抓取财报数据
抓取财报数据,主要关注每只股票的EPS(每股收益即每股盈利)、公告日期还有报告日期
确定数据源
从东方财富的数据中心抓取年报季报中的股票数据
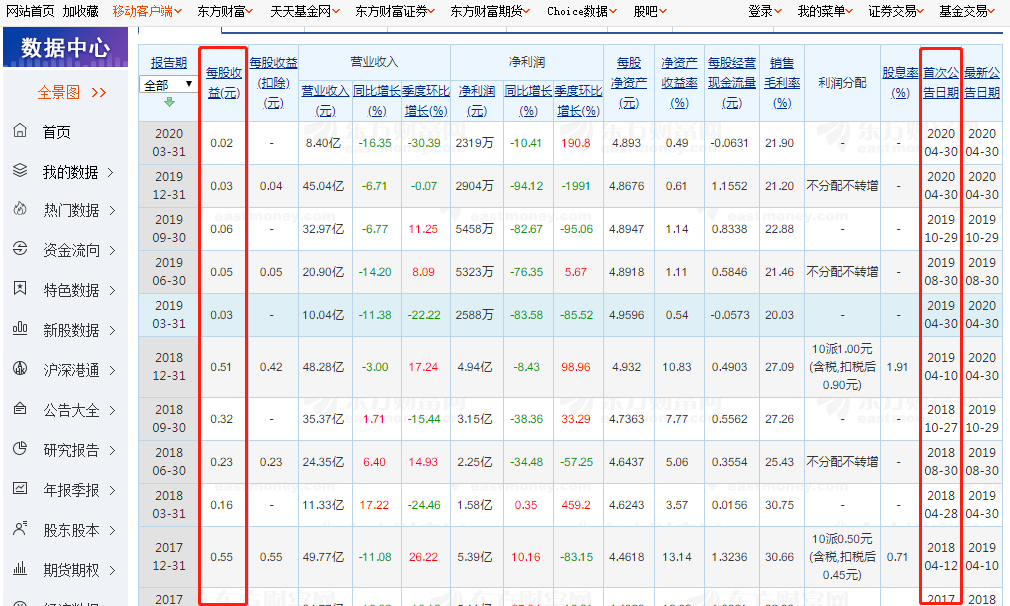
右击、点击检查(或直接按F12)进入开发者模式,点击NetWork导航,重新点击下页面中的报告期,便可得到数据
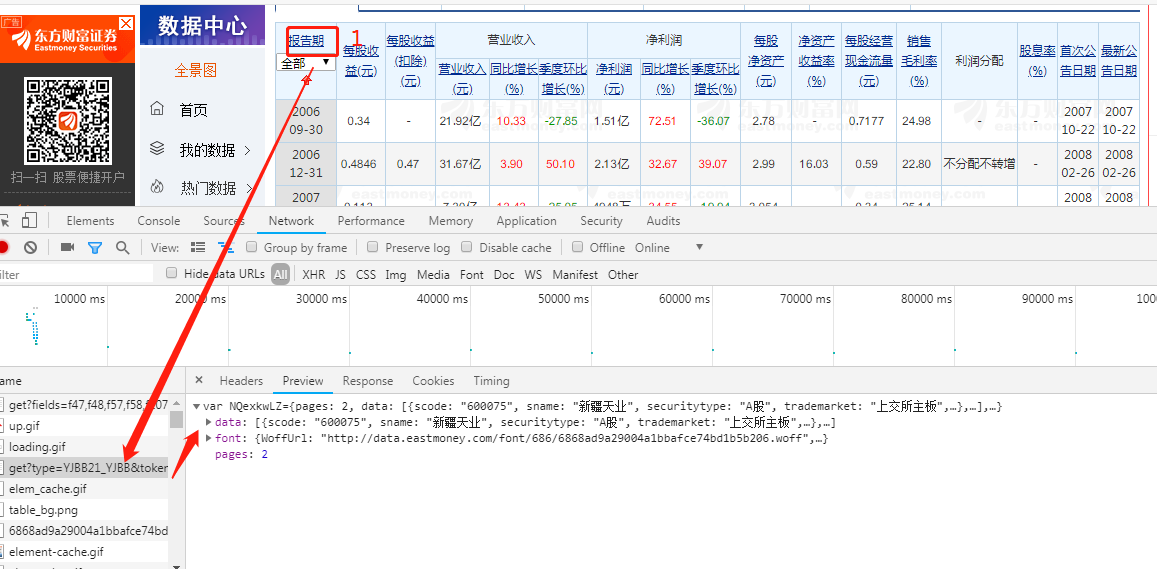
上述便可得到所需财报的抓取地址并进行构造:

观察数据
既然要爬取人家的数据,就要知道它们数据的格式、命名等信息,对数据有个大概的掌握
注意:这里有个问题,现在(2020年)抓取19年年级报表(type=YJBB21_YJBB)发现抓取的其中eps数据是加密的,因此暂时还是用的是(type=YJBB20_YJBB)抓取的数据(解决方案:记录东方财富网的自定义字体反爬)
抓取程序及存储数据
import json
import urllib3
from stock_util import get_all_codes
from pymongo import UpdateOne
from database import DB_CONN
"""
抓取财报数据:主要关注EPS(每股收益即每股盈利)、公告日期、报告期
"""
def crawl_finance_report():
#获取股票列表
codes = get_all_codes()
#抓取的财务地址,scode为股票代码
url = 'http://dcfm.eastmoney.com//em_mutisvcexpandinterface/api/js/get?' \
'type=YJBB20_YJBB&token=70f12f2f4f091e459a279469fe49eca5&st=reportdate&sr=1' \
'&filter=(scode={0})&p={page}&ps={pageSize}&js={"pages":(tp),"data":%20(x)}'
#创建连接池
conn_pool = urllib3.PoolManager()
#循环抓取所有股票的财务信息
for code in codes:
#替换股票代码,抓取该只股票的财务数据
response = conn_pool.request('GET',url.replace('{0}',code))
print(url.replace('{0}',code))
#解析抓取结果
result = json.loads(response.data.decode('UTF-8'))
#取出数据
reports = result['data']
#更新数据库的请求列表
update_requests = []
#循环处理所有报告数据
for report in reports:
doc = {
#报告日期
'report_date':report['reportdate'][:10],
#公告日期
'annouced_date':report['latestnoticedate'][:10],
#每股收益
'eps':report['basiceps'],
'code':code
}
#将更新请求列表添加到列表中,更新时的查询条件为code、report_date,为快速保存数据,需增加索引
#db.finance_report.createIndex({'code':1,'report_date':1})
update_requests.append(
UpdateOne(
{'code':code,'report_date':doc['report_date']},
{'$set':doc},
upsert=True)
)
#如果更新数据的请求列表不为空,则写入数据库
if len(update_requests):
#采用批量写入的方式,加快保存速度
update_result = DB_CONN['finance_report'].bulk_write(update_requests,ordered=False)
print('股票%s ,财报,更新%d条,插入:%d条'%(code,update_result.modified_count,update_result.upserted_count))
if __name__ == "__main__":
crawl_finance_report()
查看数据


 浙公网安备 33010602011771号
浙公网安备 33010602011771号