学习笔记:SSTBAN 用于长期交通预测的自监督时空瓶颈注意力
Self-Supervised Spatial-Temporal Bottleneck Attentive Network for Efficient Long-term Traffic Forecasting
用于高效长期交通预测的自监督时空瓶颈注意力网络
期刊会议:ICDE2023
论文地址:https://ieeexplore.ieee.org/document/10184658
代码地址:https://github.com/guoshnBJTU/SSTBAN
长期交通预测存在的问题:
- 难以平衡准确率和效率。随着时间跨度增大,要么无法捕捉长期动态性,要么以二次计算复杂度为代价获取全局接受域。
- 高质量的训练数据需求与模型的泛化能力的矛盾。如何提升数据的利用效率值得思考。
SSTBAN采用多任务框架,结合自监督学习器对历史交通数据产生鲁棒的潜在表示,从而提高其泛化性能和预测的鲁棒性。此外,作者还设计了一个时空瓶颈注意机制,在编码全局时空动态的同时降低了计算复杂度。
长期预测需求分析:
与有助于及时决策的短期预测相比,长期预测为旅行者和管理员提供了必要的支持信息,以优化旅行计划和运输资源管理。特别是未来几个小时的流量预测信息,有助于用户提前制定路由计划。
选择注意力机制的原因:
目前STGNNs分为RNN-based,CNN-based和attention-based方法。RNN-based存在梯度消失问题,不利于长期预测,且序列顺序的预测方式使得模型训练时间随着预测时间线性增加;CNN-based的kernel大小限制了长期动态性的捕捉能力;Attention-based更灵活,不会受到空间和时间距离的影响,但是存在二次计算复杂度的问题,这是要解决的问题。
数据的利用效率:高质量数据需求与泛化性矛盾
现有方法普遍有较强的高质量数据需求,当训练数据存在噪声时,就会导致过拟合或是学习到虚假的关系,泛化能力不佳。于是引入了常用于NLP和CV中的自监督学习。这要正确认知NLP/CV和时空交通预测的区别:
- NLP/CV中的基础模式,如形状和语义,在广泛数据集中是通用的;而交通数据集中则鲜有这样的共同特征,比如可能数据的特征都不一样。
- NLP只需捕捉序列特征——即时间,CV只需要捕捉空间特征,但是STGNN要同时捕捉时空特征。
贡献:
- 第一次提出了一种采用自监督学习器的时空交通预测模型,满足了泛化和鲁棒需求。
- 设计了一种时空瓶颈注意力机制,能够高效捕捉长期时空动态,将时间复杂度由二次方降低至线性。(RNN:?)
- 在九个数据集上进行了实验,证明了在精度和效率上的优势。
模型
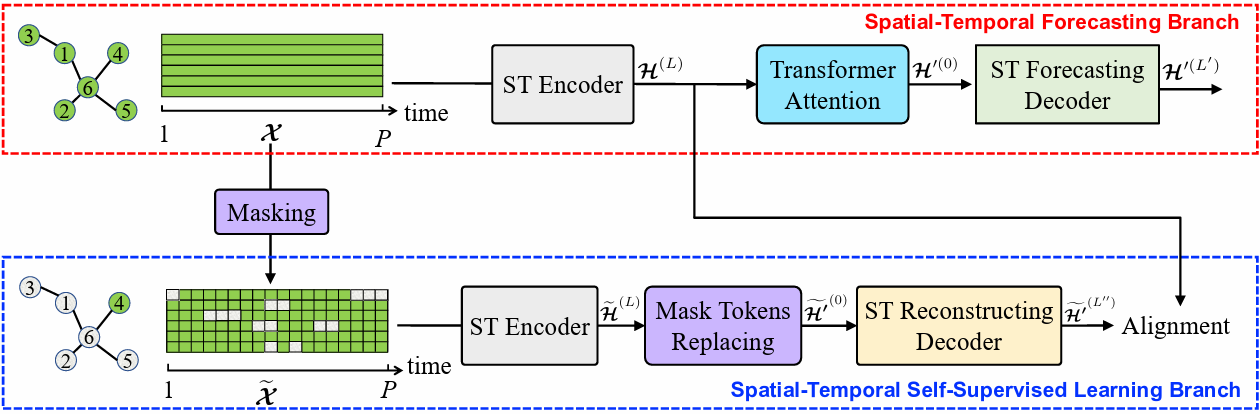 |
|---|
| 图: SSTBAN架构 |
模型包含两个分支:第一个是时空预测分支,第二个是时空自监督学习分支,因此是个多任务框架。
在训练阶段,两个分支一起工作。在分支一中,原始的数据依次经过ST Encoder、Transformer Attention,最后由ST Forecasting Decoder预测;在分支二中,首先随机mask掉一些数据,将破损的数据经过ST Encoder来用剩余的数据提取特征,经过ST Reconstruction Decoder来补全丢掉的数据,并将补全的数据和分支一的完整数据进行对齐比较(为了避免噪声的影响,这里的比较是放在了潜在空间中的)。训练损失也包含了两个,一个是预测误差的MAE,另一个是对齐的MSE。
在两个分支中,encoder和两个decoder由一样的时空瓶颈注意力模块(STBA)和时空嵌入模块(STE)构成。
STBA目的是捕捉长期的时空动态性,且维持低的计算复杂度。
STE目的是提取不同时间切片和节点的独特性,来弥补基于注意力机制的STBA对顺序的不敏感缺点。我们通过端到端的方式训练空间嵌入\(E_{SP}\in R^{N\times d}\),它在所有时间中共享;通过time-of-day和day-of-week,用one-hot和MLPs得到输入时间嵌入\(E_{TP}\in R^{P\times d}\)和输出时间嵌入\(E_{TP}'\in R^{Q\times d}\),它在所有节点中共享;将它们相加得到输入序列嵌入\(\mathcal{E}\in R^{P\times N\times d}\)和输入序列嵌入\(\mathcal{E}'\in R^{Q\times N\times d}\)。
时空瓶颈注意力 STBA
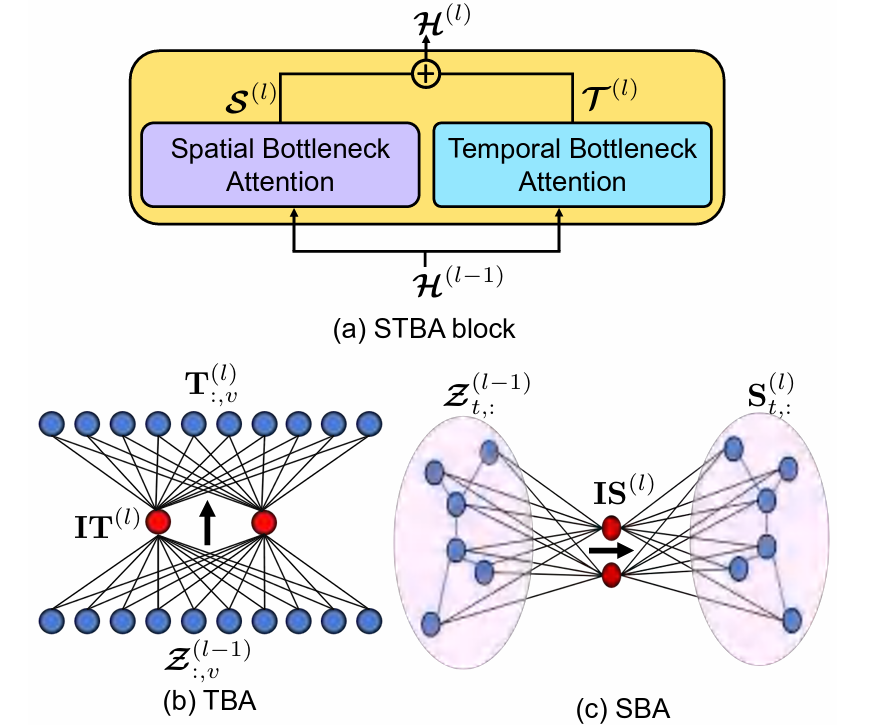 |
|---|
| 图: 时空瓶颈注意力STBA,时间瓶颈注意力TBA,空间SBA |
图中\(\mathcal{Z}^{(l-1)}=(\mathcal{H}^{(l-1)}||\mathcal{E})\in\mathbb{R}^{P\times N\times2d}\)。
STBA包含了空间注意力(SBA)和时间注意力(TBA)。它们并没有直接和其他点相连,而是和参考点相连,而参考点的数量远小于时间点和空间点。我们还希望参考点能够编码通用的全局信息。由于整体形状像瓶颈而得名。
TBA平行地处理每个点的输入。(这里的过程还不是很懂。)
STBA具有以下特点:
- 由于参考点的设置,运算复杂度从\(O(N^2)\)降低到了\(O(NN')\),因为\(N'\)是个小的超参数。相比于GCN,STBA不需要预定义的图结构,同时能动态调整节点间关系强度。
- 参考点起到了编码全局模式的作用,可以理解输入,如用来聚类。
时空预测分支
 |
|---|
| 图:分支一 时空预测分支结构 |
组成部分:
(1)时空编码器:由时空瓶颈注意力组成,映射到潜在表征空间
(2)Transformer attention:将潜在空间下的历史信号适配于预测信号尺寸。为了缓解长期预测存在的比较严重的误差传播问题,我们通过自适应地融合历史中的不同特征,用注意力机制直接把每步的历史信号和预测信号连接起来。即
(3)时空预测解码器:由若干层时空瓶颈注意力,最后加上全连接层组成。
时空自监督学习分支
这一分支从mask掉部分信号的不完整数据中,理解时空关系,并在潜在空间中重构缺失的信号。目的是训练潜在空间表征能力。包括如下部分:
(1)Masking:考虑到mask掉单独一个时间点的数据,很容易通过前后数据算出来,因此在时间或空间维度上mask掉连续的段,以此来学习趋势模式。Mask策略是,将输入数据分成若干patch,并将一定比例的patch全部清0。
 |
|---|
| 图:Masking算法 |
(2)时空编码器:和分支一中的一样。只是,被mask掉的数据不参与时空瓶颈注意力的计算。
(3)时空重构编码器:输入(2)提供的残缺潜在表征,以及指示mask位置的token向量。由若干时空瓶颈组成,并将重构后的表征与分支一的完整表征匹配。
实验
数据集
分别是Seattle Loop,PEMS04, PEMS08
这个Seattle Loop我还是第一次见。
Loop Seattle 数据集由部署在西雅图地区高速公路(I-5、I-405、I-90和SR-520)上的感应环路探测器收集,包含来自323个传感器站的交通状态数据。
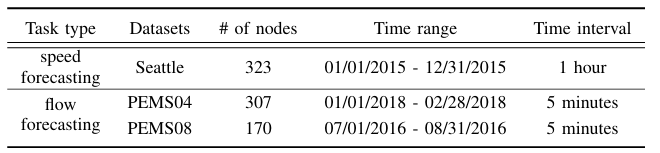 |
|---|
| 图:数据集信息 |
超参数表
\(L\):ST Encoder中STBA的数量
\(L'\):STF Decoder中STBA的数量
\(d\):多头注意力机制的维数
\(h\):多头注意力机制的头数
\(l_m\):Masking过程的patch length
\(\alpha_m\):Masking过程的mask率
\(\lambda\):预测损失和对齐损失的权重。越大代表对齐损失占比越大。
时间和空间参考点的数量都是3。
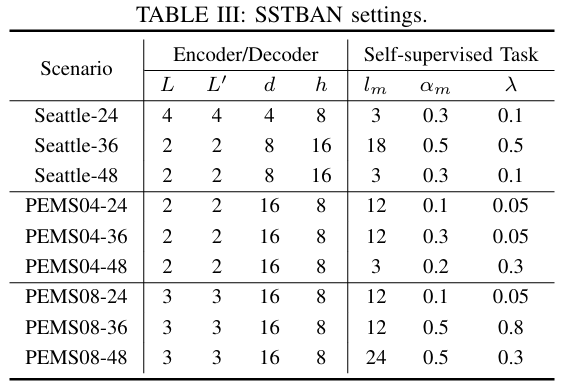 |
|---|
| 图:超参数设置 |
对比试验
实际上作者选的这些基线模型都比较老,说服力比较差。我在本文的最后放上了自己做的一点对比实验,可以当作参考。
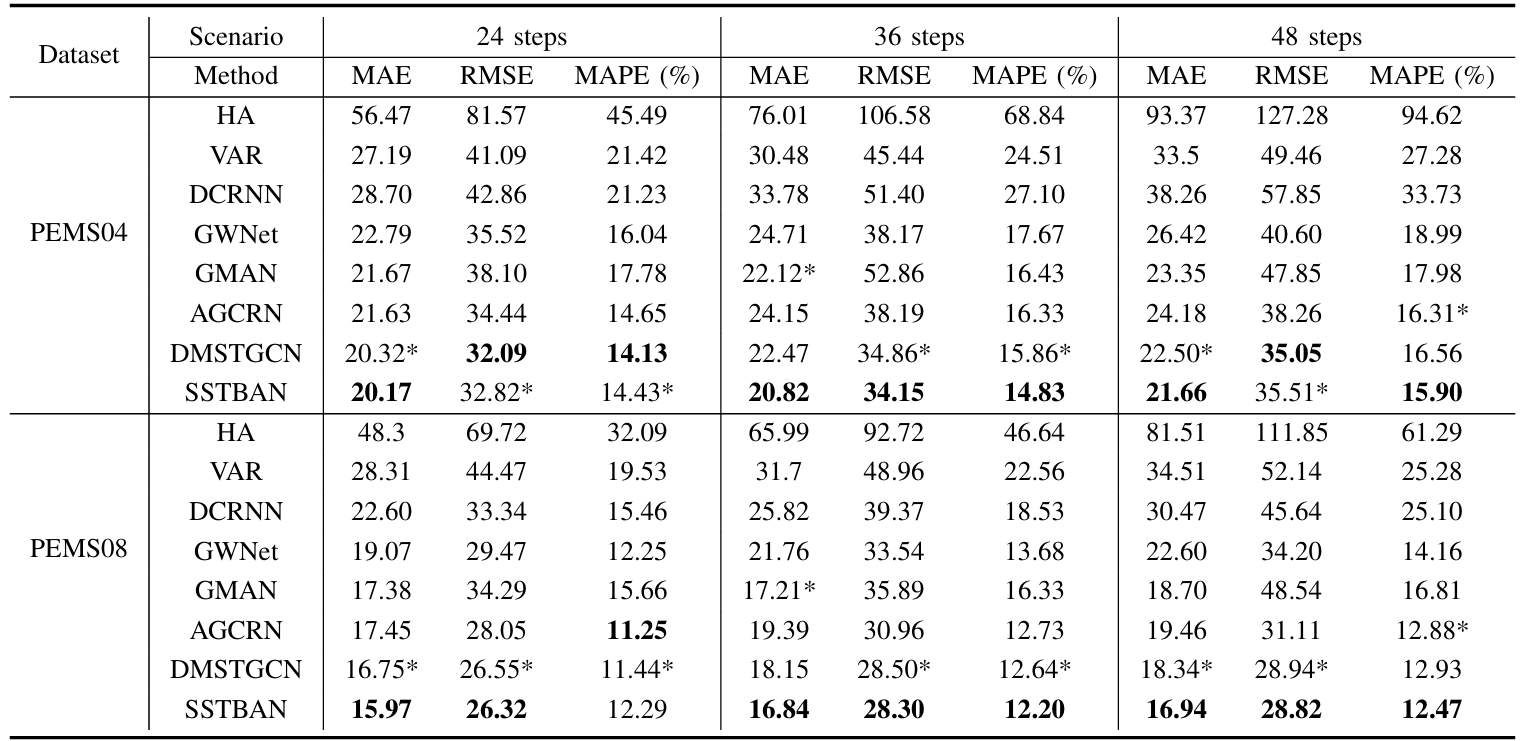 |
|---|
| 图:PEMS对比试验 |
 |
|---|
| 图:SeattleLoop对比实验 |
随着时间跨度增加,SSTBAN的优势也在增加。
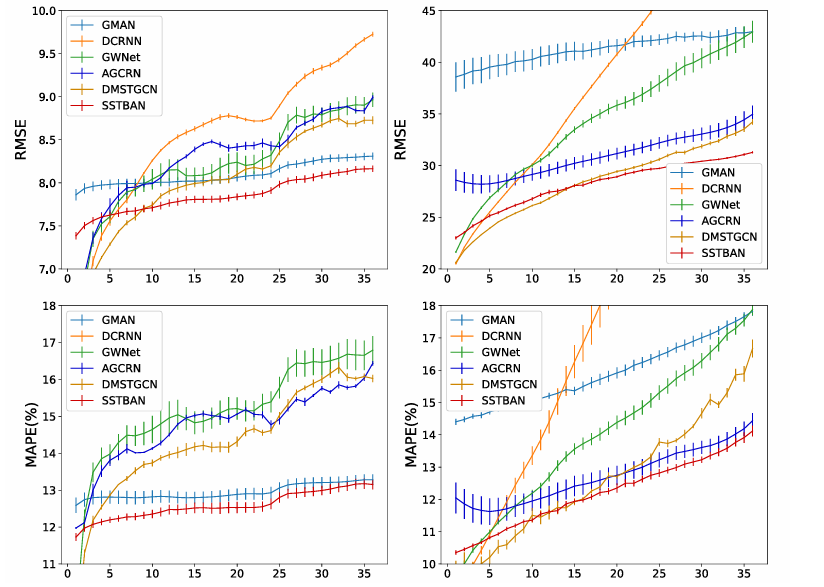 |
|---|
| 图:预测表现与预测长度的关系 |
鲁棒测试
作者还进行了以下两个实验。可以看到,模型在这两个方面还是有优点的。遗憾就是,对比的模型只有两个,且比较古老,依然是缺乏说服力。
注:GMAN AAAI2020,DMSTGCN KDD2021
 |
|---|
| 图:减少训练数据 |
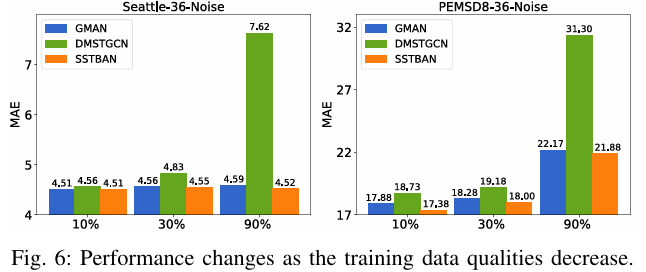 |
|---|
| 图:随机添加噪声 |
消融实验
将STBA与普通注意力网络进行对比。也觉是说,STBA在减小时间复杂度的同时,还能增加准确率。
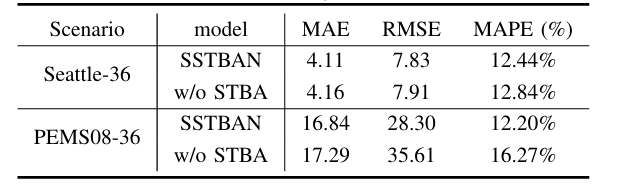 |
|---|
| 图:消融实验 |
算力消耗
可以看出,时间消耗和空间小号还是比较小的。不过在实验中,模型的时间和空间占用与batch size等参数设置有关,所以这个只能做参考吧。在我用PEMS08做复现,预测48步时,设置batch size=8,显存占用20G左右。
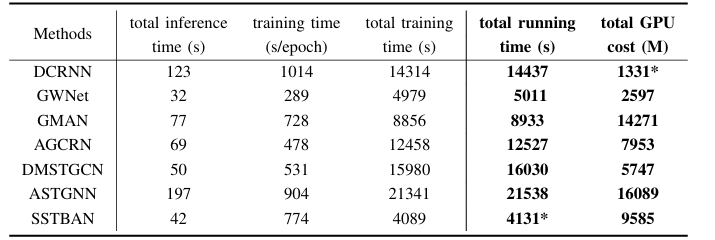 |
|---|
| 图:算力实验 |
复现
以下是我的复现结果。以下实验每个仅做了一次,并没有重复实验,所以仅作参考。
batch size对时间的影响较大。越大,时间越短,但相应的占用显存越多。在SSTBAN用PEMS08预测48步的实验中,设置batch size=16时,40G显存的A100就已经跑不动了,可以看出SSTBAN的空间占用还是比较大的。SSTBAN的特点是,训练一个epoch耗时比较长,但是epoch数量少,就触发早停了。
注:TrendGCN属于CIKM2023
| 模型 | 数据集 | 步数 | epoch | MAE | MAPE | RMSE | 时间 |
|---|---|---|---|---|---|---|---|
| TrendGCN | 08 | 12,12 | 120(batch64) | 15.11 | 9.68 | 24.25 | 0h41 |
| TrendGCN | 08 | 24,24 | 120(batch128) | 16.84 | 10.77 | 27.14 | 0h40 |
| TrendGCN | 08 | 36,36 | 120(batch64) | 17.70 | 11.95 | 28.63 | 1h30 |
| TrendGCN | 08 | 48,48 | 120(batch128) | 18.86 | 12.91 | 29.97 | 1h20 |
| 模型 | 数据集 | 步数 | epoch | MAE | MAPE | RMSE | 时间 |
|---|---|---|---|---|---|---|---|
| SSTBAN | 08 | 12,12 | 71(batch32) | 15.36 | 10.79 | 24.26 | 0h50 |
| SSTBAN | 08 | 24,24 | 16(batch32) | 15.40 | 10.68 | 26.20 | 1h30 |
| SSTBAN | 08 | 36,36 | 18(batch4) | 16.56 | 11.65 | 29.33 | 3h30 |
| SSTBAN | 08 | 48,48 | 15(batch8) | 17.29 | 15.10 | 29.04 | 2h40 |
| SSTBAN | 04 | 36,36 | 15(batch8) | 21.09 | 15.29 | 37.42 | 2h |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号