
Y[vn, vi, vj] = T.float32(0)
Y[vn, vi, vj] = Y[vn, vi, vj] + A[vn, vi, vk] * B[vn, vk, vj]
for n, i, j in T.grid(16, 128, 128):
with T.block("C"):
vn = T.axis.spatial(16, n)
vi = T.axis.spatial(128, i)
vj = T.axis.spatial(128, j)
C[vn, vi, vj] = T.max(Y[vn, vi, vj], T.float32(0))
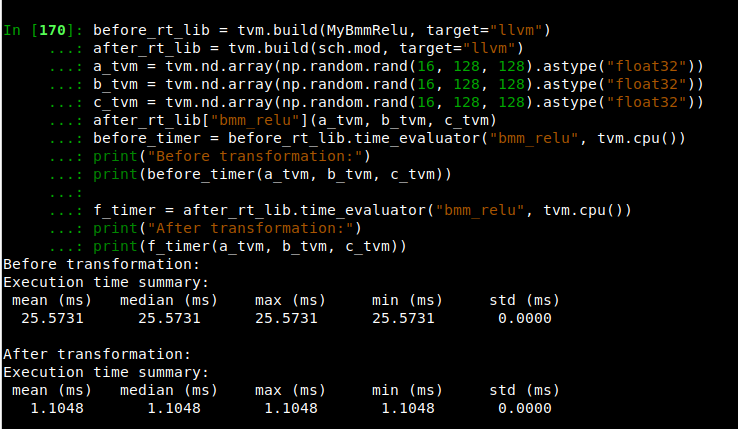
目标:目前有目标程序,如何将程序变换成target程序
target目标程序:
@tvm.script.ir_module
class TargetModule:
@T.prim_func
def bmm_relu(A: T.Buffer[(16, 128, 128), "float32"], B: T.Buffer[(16, 128, 128), "float32"], C: T.Buffer[(16, 128, 128), "float32"]) -> None:
T.func_attr({"global_symbol": "bmm_relu", "tir.noalias": True})
Y = T.alloc_buffer([16, 128, 128], dtype="float32")
for i0 in T.parallel(16):
for i1, i2_0 in T.grid(128, 16):
for ax0_init in T.vectorized(8):
with T.block("Y_init"):
n, i = T.axis.remap("SS", [i0, i1])
j = T.axis.spatial(128, i2_0 * 8 + ax0_init)
Y[n, i, j] = T.float32(0)
for ax1_0 in T.serial(32):
for ax1_1 in T.unroll(4):
for ax0 in T.serial(8):
with T.block("Y_update"):
n, i = T.axis.remap("SS", [i0, i1])
j = T.axis.spatial(128, i2_0 * 8 + ax0)
k = T.axis.reduce(128, ax1_0 * 4 + ax1_1)
Y[n, i, j] = Y[n, i, j] + A[n, i, k] * B[n, k, j]
for i2_1 in T.vectorized(8):
with T.block("C"):
n, i = T.axis.remap("SS", [i0, i1])
j = T.axis.spatial(128, i2_0 * 8 + i2_1)
C[n, i, j] = T.max(Y[n, i, j], T.float32(0))
任务:如何将原始程序转换为目标程序
sch = tvm.tir.Schedule(MyBmmRelu)
# TODO: transformations
# Hints: you can use
# `IPython.display.Code(sch.mod.script(), language="python")`
# or `print(sch.mod.script())`
# to show the current program at any time during the transformation.
# Step 1. Get blocks
Y = sch.get_block("Y", func_name="bmm_relu")
...
# Step 2. Get loops
b, i, j, k = sch.get_loops(Y)
...
# Step 3. Organize the loops
k0, k1 = sch.split(k, ...)
sch.reorder(...)
sch.compute_at/reverse_compute_at(...)
...
# Step 4. decompose reduction
Y_init = sch.decompose_reduction(Y, ...)
...
# Step 5. vectorize / parallel / unroll
sch.vectorize(...)
sch.parallel(...)
sch.unroll(...)
IPython.display.Code(sch.mod.script(), language="python")
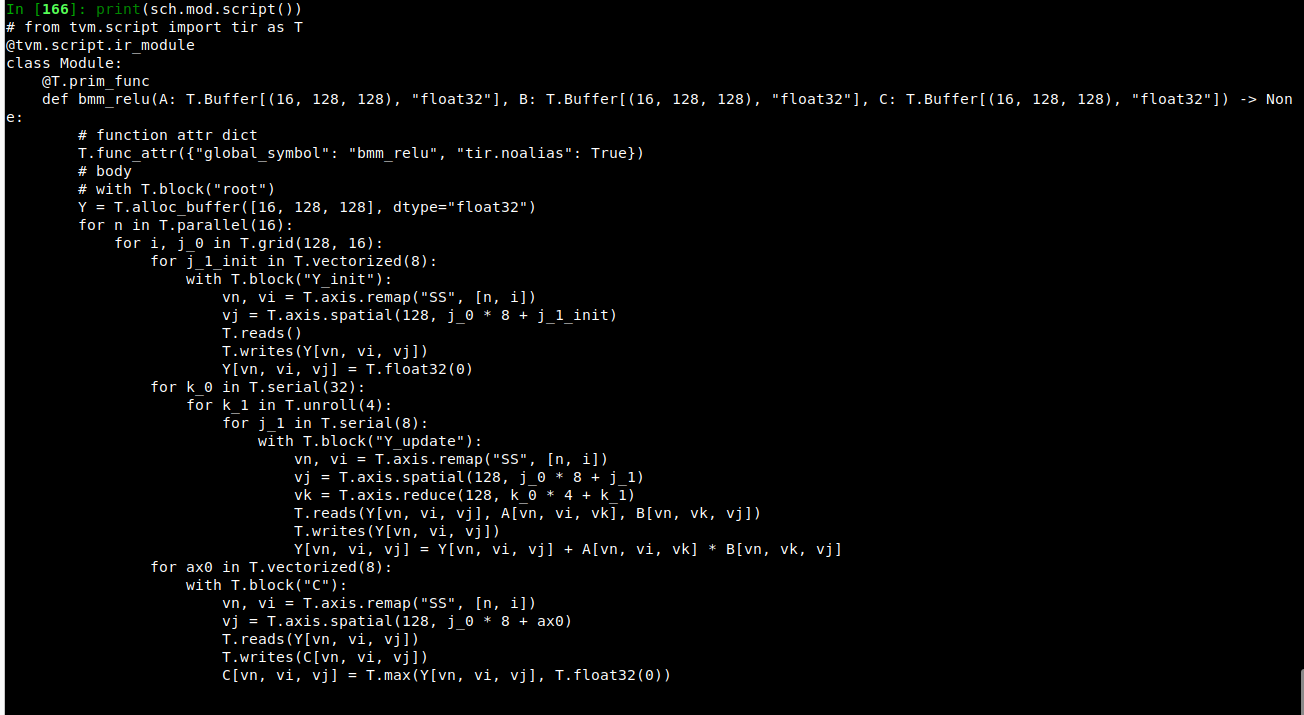
参考:https://mlc.ai/zh/chapter_tensor_program/tensor_program.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号