高性能深度学习推理引擎 -- OpenPPL
OpenPPL
OpenPPL是商汤基于自研高性能算字库的开源深度学习推理平台,能够让人工智能应用高效可靠地运行在现有的CPU/GPU等计算平台上,为云端场景提供人工智能推理服务
OpenPPL基于全自研高性能算子库,拥有极致调优的性能,同时提供云原生环境下的 AI模型多后端部署能力,并支持OpenMMLab等胜读学习模型的高效部署。
- 高性能
设计微架构友好的任务/数据/指令等多级并行策略,自研NV GPU/X86 CPU计算库,满足部署场景对神经网络推理/常用图像处理的性能需求
- 支持GPU T4 平台FP16推理
- 支持CPU X86平台FP32推理
- 核心算子优化,平均性能领先业界
- OpenMMLab部署
支持OpenMMLab检测/分类/分割/超分等系列前沿模型,同时提供模型前后处理所需图像处理算子
- 遵循ONNX开放标准,提供ONNX转换支持
- 支持网络动态特性
- 提供MMCV算子高性能实现
- 云上多后端部署
面向云端异构推理场景,支持多平台部署
- 支持X86 FMA & AVX512/NV Turing架构
- 支持异构设备并行推理
git网址:
PS:以上来源于:https://cloud.tencent.com/developer/article/1854542
OpenPPL操作流程
python版
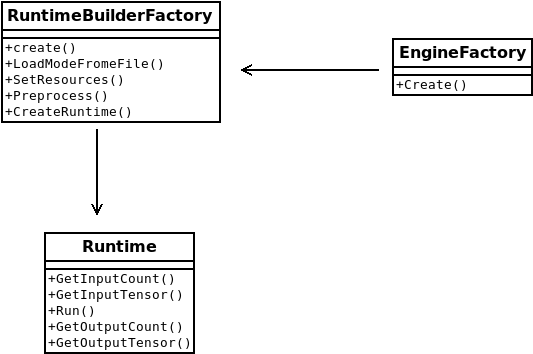
- Creating Engines
在PPLNN中,引擎Engine指的是运行在特定设备如CPU或INVIDIA GPU上op实现的集合.
For Example
构建一个X86引擎工厂:
x86_options = pplnn.x86.EngineOptions()
x86_engine = pplnn.x86.EngineFactory.Create(x86_options)
这样就创建了一个能够运行在兼容X86(X86-compatible)的CPU上
或者
cuda_options = pplnn.cuda.EngineOptions()
cuda_engine = pplnn.cuda.EngineFactory.Create(cuda_options)
创建可以运行在NVIDIA GPU上的引擎
- Creating an OnnxRuntimeBuilder
使用
runtime_builder = pplnn.onnx.RuntimeBuilderFactory.Create()
创建一个onnx.RuntimeBuilder,它将用于创建Runtime实例
- Creating a Runtime Instance
实现从指定文件中加载ONNX模型
onnx_model_file = "/path/to/onnx_model_file"
status = runtime_builder.LoadModelFromFile(onnx_model_file)
创建RuntimeBuderResource,并将前面创建的引擎工厂赋给它.
resources = RuntimeBuilderResources()
resources.engines = [x86_engine] # or = [cuda_engine]
runtime_builder.SetResources(resources)
PPLNN在同一个模型中也支持多个引擎
例如:
resources.engines = [x86_engine, cuda_engine]
status = runtime_builder.SetResources(resources)
模型将被分成多个部分,自动将不同的操作(OP)分配到不同的引擎上.
在创建Runtime实例之前要做些准备
status = runtime_builder.Preprocess()
创建runtime实例
runtime = runtime_builder.CreateRuntime()
- Filling Inputs
我们可以通过下面的Runtime的函数获取图输入
input_count = runtime.GetInputCount()
tensor = runtime.GetInputTensor(idx)
并且,填充输入数据(在此代码段中使用随机数据)
for i in range(runtime.GetInputCount()):
tensor = runtime.GetInputTensor(i)
dims = GenerateRandomDims(tensor.GetShape())
in_data = np.random.uniform(-1.0, 1.0, dims)
status = tensor.ConvertFromHost(in_data)
if status != pplcommon.RC_SUCCESS:
logging.error("copy data to tensor[" + tensor.GetName() + "] failed: " +
pplcommon.GetRetCodeStr(status))
sys.exit(-1)
- Evaluating the Model
ret_code = runtime.Run()
- Getting Results
for i in range(runtime.GetOutputCount()):
tensor = runtime.GetOutputTensor(i)
shape = tensor.GetShape()
tensor_data = tensor.ConvertToHost()
out_data = np.array(tensor_data, copy=False)
C++版
加载命名空间
using namespace ppl::nn
- Creating engines
使用内建x86::EngineFactory函数:
Engine* x86::EngineFactory::Create(const x86::EngineOptions&);
创建可运行在兼容x86 CPU的引擎:
x86::EngineOptions x86_options;
Engine* x86_engine = x86::EngineFactory::Create(x86_options);
或 可运行在INVIDIA GPUS上的引擎:
cuda::EngineOptions cuda_options;
// ... set options
Engine* cuda::EngineFactory::Create(cuda_options);
- Registering Build-in Op Implementations(optional)
使用x86::RegisterBuiltinOpImpls()加载内建op实现
cuda引擎可以调用cuda::RegisterBuiltinOpImpls()
- Creating an ONNX RuntimeBuilder
使用下面的函数来创建onnx::RuntimeBuilder:
onnx::RuntimeBuilder* onnx::RuntimeBuilderFactory::Create();
从buffer或者文件中加载模型:
ppl::common::RetCode LoadModel(const char* model_file);
ppl::common::RetCode LoadModel(const char* model_buf, uint64_t buf_len);
然后设置用于处理的资源
struct Resources final {
Engine** engines;
uint32_t engine_num;
};
ppl::common::RetCode SetResources(const Resources&)
Resource下的engines是我们创建好的x86_engine:
vector<Engine*> engine_ptrs;
engines.push_back(x86_engine);
resources.engines = engine_ptrs.data();
注: 必须保证在Runtime对象的生命周期中,engines元素是有效的
在同一个模型中,PPLNN也支持多个引擎:
例如:
Engine* x86_engine = x86::EngineFactory::Create(x86::EngineOptions());
Engine* cuda_engine = cuda::EngineFactory::Create(cuda::EngineOptions());
vector<unique_ptr<Engine>> engines;
engines.emplace_back(unique_ptr<Engine>(x86_engine));
engines.emplace_back(unique_ptr<Engine>(cuda_engine));
// TODO add other engines
// use x86 and cuda engines to run this model
vector<Engine*> engine_ptrs = {x86_engine, cuda_engine};
Resources resources;
resources.engines = engine_ptrs.data();
resources.engine_num = engine_ptrs.size();
...
- Creating a Runtime
在创建Runtime实例之前,需要做些准备:
builder->Preprocess();
然后使用:
Runtime* RuntimeBuilder::CreateRuntime();
创建Runtime实例
- Filling Inputs
使用Runtime下的函数,获取图输入:
uint32_t Runtime::GetInputCount() const;
Tensor* Runtime::GetInputTensor(uint32_t idx) const;
并填入数据:
for (uint32_t c = 0; c < runtime->GetInputCount(); ++c) {
auto t = runtime->GetInputTensor(c);
auto shape = t->GetShape();
auto nr_element = shape->CalcBytesIncludingPadding() / sizeof(float);
vector<float> buffer(nr_element);
// fill random input data
std::default_random_engine eng;
std::uniform_real_distribution<float> dis(-1.0f, 1.0f);
for (uint32_t i = 0; i < nr_element; ++i) {
buffer[i] = dis(eng);
}
auto status = t->ReallocBuffer();
if (status != RC_SUCCESS) {
// ......
}
// our random data is treated as NDARRAY
TensorShape src_desc = *t->GetShape();
src_desc.SetDataFormat(DATAFORMAT_NDARRAY);
// input tensors may require different data format
status = t->ConvertFromHost((const void*)buffer.data(), src_desc);
if (status != RC_SUCCESS) {
// ......
}
}
- Evaluating the Compute Graph
使用Runtime::Run():
RetCode status = runtime->Run();
- 获取结果
迭代每一次输出:
for (uint32_t c = 0; c < runtime->GetOutputCount(); ++c) {
auto t = runtime->GetOutputTensor(c);
const TensorShape* dst_desc = t->GetShape();
dst_desc->SetDataFormat(DATAFORMAT_NDARRAY);
auto bytes = dst_desc->CalcBytesIncludingPadding();
vector<char> buffer(bytes);
auto status = t->ConvertToHost((void*)buffer.data(), *dst_desc);
// ......
}
其他详细的API可访问:https://github.com/openppl-public/ppl.nn
开发指导
如何添加新的Engines/Ops,在不同平台如x86/cuda如何支持op操作
添加新的Engines和Ops
如何添加新的引擎
- Define and Implement a Class Inherited from EngineImpl
EngineImpl(在 src/ppl/nn/engines/engine_impl.h中定义了)定义了PPLNN所需的接口
通过Runtime实例创建一个EngineContext
EngineContext* EngineImpl::CreateEngineContext();
判断此引擎是否可以运行节点指定的操作
bool EngineImpl::Supports(const ir::Node* node) const;
优化graph并将结果填入info
ppl::common::RetCode EngineImpl::ProcessGraph(const utils::SharedResource&, ir::Graph* graph,
RuntimePartitionInfo* info);
其中RuntimePartitionInfo定义如下:
struct RuntimePartitionInfo final {
std::map<edgeid_t, RuntimeConstantInfo> constants;
std::map<nodeid_t, std::unique_ptr<OptKernel>> kernels;
};
constants是只读的,由多个Runtime实例使用
kernels是OptKernel的集合,用于创建KernelImp实例
创建与该引擎相同类型的实例
EngineImpl* Create() const;
- Define and Implement a Class Inherited from EngineContext
EngineContext(在 src/ppl/nn/engines/engine_context.h中定义),EngineContext只被Runtime使用
返回EngineContext的名字
const char* EngineContext::GetName() const;
通过Runtime 返回设备实例
Device* EngineContext::GetDevice();
在调用RuntimeImpl::Run()之前,调用
ppl::common::RetCode EngineContext::BeforeRun();
- Define and Implement Op Classes Inherited from OptKernel
OptKernel(定义在 src/ppl/nn/runtime/opt_kernel.h)储存计算一个OP的所有数据.它能创建多个KernelImpl实例
创建KernelImpl实例,用于运行时
KernelImpl* OptKernel::CreateKernelImpl() const;
- Define and Implement Op Classes Inherited from KernelImpl
KernelImpl(定义在src/ppl/nn/runtime/kernel_impl.h)是用于计算一个Op的主要类,它由OptKernel创建.每一个KernelImpl实例只能被一个Runtime实例使用
ppl::common::RetCode KernelImpl::Execute(KernelExecContext* ctx);
如何给已有引擎体添加新的Op操作
以X86 Engine为例,添加一个新的ONNX op
add a Parameter Parser
ParmParserManger(定义在 src/ppl/nn/models/onnx/param_parser_manager.h)有一个Register()函数
void ParamParserManager::Register(const std::string& domain, const std::string& op_type,
const ParserInfo&);
它可以为新的Ops注册分析器例程
typedef void* (*CreateParamFunc)();
typedef ppl::common::RetCode (*ParseParamFunc)(const ::onnx::NodeProto&, const ParamParserExtraArgs&, ir::Node*, void*);
typedef void (*DeleteParamFunc)(void* param);
struct ParserInfo final {
CreateParamFunc create_param;
ParseParamFunc parse_param;
DeleteParamFunc destroy_param;
};
如果没有任何参数,ParserInfo成员应该是nullptr
- Add a New Class Inherited from OptKernel
这依赖于引擎提供的策略.在X86Engine,一个OptKernelCreatorManager'单例用来管理OptKernel`创建者函数
typedef X86OptKernel* (*OptKernelCreator)(const ir::Node*);
ppl::common::RetCode OptKernelCreatorManager::Register(
const std::string& domain, const std::string& type, const utils::VersionRange versions,
OptKernelCreator);
用于注册创建OptKernel实例的函数
- Add a New Class Inherited from KernelImpl
这块和怎样添加新引擎是一样的
X86
支持的算子(Ops)和平台
见X86:supported-ops-and-platforms
自定义算子添加
添加自定义算子需要先添加算子定义及其在不同架构上的实现。本节仅介绍在x86架构上添加算子的实现细节。
-
概述
PPLNN在x86架构上添加自定义算子的步骤如下: -
添加算子参数定义与解析(如果算子无需参数,或参数定义与解析已添加,则跳过此步骤)
-
添加算子定义,包括数据类型推断、维度计算、数据排布选择等
-
添加算子调用接口
-
添加kernel函数
几点约定:
- 本章中自定义算子的名称将以
来代替。 - 本章将以框架中已实现的LeakyReLU为例,来帮助理解添加自定义算子的流程。在介绍时会根据需要省略一部分代码,完整代码请直接参考源码。
- LeakyReLU算子的定义可参见onnx文档:https://github.com/onnx/onnx/blob/master/docs/Operators.md#LeakyRelu
- 添加算子参数定义与解析
若算子参数定义与解析已添加,则跳过此步
1.1. 添加参数定义
若算子无参数,则跳过此步骤
在ppl.nn/src/ppl/nn/params目录下创建<domain_name>/
以LeakyReLU为例,其参数定义在ppl.nn/src/ppl/nn/params/onnx/leaky_relu_param.h:
struct LeakyReLUParam {
float alpha; // LeakyReLU仅需要一个参数alpha
bool operator==(const LeakyReLUParam& p) const { return this->alpha == p.alpha; } // 对==运算符进行重载
};
LeakyReLUParam定义了LeakyReLU算子所需的参数。参考onnx的LeakyReLU定义可知,该算子仅需一个float型的参数alpha。另外LeakyReLUParam重载了运算符==,用于判断两个参数对象是否相等。
1.2. 添加 参数解析函数
若算子无需参数,则跳过此步骤
在ppl.nn/src/ppl/nn/models/onnx/parsers目录下创建parse_
以LeakyReLU为例,其参数解析函数实现在ppl.nn/src/ppl/nn/models/onnx/parsers/parse_leaky_relu_param.cc内:
ppl::common::RetCode ParseLeakyReLUParam(const ::onnx::NodeProto& pb_node, void* arg, ir::Node*, ir::GraphTopo*) {
auto param = static_cast<ppl::common::LeakyReLUParam*>(arg);
param->alpha = utils::GetNodeAttrByKey<float>(pb_node, "alpha", 0.01); // 从onnx中解析alpha字段,如果不存在则使用默认值0.01
return ppl::common::RC_SUCCESS;
}
函数ParseLeakyReLUParam读入onnx node信息pb_node,通过GetNodeAttrByKey解析其中的alpha字段,放入上文定义的参数结构体中,完成参数解析。
1.3. 注册参数和参数解析函数
添加好参数结构体和参数解析函数后,需要将其注册在ppl.nn/src/ppl/nn/models/onnx/param_parser_manager.cc的ParamParserManager()函数中。
注册时,有两个宏可以使用:
PPL_REGISTER_OP_WITHOUT_PARAM:用于注册无需参数的算子PPL_REGISTER_OP_WITH_PARAM:用于注册需要参数的算子
以LeakyReLU为例:
PPL_REGISTER_OP_WITH_PARAM("", "LeakyRelu", ppl::nn::common::LeakyReLUParam, ParseLeakyReLUParam);
其中第一个参数为domain_name,必须跟onnx模型中的domain保持一致;第二个参数"LeakyRelu"为op_type,必须跟onnx模型中的op_type保持一致;第三、四个参数分别为上文定义的参数结构体和解析函数。
- 添加算子定义
在ppl.nn/src/ppl/nn/engines/x86/optimizer/<domain_name>目录下添加_op.h和 _op.cc,用于定义和实现算子定义。
例如LeakyReLU,其算子定义类放在ppl.nn/src/ppl/nn/engines/x86/optimizer/ops/onnx/leaky_relu_op.h内:
class LeakyReluOp final : public X86OptKernel {
public:
LeakyReluOp(const ir::Node* node)
: X86OptKernel(node) {}
ppl::common::RetCode Init(const OptKernelOptions& options) override; // 初始化(必需)
KernelImpl* CreateKernelImpl() const override; // 创建调用接口(必需)
ppl::common::RetCode SelectFormat(const InputOutputInfo& info, // 排布选择(可选)
std::vector<ppl::common::dataformat_t>* selected_input_formats,
std::vector<ppl::common::dataformat_t>* selected_output_formats) override;
private:
std::shared_ptr<ppl::common::LeakyReLUParam> param_; // 参数结构体指针(可选,若算子无需参数则无需此变量)
};
- Init(必需):进行一些初始化操作,如加载参数、注册数据类型推断函数、注册维度计算函数等
- CreateKernelImpl(必需):创建算子调用借口对象
- SelectFormat(可选):用于数据排布选择
- param_(可选):上文定义的参数结构体指针,若算子无需参数则无需此变量
可根据实际需要,添加或删除部分成员函数和成员变量。
2.1. 注册数据类型推断函数
数据类型推断函数用于根据输入的数据类型,推断出输出的数据类型。
需要在Init函数中将数据类型推断函数注册到infer_type_func_。 infer_type_func_是一个std::function对象,输入InputOutputInfo*,返回void。 可以用函数、lambda表达式来定义数据类型推断函数,再将其赋值给infer_type_func_即可完成注册。
例如LeakyReLU,其在ppl.nn/src/ppl/nn/engines/x86/optimizer/ops/onnx/leaky_relu_op.cc的Init函数中注册了数据类型推断函数:
infer_type_func_ = GenericInferType;
GenericInferType是一个框架预定义的数据类型推导函数,其代码在ppl.nn/src/ppl/nn/engines/x86/optimizer/opt_kernel.h:
static void GenericInferType(InputOutputInfo* info) { // 所有输出的数据类型和第一个输入的数据类型保持一致
auto& in_shape0 = info->GetInput<TensorImpl>(0)->GetShape();
for (uint32_t i = 0; i < info->GetOutputCount(); ++i) {
auto out_shape = &info->GetOutput<TensorImpl>(i)->GetShape();
out_shape->SetDataType(in_shape0.GetDataType());
}
}
可根据自定义算子的需要,注册预定义的数据类型推断函数或自定义的函数。
2.2. 注册维度计算函数
维度计算函数用于根据输入的数据维度,推断输出的数据维度.
需要在Init函数中将维度计算函数注册到infer_dims_func_.
infer_dims_func_是一个std::function对象,输入InputOutputInfo*,返回ppl::common::RetCode.可以用函数/lambda表达式来定义维度计算函数,再将其赋值给infer_dims_func_即可完成注册
例如LeakyReLu,其在ppl.nn/src/ppl/nn/engines/x86/optimizer/ops/onnx/leaky_relu_op.cc的Init函数中注册了维度计算函数:
infer_dims_func_ = [](InputOutputInfo* info) -> RetCode {
return oputils::ReshapeLeakyReLU(info, nullptr);
};
其中,ReshapeLeakyReLU代码在ppl.nn/src/ppl/nn/oputils/onnx/reshape_leaky_relu.cc中:
RetCode ReshapeLeakyReLU(InputOutputInfo* info, const void*) {
if (info->GetInputCount() != 1 || info->GetOutputCount() != 1) {
return RC_INVALID_VALUE;
}
const TensorShape& in_shape0 = info->GetInput<TensorImpl>(0)->GetShape();
auto out_shape0 = &info->GetOutput<TensorImpl>(0)->GetShape();
if (in_shape0.IsScalar()) {
out_shape0->ReshapeAsScalar();
} else {
out_shape0->Reshape(in_shape0.GetDims(), in_shape0.GetDimCount());
}
return RC_SUCCESS;
}
在注册自定义算子维度计算函数时,既可以像LeakyReLU一样在ppl.nn/src/ppl/nn/oputils下写单独的Reshape函数,也可以直接在Init函数中写完所有逻辑。
2.3. 编写数据排布选择函数
数组排布选择函数SelectFormat更加参数/输入的数据类型/排布/维度/算子底层支持的排布等信息,选择该算子需要的输入数据排布,以及输出的数据排布
算子的输入排布和算子需要的输入排布可以不同.
算子的输入排布是指在本算子进行排布选择之前,输入数据的真实排布(通常是由上一个算子的输出或网络的输入决定);
而算子需要的输入排布是指算子根据参数、输入的数据类型、排布、维度、算子底层支持的排布等信息,选择出该算子所需要的输入排布。 当两者不同时,框架会自动插入一个排布转换算子,用于转换不同的数据排布。
目前,x86 架构支持的数据排布有:
- NDARRY(对于4维来说,即为NCHW)
- N16CX(对于4维来说,即为N16CHW,或为N16CHWc16,NCHWc16)
以LeakyReLU为例,其排布选择函数在ppl.nn/src/ppl/nn/engines/x86/optimizer/ops/onnx/leaky_relu_op.cc内:
RetCode LeakyReluOp::SelectFormat(const InputOutputInfo& info,
vector<dataformat_t>* selected_input_formats, // 需要的输入数据排布,默认全为NDARRAY
vector<dataformat_t>* selected_output_formats // 输出数据排布,默认全为NDARRAY
) {
if (info.GetInput<TensorImpl>(0)->GetShape().GetDataFormat() == DATAFORMAT_N16CX) { // 算子输入的数据排布
selected_input_formats->at(0) = DATAFORMAT_N16CX;
selected_output_formats->at(0) = DATAFORMAT_N16CX;
}
return RC_SUCCESS;
}
selected_input_formats是算子需要的输入数据排布,selected_output_formats是算子输出的数据排布,默认值全为NDARRAY.由于LeakyReLU实现了NDRRAY和N16CX两个排布的版本,因此当算子的输入排布为N16CX时,算子u需要的输入排布和输出排布选择N16CX; 当输入为NDARRAY格式时,需要的输入排布和输出排布选择默认值NDARRAY,函数不做任何动作.
在添加自定义算子时,如果算子仅实现了NDARRAY版本(输入输出仅支持NDARRAY排布),SelectFormat函数可以不写,这时会使用基类的默认排布选择函数,需要的输入和输出排布会选择NDARRAY.
2.4. 添加CreateKernelImpl
CreateKernelImpl函数用于创建算子调用借口,根据算子是否需要参数,可使用两种函数:
CreateKernelImplWIthoutParam:用于无需参数的算子CreateKernelImplWithParam:用于需要参数的算子,需要传入参数结构体的指针
LeakyReLU使用的是带参数的版本,其实现在ppl.nn/src/ppl/nn/engines/x86/optimizer/ops/onnx/leaky_relu_op.cc:
KernelImpl* LeakyReluOp::CreateKernelImpl() const {
return CreateKernelImplWithParam<LeakyReluKernel>(param_.get()); // 需要传入参数结构体的指针
}
2.5. 注册算子定义
完成算子定义后,需要使用宏REGISTER_OPT_KERNEL_CREATOR将其注册在ppl.nn/src/ppl/nn/engines/x86/optimizer/opt_kernel_creator_manager.cc的OptKernelCreatorManager()函数中。
以LeakyReLU为例:
REGISTER_OPT_KERNEL_CREATOR("", "LeakyRelu", LeakyReluOp);
第一个参数为domain;第二个参数是为op_type;第三个参数为上文定义的算子定义类的名称.
- 添加算子调用接口
在ppl.nn/src/ppl/nn/engines/x86/kernels/<domain_name>目录下添加_kernel.h和 _kernel.cc,用于定义和实现算子调用接口。
例如LeakyReLU,其算子调用接口定义在ppl.nn/src/ppl/nn/engines/x86/kernels/onnx/leaky_relu_kernel.h:
class LeakyReluKernel : public X86Kernel {
public:
LeakyReluKernel(const ir::Node* node) : X86Kernel(node) {}
void SetParam(const ppl::nn::common::LeakyReLUParam* p) { param_ = p; } // 若算子无参数则无需此函数
private:
ppl::common::RetCode DoExecute(KernelExecContext*) override; // 算子调用函数
private:
const ppl::nn::common::LeakyReLUParam* param_ = nullptr; // 若算子无参数则无需此函数
};
若算子无参数的话,SetParam和param_无需添加,只需构造函数和DoExecute函数即可。
3.1. 添加DoExecute
DoExcute函数读入算子输入,调用kernel函数,得到算子输出.
以LeakyReLU为例,其DoExecute函数在ppl.nn/src/ppl/nn/engines/x86/kernels/onnx/leaky_relu_kernel.cc:
ppl::common::RetCode LeakyReluKernel::DoExecute(KernelExecContext* ctx) {
auto x = ctx->GetInput<TensorImpl>(0); // 输入tensor
auto y = ctx->GetOutput<TensorImpl>(0); // 输出tensor
PPLNN_X86_DEBUG_TRACE("Op: %s\n", GetName().c_str()); // 输出调试信息,仅在Debug模式下生效
PPLNN_X86_DEBUG_TRACE("Input [x]:\n");
PPL_X86_TENSOR_PRINT_DEBUG_MSG(x);
PPLNN_X86_DEBUG_TRACE("Output [y]:\n");
PPL_X86_TENSOR_PRINT_DEBUG_MSG(y);
PPLNN_X86_DEBUG_TRACE("alpha: %f\n", param_->alpha);
PPLNN_X86_DEBUG_TRACE("isa: %u\n", GetISA());
const auto data_type = x->GetShape().GetDataType();
if (data_type == ppl::common::DATATYPE_FLOAT32) { // 数据类型判断
if (MayUseISA(ppl::common::ISA_X86_AVX)) { // 判断是否支持avx指令集
return kernel::x86::leaky_relu_fp32_avx(&y->GetShape(), x->GetBufferPtr<float>(), // avx kernel函数
param_->alpha, y->GetBufferPtr<float>());
} else if (MayUseISA(ppl::common::ISA_X86_SSE)) { // 判断是否支持sse指令集
return kernel::x86::leaky_relu_fp32_sse(&y->GetShape(), x->GetBufferPtr<float>(), // sse kernel函数
param_->alpha, y->GetBufferPtr<float>());
} else {
LOG(ERROR) << "get unsupported isa " << GetISA();
}
} else {
LOG(ERROR) << "unsupported data type: " << ppl::common::GetDataTypeStr(data_type) << ".";
}
return ppl::common::RC_UNSUPPORTED;
}
宏PPLNN_X86_DEBUG_TRACE和PPL_X86_TENSOR_PRINT_DEBUG_MSG用于调试信息,仅在编译Debug模式下生效
MayUseISA函数用于判断当前环境是否可以执行指定的ISA,从而调用不同的kernel函数.常用的ISA有:AVX512、FMA、AVX、SSE。当使用标量代码时,可不做此判断。
3.2. 添加CanDoExcute
CanDoExcute函数执行在DoExecute之前,用于判断是否可以执行DoExecute
大部分算子使用基类的实现(ppl.nn/src/ppl/nn/engines/x86/kernel.cc):
bool X86Kernel::CanDoExecute(const KernelExecContext& ctx) const { // 如果输入中存在空tensor,则返回false,否则返回true
for (uint32_t i = 0; i < ctx.GetInputCount(); ++i) {
auto tensor = ctx.GetInput<TensorImpl>(i);
if (!tensor || tensor->GetShape().CalcBytesIncludingPadding() == 0) {
return false;
}
}
return true;
}
绝大多数情况不需要重载此函数。如果需要使用跟基类不同的行为,则需要重载此函数。
- 添加kernel函数
x86的kernel函数是最底层的计算函数,放在ppl.nn/src/ppl/nn/engines/x86/impls目录下。
由于kernel函数跟上层框架间的耦合度较低,因此可根据自定义算子的特点,自由的安排代码结构。这里仅给出通用的编写kernel函数的规范参考,可不必严格按照本章的方式编写。
4.1. kernel函数声明
kernel函数的接口声明统一放在ppl.nn/src/ppl/nn/engines/x86/impls/include/ppl/kernel/x86目录下,按照数据类型放在不同的子目录下。建议的文件路径为ppl.nn/src/ppl/nn/engines/x86/impls/include/ppl/kernel/x86/<data_type>/
函数输入参数可根据需要自行定义,返回一个ppl::common::RetCode用于指示函数是否执行成功。
函数命名建议:
例如LeakyReLU的fp32 kernel函数接口声明在ppl.nn/src/ppl/nn/engines/x86/impls/include/ppl/kernel/x86/fp32/leaky_relu.h下,其函数命名为leaky_relu_fp32_avx和leaky_relu_fp32_sse:
ppl::common::RetCode leaky_relu_fp32_avx( // avx kernel函数声明
const ppl::nn::TensorShape *src_shape,
const float *src,
const float alpha,
float *dst);
ppl::common::RetCode leaky_relu_fp32_sse( // sse kernel函数声明
const ppl::nn::TensorShape *src_shape,
const float *src,
const float alpha,
float *dst);
这里不使用<data_format>字段是因为LeakyReLU的实现支持任意数据格式。
4.2 Kernel函数实现
kernel函数的实现放在ppl.nn/src/ppl/nn/engines/x86/impls/src/ppl/kernel/x86目录下,按照数据类型放在不同的子目录下。由于kernel函数的实现可能需要多个文件,因此建议每个算子单独建立一个目录。 不同ISA架构的代码应该放在不同的.cpp文件内,并在文件命名时以ISA架构名来区分。
建议的文件路径为ppl.nn/src/ppl/nn/engines/x86/impls/src/ppl/kernel/x86/<data_type>/
以LeakyReLU为例,该算子实现了fp32的avx和sse版本,因此在ppl.nn/src/ppl/nn/engines/x86/impls/src/ppl/kernel/x86/fp32/leaky_relu目录下有leaky_relu_fp32_avx.cpp和leaky_relu_fp32_sse.cpp两个文件,分别实现了leaky_relu_fp32_avx和leaky_relu_fp32_sse函数。
- 几点说明
5.1 编译
添加自定义算子后,由于有新增的.cpp文件,需要将CMakeCache.txt删除后重新运行cmake,否则会提示找不到符号的问题。
若kernel的文件命名格式不能被ppl.nn/src/ppl/nn/engines/x86/impls/CMakeLists.txt识别,则会报ISA指令不支持的错误。
X86 Benchmask工具
详细参考:https://github.com/openppl-public/ppl.nn/blob/master/docs/cn/x86-doc/benchmark_tool.md
CUDA
自定义算子添加
-
概述
PPLNN算子cuda实现步骤如下: -
添加算子定义(若本身存在参数,则需要导入算子参数)
-
添加算子输入输出的数据类型
-
添加算子维度计算
-
添加算子数据排布
-
添加算子调用接口
-
添加算子的cuda后端的kernel实现
-
注册算子
-
添加算子定义
添加算子类型名称以MyOp为例。
首先,在ppl/nn/engines/cuda/optimizer/ops文件下创建一个新的文件夹,如MyOps。在该文件下通过创建MyOp.h文件来添加自定义算子。
若算子存在参数,在MyOp.h中添加参数的实例用于保存相关参数;同时,在src/ppl/common/params/ppl文件下创建myop_param.h,用于添加算子参数的定义。
MyOp.h结构如下:
class MyOp final : public CudaOptKernel {
public:
MyOp(const ir::Node* node) : CudaOptKernel(node) {}
KernelImpl* CreateKernelImpl() const override;
ppl::common::RetCode Init(const OptKernelOptions&) override;
ppl::common::RetCode Finalize(const OptKernelOptions& options) override;
private:
ppl::common::MyOpParam param_;
};
- 添加算子输入输出的数据类型
算子输入输出的数据类型通过ppl::nn::cuda::MyOp::init()中用自定义函数infer_type_func设置。目前有几个通用的函数可以调用:
InferDefaultType(info, type); // 将所有input output设置为指定的type类型
InferHighestType(info, mask); // 选择input中精度最高的类型,将所有input output设置为该类型
InferInheritedType(info); // input保持上层输入的类型,并将output设置为input0的数据类型
用户可以选择合适的函数或者根据实际需求设计独立的函数。指定类型调用示例 (参数type在没有外部指定的情况下,默认为DATATYPE_UNKNOWN)
infer_type_func_ = [this] (InputOutputInfo* info, datatype_t type) -> RetCode {
if (type == ppl::common::DATATYPE_UNKNOWN)
type = ppl::common::DATATYPE_FLOAT16;
return InferDefaultType(info, type);
};
- 添加算子维度计算
算子形状推断通过ppl::nn::cuda::MyOp::init()中以自定义函数infer_dims_func设置。目前框架支持的所有onnx算子的形状推断在ppl/nn/oputils文件夹下,可用于参考。
输出形状继承输入形状的示例:
infer_dims_func_ = [this] (InputOutputInfo* info) -> RetCode {
auto& in_shape0 = info->GetInput<TensorImpl>(0)->GetShape();
info->GetOutput<TensorImpl>(0)->GetShape().Reshape
(in_shape0.GetDims(), in_shape0.GetRealDimCount());
return RC_SUCCESS;
};
- 添加算子的数据排布
目前框架支持两种排布,NDARRAY (NCHW) 和 NHWC,根据这两种排布目前将所有算子的输入输出排布分为四种,新增算子具体使用那种排布可以在ppl/nn/engines/cuda/algos/algo_normal.h文件中设置。
默认设置为算子所有的输入输出都固定为NDARRAY,若自定义算子也使用NDARRAY输入输出的排布,则无需添加任何内容,其它情况操作遵循如下规则:
- 若自定义算子仅支持输入输出为NHWC格式,则需要将自定义算子的名称写入nhwc_set_中;
- 若自定义算子的输出与输入排布保持一致(类似Add算子),则需要将自定义算子的名称写入inherited_set_中;
- 若自定义算子可以接受所有排布的输入并且固定以NDARRAY作为输出(类似Shape算子),则需要将自定义算子的名称写入arbitrary_set_中
此外,当自定义算子包含多种算法实现时,框架支持在预处理阶段选算法,统计每种算法的时间并将最优结果记录下来,让算子可以在执行过程中执行计算效率最高的算法.
添加选算法需要在ppl/nn/engines/cuda/algos文件夹下添加algo_myop.cc和algo_myop.h两个文件,并在algo_filter_manager.cc中进行注册。选算法实现过程可以借鉴alog_conv.h文件中的TuringHMMAImpgemm::ExcuteTimer()函数。
- 添加算子调用接口
在ppl/nn/engines/cuda/kernels文件夹中添加一个新的文件夹MyKernels。在MyKernels中添加自定义算子的调用接口。常规算子只需要构造函数和DoExcute()两个函数;当自定义算子包含参数时,需要添加SetParam()函数。默认的CanDoExcute()函数不允许有空tensor作为输入。当自定义算子支持空tensor输入时需要重写CanDoExcute()函数(例如Resize算子)
调用接口声明示例:
class MyOpKernel : public CudaKernel {
public:
MyOpKernel(const ir::Node* node) : CudaKernel(node) {}
void SetParam(const ppl::common::MyOpParam* p) { param_ = p; }
private:
ppl::common::RetCode DoExecute(KernelExecContext*) override;
private:
const ppl::common::MyOpParam* param_ = nullptr;
};
用户需要手动完成DoExcute()函数,调用自定义算子的cuda实现并将结果写入输出tensor。
- 添加cuda实现
添加cuda算子的流程:
![image]()
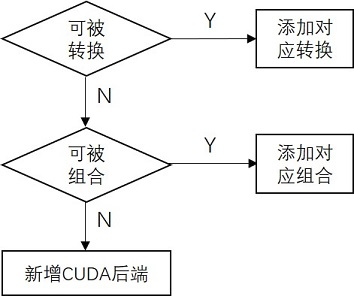
添加算子应秉持转换优先,组合次之,最后再新增后端实现的原则。这样既可以快速完成算子添加,也可以避免新添后端的功能校对和性能优化。这里通过展示OpenPPL中已有算子的实现来介绍三种添加算子的方法。
7.1 算子转换
如果新增算子的功能是已有若干个算子的功能交集,则可以特化已有算子的子功能作为新增算子的特定模式,ONNX.DepthToSpace即是这种情况。在ppl.kernel.cuda/src/nn/depth_to_space.cu中可以看到,DepthToSpace的DCR(depth-column-row)模式可以通过Resahpe+Transpose来实现,而CDR (column-row-depth)和已有算子SubpixelUp的功能是一致的,直接调用即可。
7.2 算子组合
对于无法通过转换实现的算子,可以试图分解算子的计算步骤,然后在每一步骤利用已有算子实现。ONNX.Softmax就可以通过这种方式实现,具体可见ppl.kernel.cuda/src/nn/softmax.cu。可以看到Softmax可以分解为Reduce+Sub+Exp+Reduce+Div五个子步骤,每个步骤都可以在已有算子中找到对应的实现。值得注意的是,为了在不同步骤之间传输数据,需要申请临时存储空间。申请临时空间的接口是ppl.nn/cuda/kernels中的CalcTmpBufferSize(const KernelExecContext& ctx),空间的大小由算子的计算步骤决定。
7.3 新增后端
对于无法通过转换和组合实现的算子,可以新增该算子的CUDA实现。新增后端实现涉及ppl.kernel.cuda中的两个文件,分别是include中的头文件my_kernel.h和src中的实现文件my_kernel.cu。算子接口的命名和形参列表的顺序及类型都应参考已有接口的定义。CMakeLists.txt中已经实现了src目录下的文件搜索,所以无需改动。
8 注册算子
最后需要在ppl/nn/engines/cuda/optimizer/opt_kernel_creator_manager.h中注册自定义算子,domain为域名,默认为空,type为算子类型名称,最后为MyOp.h中定义的算子类型。
若新增域名,BridgeOp需同时加入到新域名中。注册示例:
REGISTER_OPT_KERNEL_CREATOR("new_domain", "Bridge", BridgeOp);
REGISTER_OPT_KERNEL_CREATOR("new_domain", "MyOp", MyOp)
其他的如RISCV/ARM等可参考:https://github.com/openppl-public/ppl.nn

 浙公网安备 33010602011771号
浙公网安备 33010602011771号