学习笔记:AutoSTG
AutoSTG: Neural Architecture Search for Predictions of Spatio-Temporal Graph
期刊会议:WWW2021
论文地址: https://dl.acm.org/doi/10.1145/3442381.3449816
代码地址: https://github.com/panzheyi/AutoSTG
总结
AutoSTG不仅自学网络权重,还自学网络结构。网络结构的学习采用Darts(2018)方法,而参数学习采用元学习方法。模型效果感觉还是不错的(虽然和去年的PDFormer之类的没法比...)。
然而我感觉这里的元学习方法依然不正宗,和ST-MetaNet一样的问题:这里的元学习只是用来学习更好的嵌入罢了,它的更新方式应该是和普通网络参数不一样的。
模型
网络结构学习
AutoSTG的主干由一系列Cell和Pooling层组成,其中每个Cell有四个中间变量H0到H3(见下图a中的Cell search space),H0是Cell的输入,其余的H由前面的各个H经过候选网络的加权平均计算得到,最后Cell的输出是四个H的和。这个模式来源于Darts(2018)这篇论文。
一个Cell中的H计算方法,以及这个模型的架构图如下。
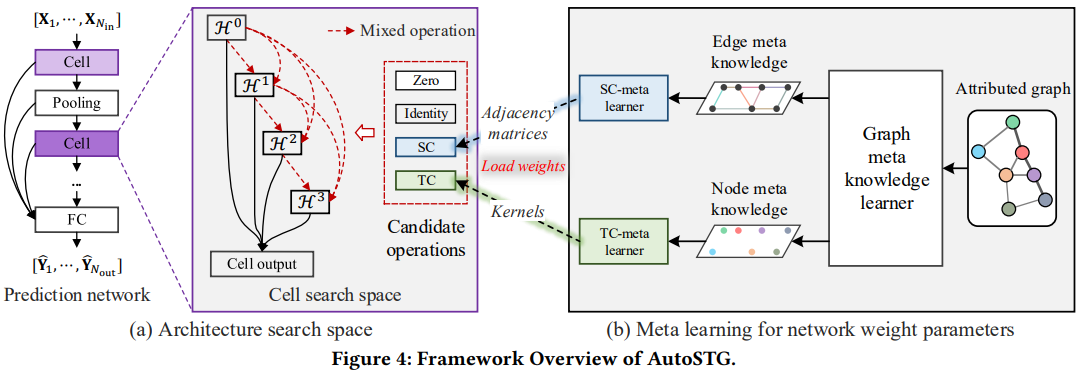 |
|---|
| 图1:AutoSTG的架构图。左边是架构学习,右边是SC和TC的参数学习。 |
网络参数学习
候选网络结构中包含空间卷积和时间卷积,这两种网络的参数用元学习得到。
论文认为,ST-MetaNet的元学习器由FC层构成,这忽略了图结构,因此提出了图元知识学习,通过聚合邻居信息来获得点和边的表征。
元学习依旧分为点和边两类。点学习使用扩散卷积,其中邻接矩阵A是由边表征计算得到的:
边学习使用两个顶点的表征和前一次迭代的表征通过FC层得到:
元学习有m次迭代,最后一次的输出作为元知识,用作时空关系的建模。接收域会随着超参数m的增长进行指数级增长。
将元知识转换为网络参数的模块叫做元学习器。空间卷积-元学习器将边元知识用FC层得到边表征,进而得到邻接矩阵;时间卷积-元学习器将点元知识用FC得到卷积核。
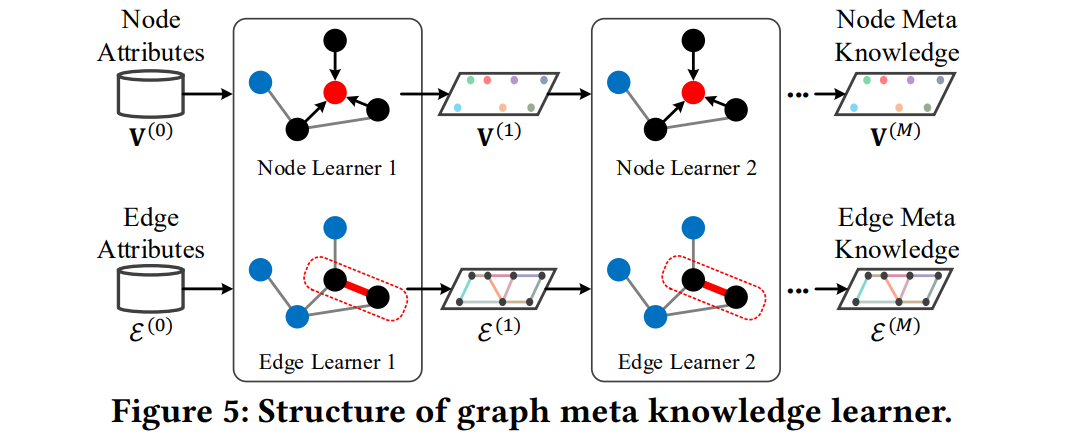 |
|---|
| 图2:元知识学习过程 |
参数更新
在参数更新上,元学习模块的参数和普通网络的参数作为一个整体一起更新。不一样的是架构参数,即调整不同候选网络的权重参数。整体的更新方式与Darts一致:
- 固定架构参数,用训练数据集训练模型参数;
- 固定模型参数,用验证数据集训练架构参数。
重复此过程。
对比试验结果如下,可以看出效果还是不错的。
 |
|---|
| 表1:PEMS-BAY和PEMS-LA上的对比实验结果 |
只是...感觉不算元学习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号