网络编程:使用poll单线程处理所有I/O事件
事件驱动模型
事件驱动的好处:占用资源少,效率高,可扩展性强,是支持高性能高并发的不二之选。
事件驱动模型也叫作反应堆模型(reactor),或者是Event loop模型,该模型的核心有两点:
- 1、它存在一个无限循环的事件分发线程,或者叫做reactor线程、Event loop线程。这个事件分发线程的背后,就是poll、epoll等I/O分发技术的使用。
- 所有的I/O操作都可以抽象成事件,每个事件必须有回调函数来处理。acceptor上有连接建立成功、已连接套接字上发送缓冲区空出可以写、通信管道pipe上有数据可以读,这些都是一个个事件,通过事件分发,这些事件都可以一一被检测,并调用对应的回调函数加以处理。
几种I/O模型和线程模型设计
任何一个网络程序,所有的事情可以总结成以下几种:
- read:从套接字收取数据
- decode:对收到的数据进行解析
- compute:根据解析后的内容进行计算和处理
- encode:将处理之后的结果,按照约定的格式进行编码
- send:最后,通过套接字将结果发送出去
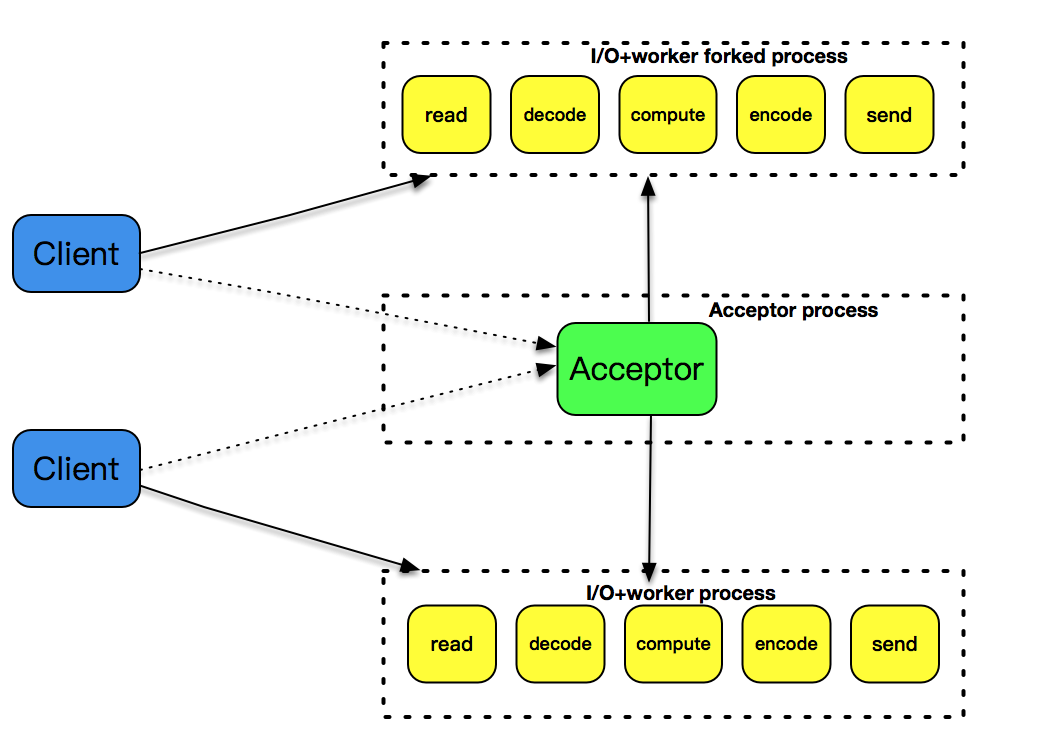
fork
使用fork创建子进程,为每个到达的客户连接服务,如下图,随着客户数的增多,fork的子进程也越来越多,即使客户和服务器之间的交互比较少,这样的子进程也不能被销毁,一直需要存在。虽fork的处理方式简单,但处理效率不高,fork子进程的开销太大。
pthread
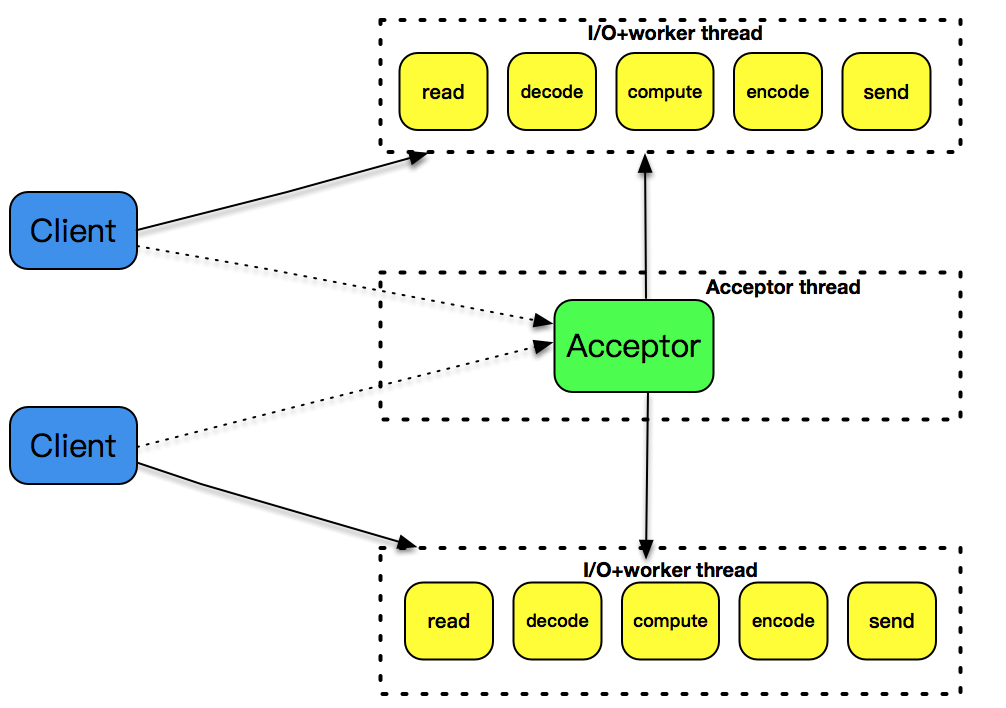
使用了 pthread_create 创建子线程,因为线程是比进程更轻量级的执行单位,所以它的效率相比 fork 的方式,有一定的提高。但是,每次创建一个线程的开销仍然是不小的,因此,引入了线程池的概念,预先创建出一个线程池,在每次新连接达到时,从线程池挑选出一个线程为之服务,很好地解决了线程创建的开销。但是,这个模式还是没有解决空闲连接占用资源的问题,如果一个连接在一定时间内没有数据交互,这个连接还是要占用一定的线程资源,直到这个连接消亡为止。
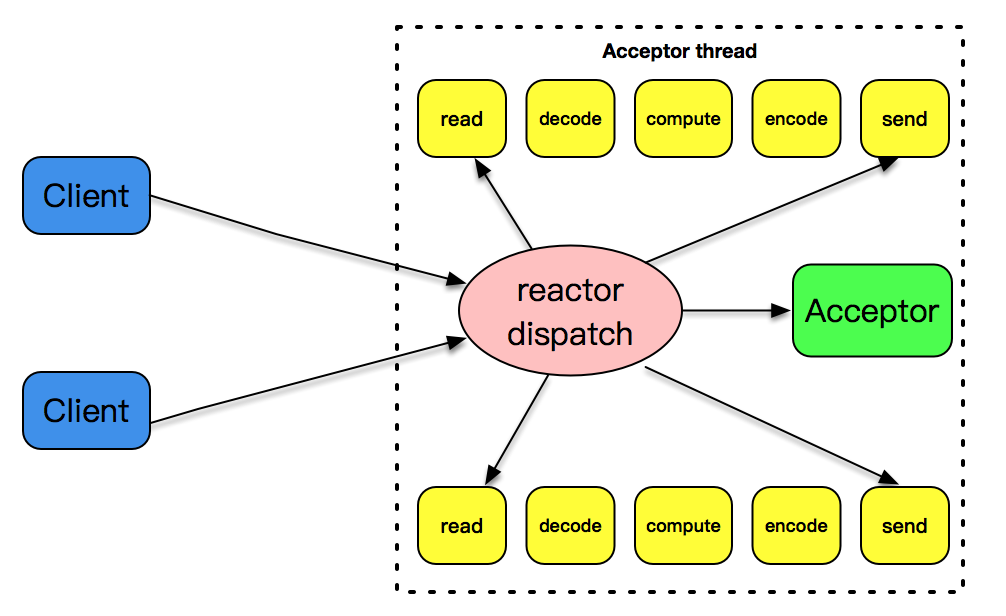
single reactor thread
一个reactor线程上同时负责分发acceptor的实践、已连接套接字的I/O事件。
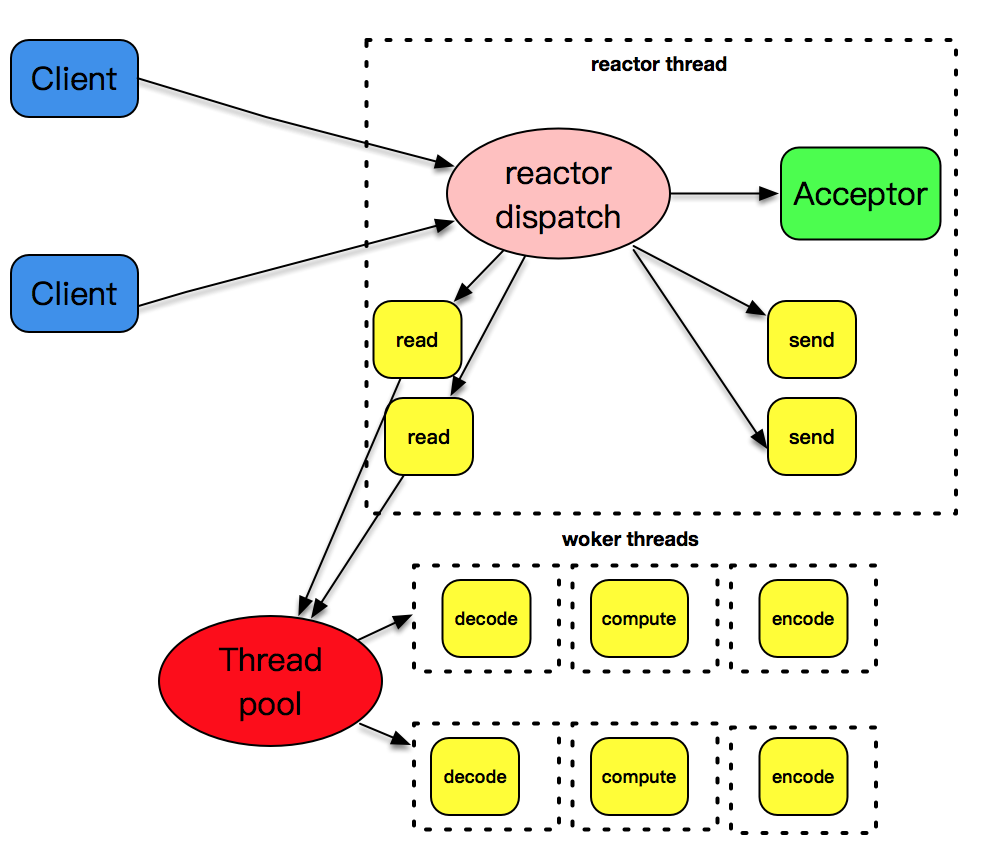
single reactor thread + worker thread
上述的设计模式有个问题,和I/O事件处理相比,应用程序的业务逻辑处理是比较耗时的,比如XML文本的解析、数据库记录的查找、文件资料的读取和传输、计算型工作的处理等,这些工作相对比较独立,它们会拖慢整个反应堆模式的执行效率。
因此,可将decode、compute、encode型工作放置到另外的线程池中,和反应堆线程解耦,是一个比较明智的选择。
反应堆线程只负责处理I/O相关的工作,业务逻辑相关的工作都被裁剪成一个一个的小任务,放到线程池里由空闲的线程来执行。当结果完成后,再交给反应堆线程,由反应堆线程通过套接字将结果发送出去。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号