坦克尼克号存活率预测
主要涉及到的内容有:数据处理(对空白数据进行填充:Imputer)、自定义转换器、pipeline的编写以及采用SVC及RandomForestClassifier进行分类预测
采用的数据集来自Kaggle的坦克尼克号的预测(Titanic challenge )
读取数据
import os TITANIC_Path = os.path.join('datasets','titanic')
import pandas as pd def load_titanic_data(filename,titanic_path = TITANIC_Path): csv_path = os.path.join(titanic_path,filename) return pd.read_csv(csv_path)
train_data = load_titanic_data('train.csv') test_data = load_titanic_data('test.csv')
train_data.head()

查看数据信息:
train_data.info()
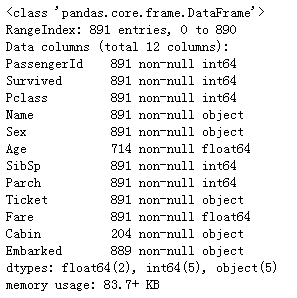
train_data.describe()
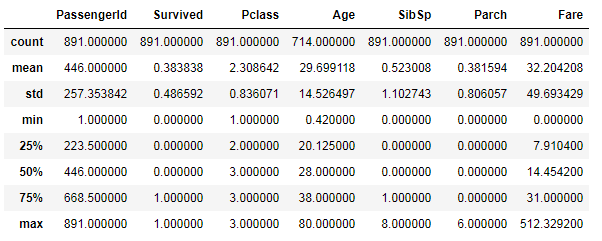
使用value_counts()查看属性出现的次数
train_data['Survived'].value_counts()
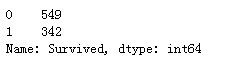
train_data['Pclass'].value_counts()
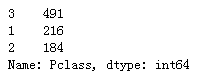
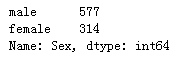
train_data['Sex'].value_counts()
进行转换器的编写,需要继承BaseEstimator以及TransformerMixin两个类,需要实现fit方法以及transform方法
from sklearn.base import BaseEstimator,TransformerMixin class DataFrameSelector(BaseEstimator,TransformerMixin): def __init__(self,attribute_names): self.attribute_names = attribute_names def fit(self,X,y = None): return self def transform(self,X): return X[self.attribute_names]
转换器DataFrameSelector用于选择某个属性的数据
通过pipeline将数据传给DataFrameSelector中进行数据的筛选
from sklearn.pipeline import Pipeline from sklearn.preprocessing import Imputer num_pipline = Pipeline([ ('select_numeric',DataFrameSelector(['Age','SibSp','Parch','Fare'])), ('imputer',Imputer(strategy = 'median')), ])
在执行fit_transform()方法时,先执行了fit方法,将属性Age、SibSp、Parch、Fare传给了DataFrameSelector,返回这属性的数据,并将数据通过Imputer对空白数据进行填充
s =num_pipline.fit_transform(train_data)
s

s.shape

可看到Age原本只有714条为非空数据,现在都是891条数据了
Imputer仅对数字型的数据具有数据填充的功能,但对字符型的它真是有点爱莫能助了,但方法总比困难多
class MostFrequentImputer(BaseEstimator,TransformerMixin): def __init__(self): pass def fit(self,X,y = None): self.most_frequent_ = pd.Series([X[c].value_counts().index[0] for c in X],index = X.columns) # print([X[c].value_counts().index[0] for c in X]) return self def transform(self,X,y = None): return X.fillna(self.most_frequent_)
MostFrequentImputer转换器作用是将出现频率最多的作为填充数据,对空白数据进行填充
这里还要注意到:读取表头的方法,也是令我耳目一新,[X[c].value_counts().index[0] for c in X],可以对它进行化简
[c for c in train_data]
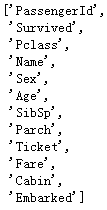
可以专门把表头给读取出来
还有需要对pd.Series()方法进行介绍:
Pandas是基于Series和DataFrame两种数据类型的。
参考:https://blog.ouyangsihai.cn/%2Fpandas-jiao-cheng-series-he-dataframe.html
Series:一种类似于一维数组的对象,是由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成
DataFrame:一个表格型的数据结构,包括有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame既有行索引也有列索引,可以被看做是由Series组成的字典。
Series:一个Series是一个一维的数据类型,其中每一个元素都有一个标签。类似于Numpy中元素带标签的数组,其中标签可以是数组或者是字符串
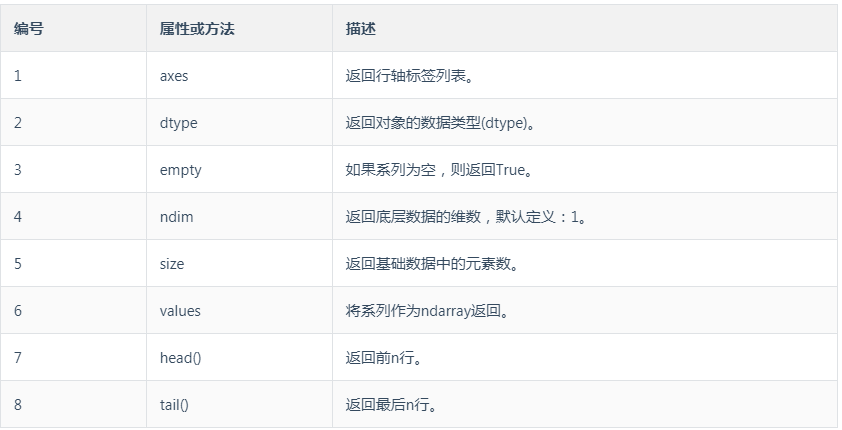
Series的属性:
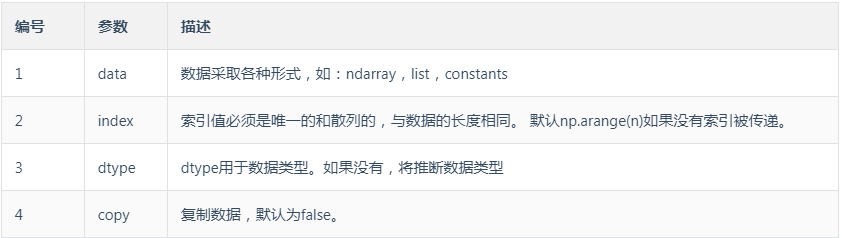
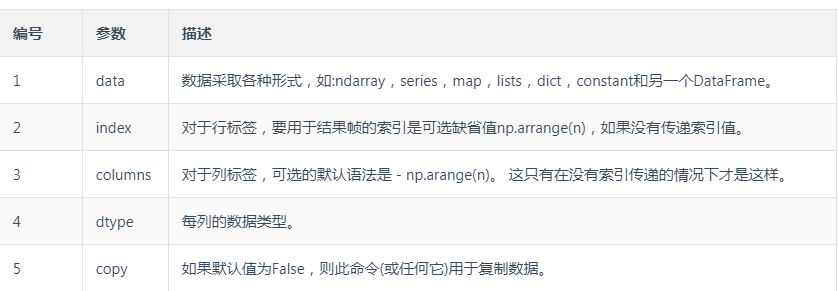
pandas.Series(data,index,dtype,copy)
创建Series的方式,可以通过一维数组方式、ndarray、字典创建Series
Series值的获取:有两种方式
1、通过方括号+索引的方式读取对应的索引的数据,有可能返回多条数据
2、通过方括号+下标值的方式读取对应下标值的数据,下标值的取值范围为:[0,len(Series.values)];另外下标值也可以是负数,表示从右往左获取数据
DataFrame:一个DataFrame是一个二维的表结构。Pandas的DataFrame可以存储许多不同的数据类型,并且每一个坐标轴都有自己的标签
DataFrame的属性
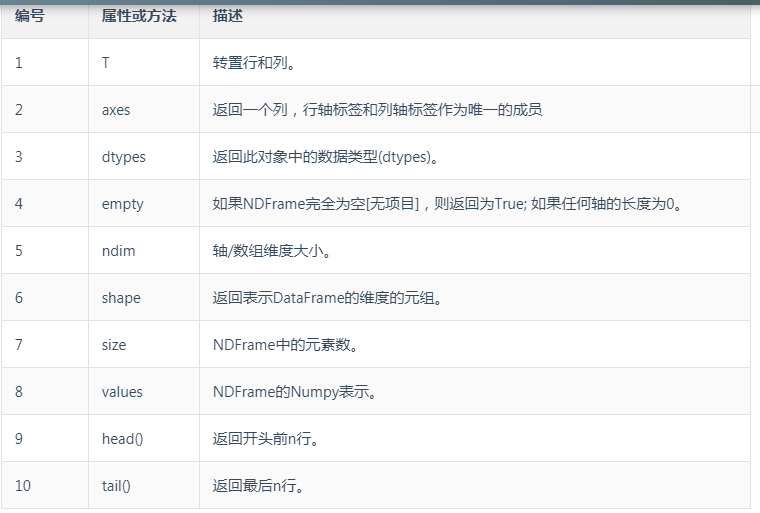
DataFrame的创建:使用构造函数
- pandas.DataFrame( data, index, columns, dtype, copy)
参考:https://blog.ouyangsihai.cn/%2Fpandas-jiao-cheng-series-he-dataframe.html
言归正传,字符串的数据在做训练的时候,很多分类器是不支持的,因此,需要进行OneHot编码
from sklearn.preprocessing import OneHotEncoder cat_pipeline = Pipeline([ ('select_cat',DataFrameSelector(['Pclass','Sex','Embarked'])), ('imputer',MostFrequentImputer()), ('cat_encoder',OneHotEncoder(sparse = False)) ])
a = cat_pipeline.fit_transform(train_data)
a

现在,数字型的数据处理好了,字符串的数据也处理好了,需要重新将这两部分数据整合,进行训练
from sklearn.pipeline import FeatureUnion preprocess_pipeline = FeatureUnion(transformer_list=[ ('num_pipeline',num_pipline), ('cat_pipeline',cat_pipeline) ])
X_train = preprocess_pipeline.fit_transform(train_data)
X_train

不要忘了,获取标签,这对监督学习非常重要
y_train = train_data['Survived']
进行SVC(就是使用SVM做分类任务)分类训练
from sklearn.svm import SVC svm_clf = SVC(gamma = 'auto') svm_clf.fit(X_train,y_train)
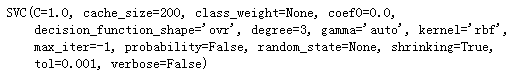
训练之后,想尝试下在测试集上的效果,也需要将测试集执行下上述的pipeline操作
X_test = preprocess_pipeline.transform(test_data)
y_pred = svm_clf.predict(X_test)
现在来看下交叉验证集的效果
from sklearn.model_selection import cross_val_score svm_scores = cross_val_score(svm_clf,X_train,y_train,cv = 15) svm_scores.mean()
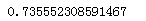
现在来尝试下随机森林(介绍下RandomForestClassifier的参数,参考:https://blog.csdn.net/u012102306/article/details/52228516)
//RandomForestClassifier的参数
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, crite-rion=’gini’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=’auto’, max_leaf_nodes=None, bootstrap=True, oob_score=False, n_jobs=1, ran-dom_state=None, verbose=0, warm_start=False, class_weight=None)
其中关于决策树的参数:
criterion: ”gini” or “entropy”(default=”gini”)是计算属性的gini(基尼不纯度)还是entropy(信息增益),来选择最合适的节点。
splitter: ”best” or “random”(default=”best”)随机选择属性还是选择不纯度最大的属性,建议用默认。
max_features: 选择最适属性时划分的特征不能超过此值。
当为整数时,即最大特征数;当为小数时,训练集特征数*小数;
if “auto”, then max_features=sqrt(n_features).
If “sqrt”, thenmax_features=sqrt(n_features).
If “log2”, thenmax_features=log2(n_features).
If None, then max_features=n_features.
max_depth: (default=None)设置树的最大深度,默认为None,这样建树时,会使每一个叶节点只有一个类别,或是达到min_samples_split。
min_samples_split:根据属性划分节点时,每个划分最少的样本数。
min_samples_leaf:叶子节点最少的样本数。
max_leaf_nodes: (default=None)叶子树的最大样本数。
min_weight_fraction_leaf: (default=0) 叶子节点所需要的最小权值
verbose:(default=0) 是否显示任务进程
关于随机森林特有的参数:
n_estimators=10:决策树的个数,越多越好,但是性能就会越差,至少100左右(具体数字忘记从哪里来的了)可以达到可接受的性能和误差率。
bootstrap=True:是否有放回的采样。
oob_score=False:oob(out of band,带外)数据,即:在某次决策树训练中没有被bootstrap选中的数据。多单个模型的参数训练,我们知道可以用cross validation(cv)来进行,但是特别消耗时间,而且对于随机森林这种情况也没有大的必要,所以就用这个数据对决策树模型进行验证,算是一个简单的交叉验证。性能消耗小,但是效果不错。
n_jobs=1:并行job个数。这个在ensemble算法中非常重要,尤其是bagging(而非boosting,因为boosting的每次迭代之间有影响,所以很难进行并行化),因为可以并行从而提高性能。1=不并行;n:n个并行;-1:CPU有多少core,就启动多少job
warm_start=False:热启动,决定是否使用上次调用该类的结果然后增加新的。
class_weight=None:各个label的权重。
进行预测可以有几种形式:
predict_proba(x):给出带有概率值的结果。每个点在所有label的概率和为1.
predict(x):直接给出预测结果。内部还是调用的predict_proba(),根据概率的结果看哪个类型的预测值最高就是哪个类型。
predict_log_proba(x):和predict_proba基本上一样,只是把结果给做了log()处理。
from sklearn.ensemble import RandomForestClassifier forest_clf = RandomForestClassifier(n_estimators=100,random_state = 42) forest_scores = cross_val_score(forest_clf,X_train,y_train,cv = 15) forest_scores.mean()

达到了80%,还是可以的
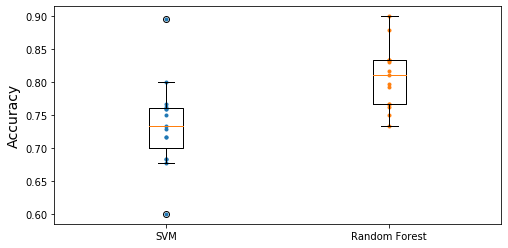
现在来对这两种方案进行可视化操作
import matplotlib.pyplot as plt plt.figure(figsize = (8,4)) plt.plot([1]* 15,svm_scores,'.') plt.plot([2]* 15,forest_scores,'.') plt.boxplot([svm_scores,forest_scores],labels=('SVM','Random Forest')) plt.ylabel("Accuracy",fontsize = 14) plt.show()
当然,也可以将属性进行处理后进行训练,也许会得到不错的效果
#分组 train_data['AgeBucket'] = train_data['Age'] // 15 * 15 train_data[['AgeBucket','Survived']].groupby(['AgeBucket']).mean()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号