性能评价指标
1、精确度
cross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring="accuracy") array([ 0.909 , 0.90715, 0.9128 ])
尤其当处理有偏差的数据集时,比如其中一些类比其他类频繁的多,精确度不是一个好的性能度量指标。
2、混淆矩阵
对于分类器来说,一个好得多的性能评价指标是混淆矩阵。大致思路是:输出类别A被分类成类别B的次数。
为了计算混淆矩阵,首先需要有一系列的预测值,这样才能将预测值与真实值比较。你或许想在测试集上做预测,但先不要用它(记住,只有当项目处于尾声,当你准备上线一个分类器的时候,你才应该使用测试集),相反,你应该使用cross_val_predict()函数
from sklearn.model_selection import cross_val_predict y_train_pred = cross_val_predict(sgd_clf,X_train,y_train_5,cv = 3)
from sklearn.metrics import confusion_matrix confusion_matrix(y_train_5,y_train_pred)

就像cross_val_score(),cross_val_predict()也是使用K折交叉验证。它不是返回一个评估分数,而是返回基于每一个测试折做出的预测者。这意味着,对于每一个训练集的样例,你得到一个赶紧的预测(“干净”是说一个模型在训练过程中没有使用测试集的数据)
再使用confusion_matirx()函数,你将得到混淆矩阵。
y_train_perfect_prediction = y_train_5
confusion_matrix(y_train_5,y_train_perfect_prediction)

但针对cross_val_predict()与cross_val_score()之间的不同,感觉还是有必要进一步说明:(参考:https://zhuanlan.zhihu.com/p/90451347)
虽然cross_val_score和cross_val_predict的分片方式是相同的,但区别在于cross_val_predict的返回值不能直接用于计算得分标准!!官网已注明

意思是说,cross_val_score是取K折交叉验证的平均值,而cross_val_predict只是简单的返回了几个不同模型的标签或概率,因此,cross_val_predict不适合做泛化误差的适当度量。
查看源码cross_val_predict:

把这些test_y放在一起看看预测没问题,但是放在一起进行评价得分,不合适
为什么呢?
对比cross_val_score,发现道理很简单。
当我们使用cross_val_predict计算得分时候,将采用与cross_val_score不同的计算策略,即:
cross_val_score为先分片计算得分,然后平均:
score = np.mean(cross_val_score(estimator, data_x, y, cv=5))
cross_val_predict为所有统一计算:
predict_y = cross_val_predict(estimator, data_x, y, cv=5)
score = r2_score(true_y,predict_y)
cross_val_score分片计算后平均的这种方式,可以认为是不同模型的平均结果
cross_val_predict计算得分没有道理可言。
而且,这两种计算结果在数据量小的时候差别很大,所以遵循官网警告,谢绝使用cross_val_predict计算得分。
言归正传,一个完美的分类器将只有真反例和真正例,所以混淆矩阵的非零值仅在其对角线(左上至右下)
一个混淆矩阵可以提供很多信息,一个有趣的指标是正例预测的精度,也叫作分类器的准确率(precision)
3、分类器的准确率与召回率
公式:准确率
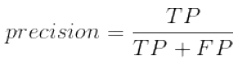
其中TP是真正例的数目,FP是假正例的数目
想要一个完美的准确率,一个平凡的方法是构造一个单一正例的预测和确保这个预测是正确的(precision = 1/1 = 100%)。因为分类器会忽略所有样例,除了那一个正例,所以准确率一般会伴随另外一个指标使用,这个指标叫召回率(recall),也叫作敏感度(sensitivity)或真正例率(true positive rate,TPR)。这是正例被分类器正确探测出的比率。
recall公式:

FN是假反例的数目
如果对混淆矩阵感到困惑,混淆矩阵示意图如下:
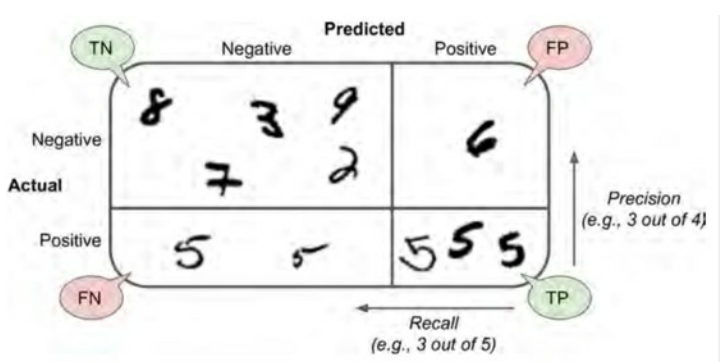
sklearn提供了一些函数用于计算分类器的指标,包括准确率和召回率
from sklearn.metrics import precision_score,recall_score precision_score(y_train_5,y_train_pred),recall_score(y_train_5,y_train_pred)
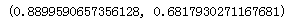
当你去观察精度的时候,你的“数字5探测器”看起来还不够好,当它声明某张图片是5的时候,它只有89%的可能是正确的,而且,它也只检测出“是5”类图片当中的69%。
4、F1 Score
通常结合准确率和召回率会更加方便,这个指标就是“F1 值”,特别是当你需要一个简单的方法去比较两个分类器的优劣的时候。F1 值是准确率和召回率的调和平均。普通的平均值平等的看待所有的值,而调和平均会给小的值更大的权重,所以,想要分类器得到一个高的F1值,需要召回率和准确度同时高。
F1值公式:
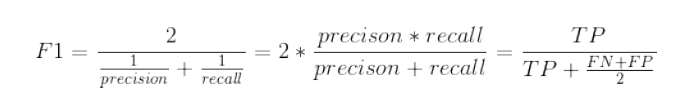
为计算F1值,可简单调用f1_score()
from sklearn.metrics import f1_score f1_score(y_train_5,y_train_pred)
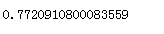
F1支持那些有着相近准确率和召回率的分类器。这不会总是你想要的。有的场景你会绝大程度地关心准确率,而另外一些场景你会更关心召回率。举例子,如果你训练一个分类器去检测视频是否适合儿童观看,你会倾向选择那种即便拒绝了很多好视频、但保证所保留的视频都是好(高准确率)的分类器,而不是那种高召回率、但让坏视频混入的分类器(这种情况下你或许想增加人工去检测分类器选择出来的视频)。另一方面,加入你训练一个分类器去检测监控图像当中的窃贼,有着 30% 准确率、99% 召回率的分类器或许是合适的(当然,警卫会得到一些错误的报警,但是几乎所有的窃贼都会被抓到)。
不幸的是,你不能同时拥有两者。增加准确率会降低召回率,反之亦然。这叫做准确率与召回率之间的折衷。
5、准确率/召回率之间的折衷
为了弄懂这个折衷,先看下SGDCLassifier是如何做分类决策的。对于每个样例,它根据决策函数计算分数,如果这个分数大于一个阈值,它会将样例分配给正例,否则它将分配给反例。sklearn不让你直接设置阈值,但是它给你提供了设置决策分数的方法,这个决策分数用来产生预测。它不是调用分类器的predict()方法,而是调用decision_function()方法。这个方法返回每一个样例的分数值,然后基于这个分数值,使用你想要的任何阈值做出预测。
y_scores = sgd_clf.decision_function([some_digit])
y_scores
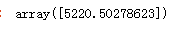
这是对数字5分类器产生的阈值,当超过5220.5时就会将结果分为非5行列
threshold = 0 y_some_digit_pred = (y_scores > threshold) y_some_digit_pred

threshold = 5220 y_some_digit_pred = (y_scores > threshold) y_some_digit_pred

当分类器大于5220.5时,分类器就不能探测到这是数字5
那么,应该如何使用哪个阈值呢?首先,需要再次使用cross_val_predict()得到每一个样例的分数值,但是这一次指定返回一个决策分数,而不是预测值。
y_scores = cross_val_predict(sgd_clf,X_train,y_train_5,cv = 3,method = 'decision_function')
现在有了这些分数值,对于任何可能的阈值,使用precision_recall_curve(),都可以计算准确率和召回率:
from sklearn.metrics import precision_recall_curve precisions,recalls,thresholds = precision_recall_curve(y_train_5,y_scores)
最后,可以使用matplotlib画出准确率和召回率,这里将准确率和召回率当做阈值的一个函数
def plot_precision_recall_vs_threshold(precisions,recalls,thresholds): plt.plot(thresholds,precisions[:-1],"b--",label= "Precision",linewidth = 2) plt.plot(thresholds,recalls[:-1],'g-',label = 'Recall',linewidth = 2) plt.xlabel('Threshold',fontsize = 16) plt.legend(loc = 'upper left',fontsize = 16) plt.ylim([0,1]) plot_precision_recall_vs_threshold(precisions,recalls,thresholds) plt.show()
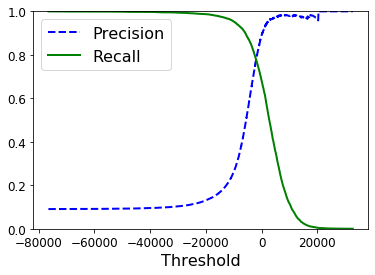
现在你可以选择适合你任务的最佳阈值。
另一个选出好的准确率/召回率这种的方法是直接画出准确率对召回率的曲线
def plot_precision_vs_recall(precisions,recalls): plt.plot(recalls,precisions,'b-',linewidth = 2) plt.xlabel("recall") plt.ylabel('precision') plt.axis([0,1,0,1]) plt.figure(figsize=(8,8)) plot_precision_vs_recall(precisions,recalls) save_fig("precision_vs_recall_plot") plt.show()
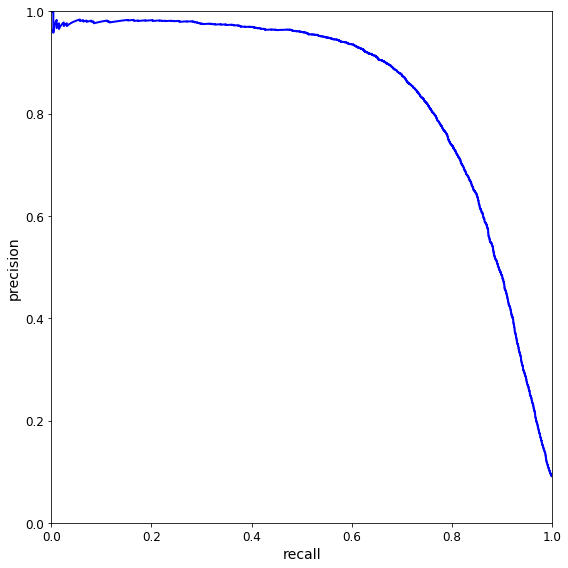
可以看到,在召回率在80%左右的时候,准确率急剧下降。你可能会想选择在急剧下降之前选择出一个准确率/召回率折衷点。比如说,在召回率 60% 左右的点。当然,这取决于你的项目需求。
6、ROC曲线
受试者工作特征(ROC)曲线是另一个分类器使用的常用工具。它非常类似于准确率/召回率曲线,但不是画出准确率对召回率的曲线,ROC曲线是真正例率(true positive rate,另一个名字叫做召回率)对假正例率(false positive rate,FPR)的曲线。FPR是反例被错误分成正例的比例。它等于1减去真反例率(true positive rate,TNP)。TNP是反例被正确分类的比率。TNR也叫作特异性。所以ROC曲线画出召回率对(1减特异性)的曲线。
为了画出ROC曲线,需要首先计算下各种不同阈值下的TPR、FPR,使用roc_curve()函数:
from sklearn.metrics import roc_curve fpr,tpr,threshold =roc_curve(y_train_5,y_scores)
用matplotlib话FPR对TPR的曲线
def plot_roc_curve(fpr,tpr,label = None): plt.plot(fpr,tpr,linewidth = 2,label= label) plt.plot([0,1],[0,1],'k--') plt.axis([0,1,0,1]) plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plot_roc_curve(fpr,tpr) plt.show()
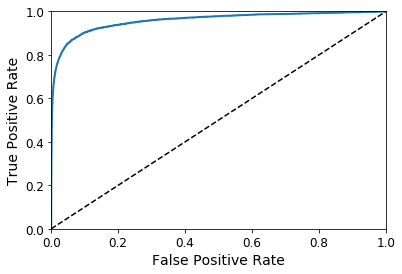
这里同样存在折衷的问题:召回率(TPR)越高,分类器就会产生越多的假正例(FPR)。图中的点线是一个完全随机的分类器生成的ROC曲线;一个好的分类器的ROC曲线应该尽可能远离这条线(即向左上角靠拢)
一个比较分类器之间优劣之间优劣的方法是:测量ROC曲线下的面积(AUC)。一个完美的分类器的ROC AUC等于1,而一个纯随机分类器的ROC AUC等于0.5.Sklearn提供了一个函数用来计算ROC AUC:
from sklearn.metrics import roc_auc_score roc_auc_score(y_train_5,y_scores)
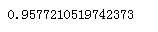
因为 ROC 曲线跟准确率/召回率曲线(或者叫 PR)很类似,你或许会好奇如何决定使用哪一个曲线呢?一个笨拙的规则是,优先使用 PR 曲线当正例很少,或者当你关注假正例多于假反例的时候。其他情况使用 ROC 曲线。举例子,回顾前面的 ROC 曲线和 ROC AUC 数值,你或许认为这个分类器很棒。但是这几乎全是因为只有少数正例(“是 5”),而大部分是反例(“非 5”)。相反,PR 曲线清楚显示出这个分类器还有很大的改善空间(PR 曲线应该尽可能地靠近右上角)。
现在来训练一个RandomForestClassifier,然后拿它的ROC曲线和ROC AUC数值与SGDClassifier进行比较
from sklearn.ensemble import RandomForestClassifier forest_clf = RandomForestClassifier(random_state=42) y_probas_forest = cross_val_predict(forest_clf,X_train,y_train_5,cv = 3,method='predict_proba')
RandomForestClassifier 不提供 decision_function() 方法。相反,它提供了 predict_proba() 方法。Skikit-Learn分类器通常二者中的一个。 predict_proba() 方法返回一个数组,数组的每一行代表一个样例,每一列代表一个类。数组当中的值的意思是:给定一个样例属于给定类的概率,比如70%的概率这幅图是数字5
y_scores_forest = y_probas_forest[:,1]
fpr_forest,tpr_forest,threshold_forest =roc_curve(y_train_5,y_scores_forest)
plt.plot(fpr,tpr,'b:',label= "SGD") plot_roc_curve(fpr_forest,tpr_forest,'Random Forest') plt.legend(loc = 'bottom right') plt.show()
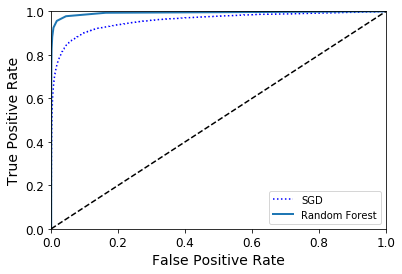
如你所见,RandomForestClassifier的ROC曲线比SGDClassifier好得多:它更靠近左上角,所以,它的ROC AUC也会更大
roc_auc_score(y_train_5,y_scores_forest)
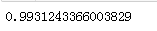
计算下它的准确率好召回率:98.5%的准确率,82.8的召回率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号