学习笔记:DSTAGNN: Dynamic Spatial-Temporal Aware Graph Neural Network for Traffic Flow Forecasting
DSTAGNN: Dynamic Spatial-Temporal Aware Graph Neural Network for Traffic Flow Forecasting ICML2022
论文地址:https://proceedings.mlr.press/v162/lan22a.html
代码地址:https://github.com/SYLan2019/DSTAGNN
作者:Shiyong Lan, Yitong Ma, Weikang Huang, Wenwu Wang, Hongyu Yang, Pyang Li
一个用于时空序列预测的交通流量预测模型。
可学习的地方:
- 提出了一种衡量不同节点时空距离的方法:时空感知距离(STAD)。简单说,就是把n个节点的数据看成n个概率分布,然后用Wasserstein distance的公式计算出概率分布相互转换的代价,作为节点之间的距离。
- 提出了一种多头GTU的结构
- 使用了一种多个注意力结果串联,然后再将各个输出合并的结构
对比试验结果似乎还不错。
1 复现情况
模型使用torch环境。
想换数据集结果报错。代码里给了PEMS04的部分数据。由于PEMS08更小,我想训练PEMS08,但是运行时报错,说在数据预处理时出现了none或无穷大值,只好作罢。我无法直接训练PEMS04,因为显存不够。于是我调小batch_size到8,终于可以训练了。
我用的GTX1650,训练一个epoch要花很长时间。一epoch要花800s, 1600s, 2400s, 3200s, 4000s...时间越来越长,我训练了7个就终止了,熬不住了,打个游戏都卡。
更新自2023.9.20:
数据预处理出现了除0错误:当一个点在某一天的流量全为0时,在STAG_gen.py中的spatial_temporal_aware_distance函数里,x或y的第二个维度数值全为0,导致x_norm或y_norm有一个值为0,那么在D = 1 - np.dot(x / x_norm, (y / y_norm).T)这句中,x/x_norm或y/y_norm就会出现除0错误。本质上是在将向量单位化时忽视了0向量的模长为0的情况。我就直接在加了这两句话:x_norm[np.where(x_norm==0)] = 1. y_norm[np.where(y_norm==0)] = 1. 。然后,还要留意configurations/PEMS0x_dstagnn.conf文件下缺少graph这一属性的问题,如果没有这个,就加上graph = AG
四个数据集在TITAN V上的复现结果:
| 数据集 | 节点数量 | MAE | RMSE | MAPE | 时间消耗(h) |
|---|---|---|---|---|---|
| PEMS03 | 358 | 15.74 | 27.65 | 15.06 | 4.11 |
| PEMS04 | 307 | 19.35 | 31.57 | 12.87* | 9.12 |
| PEMS07 | 883 | 21.59 | 34.95 | 9.28 | 2.05 |
| PEMS08 | 170 | 15.85* | 25.11 | 10.04* | 28.58 |
与论文给出的结果相差无几,但是基本上都比论文中的要差一些(可能是对除0错误处理的方式不同导致的)。复现的结果有三个(表格中打星)不如对比的模型,不过大部分还是优于其它的。
2 问题和符号定义
节点数量为N,历史时间戳数量为M,预测的时间戳数量为T,特征只有一个。
任务:
其中 \(X^{(t+1):(t+T)} \in \mathbb R^{N\times T}, X^{(t-M+1):t)} \in \mathbb R^{N\times M}\)
3 模型结构
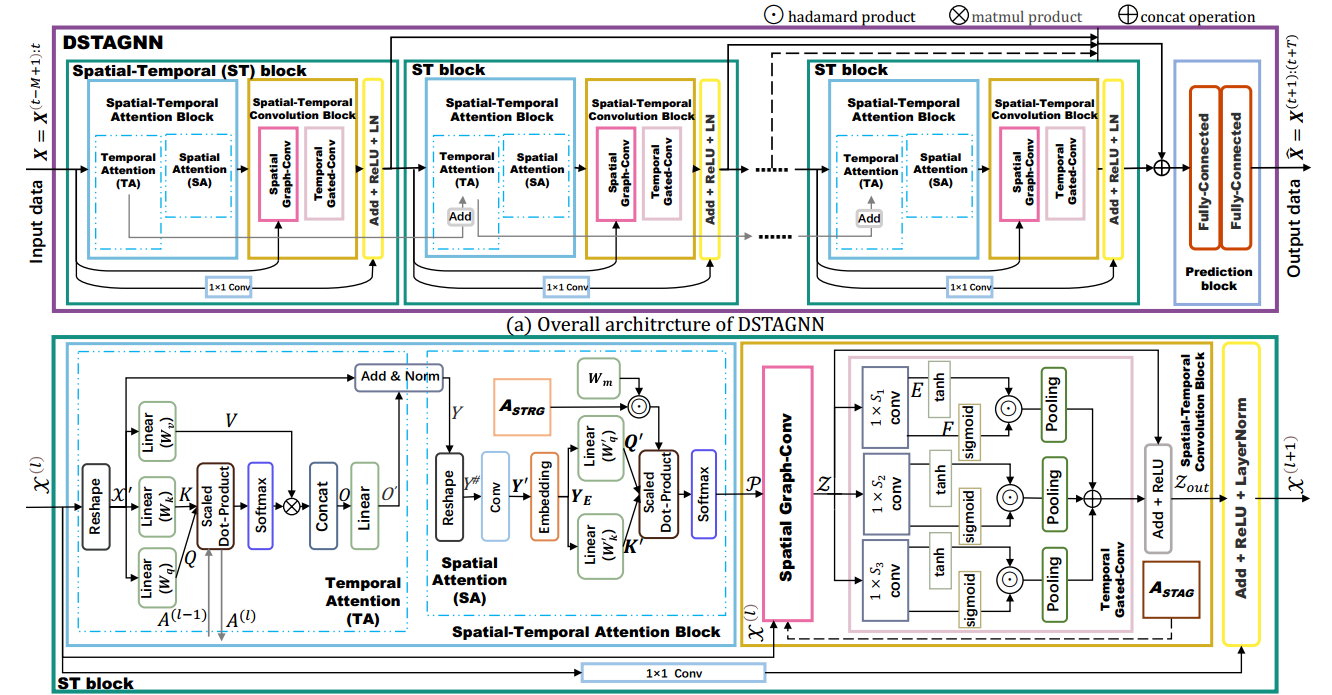 |
|---|
| 图1:结构图 |
3.1 构建时空感知图
交通流数据表示为:\(X^{f}\in\mathbb{R}^{D\times d_{t}\times N}\),N为节点数量,D为天数,\(d_t\)为每天的时间戳数量,那么第n个节点的数据表示为\(\boldsymbol{X}_{n}^{f}=(\boldsymbol{w}_{n1},\boldsymbol{w}_{n2},...,\boldsymbol{w}_{nD}),\boldsymbol{w}_{nd}\in\mathbb{R}^{d_{t}}\)。然后:
这样的话,就获得了n个概率分布\(P_n\{X_d=m_{nd}\}\) 。那么两个节点的时间序列的差异就可以表示为两个概率分布的转移代价:
其中,
不解 这种微积分表示,是求期望的意思吗?答:不,这是Wasserstein distance的式子,表示两个概率分布之间的“距离”。具体的可以看我这篇博客学习笔记:什么是Wasserstein distance
上面的通俗点说,就是N个时间序列,每个时间序列是D个向量,向量大小为\(d_t\) 。然后模型只关心向量的长度的比例,于是用向量模长代替向量后,将时间序列整体缩放,使得这个时间序列之和为1。这样就可以把每个节点的时间序列视为一个概率分布。然后定义了两个概率分布相互转化的代价,也就是两个时间序列的距离计算方法。
然后用这种方法计算出N×N的矩阵\(A_{STAD}\) ,其中\(A_{STAD}[i,j]=1-d_{STAD}(i,j)\in[0,1]\) (时空感知距离矩阵)。求出每个点最接近的\(N_r\)个点,其中\(N_r=N\times P_{sp}\) ,\(P_{sp}\)是超参数,表示稀疏程度,也就是在\(A_{STAD}\)的每一行找到最大的\(N_r\)个值。将\(A_{STAD}\)上的其余值设为0,得到了\(A_{STRG}\) (时空相关图)。可以用\(A_{STRG}\)作为注意力机制的先验知识,这个之后会用到。将\(A_{STRG}\)上的非0值设为1(二值化),得到\(A_{STAG}\)(时空感知图),可以用作图卷积中的聚合操作。
思考 这种定义两个点距离的方式,实际上是关心了整体时间上,两个点每天流量比例的相似性。也就是,以天为单位观察流量,如果两个节点的流量几乎都是同时增加和减少,不管他们本身的数值有多大,这两个点都是相似的。 由于只有1个特征,这个式子看起来很好计算。
3.2 时空注意力块(Spatial-Temporal Attention Block, ST Block)
一个ST块(ST Block)由三部分组成:时间注意力(Temporal Attention, TA),空间注意力(Spatial Attention, SA)和图卷积。
整个模型就是由若干个ST块组成的。
时间注意力
不解 “多头注意力提供了平行机制,能够有效关注序列数据的长范围的相关性”为什么说这样就利于长范围相关性的提取?
这里的多头注意力机制,实际上是若干个注意力机制的串联,最后将多个注意力机制的结果合并。
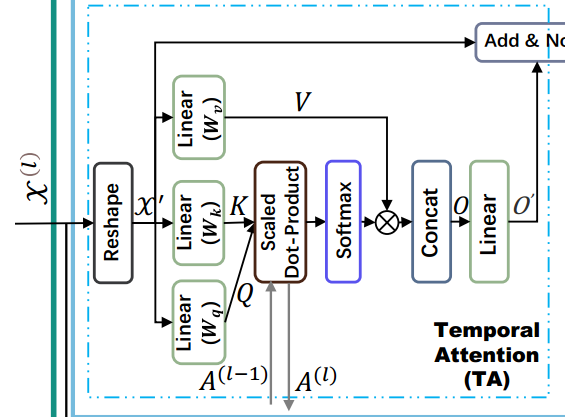 |
|---|
| 图2:时间注意力TA |
第\(l\)个TA的QKV:
其中\(d_h=d/H\) 。
之后,再对\(Q^{(l)},K^{(l)},V^{(l)}\)进行H次不同的线性变换,经过注意力操作后,缝在一起:
最终输出Y到空间注意力模块中,它的形状是\(c^{(l-1)}\times M\times N\)
不解 我觉得模型图这里画的有问题,缺少了这H次注意力和合并操作
空间注意力
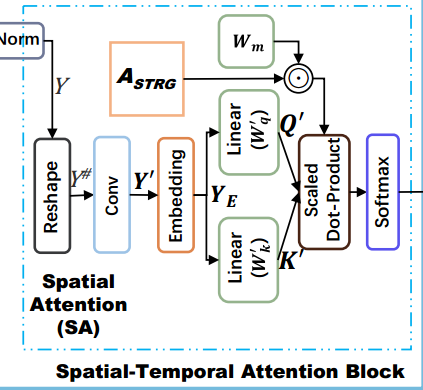 |
|---|
| 图3:空间注意力SA |
\(Y\) 变形为 \(Y^\#\),即形状为 \(c^{(l-1)}\times N\times M\)
将维度\(M\)映射成更高维度\(d_E\)
通过一维卷积1x1conv聚合\(c^{(l-1)}\)那一维,得到\(Y'\),形状 \(N\times d_E\)
嵌入位置信息,得到\(Y_E\)
利用\(A_{STRG}\):
最终\(\mathcal P\)的形状为\(H\times N\times N\)
时空卷积
空间图卷积 Spatial Graph-Conv
将所有计算中用到的\(A\)换成\(A_{STAG}\):
使用K阶切比雪夫多项式,也就是说每个节点聚合了k阶邻点。
其中\(\boldsymbol \theta_k\in\mathbb{R}^K\)是可学习参数,\(\boldsymbol P^{(k)}\in\mathbb R^{N\times N}\)是空间注意力中的第k个头。
输入为\(\mathcal X^{(l)}\in\mathbb R^{N\times c^{(l-1)}\times M}\),卷积核为\(g_\theta\in\mathbb R^{K\times c^{(l-1)}\times c^{(l)}}\),输出为\(\mathcal Z^{(l)}\in\mathbb R^{N\times M\times C^{(l)}}\)
 |
|---|
| 图4:图卷积 |
时间门控卷积 Temporal Gated-Conv
由三个不同野的门控Tanh单元(GTU)组成。输入为\(\mathcal Z^{(l)}\) 。
不解 这个GTU有什么用
传统GTU通过卷积核\(\Gamma\in\mathbb{R}^{1\times S\times c^{(l)}\times2c^{(l)}}\)来使通道数加倍。\(\mathcal Z'^{(l)}=\Gamma*\mathcal Z^{(l)}\),那么\(\mathcal Z'^{(l)}\in\mathbb R^{N\times(M-(S-1))\times2C}\) 。GTU的过程为:
其中\(E\)和\(F\)分别是\(\mathcal Z^{(l)}\)的前一半和后一半,\(\phi(\cdot)\)是tanh函数,\(\sigma(\cdot)\)是sigmoid函数。
通过叠加门控卷积,提高提取长范围时间依赖性的能力。
模型提出了改进后的M-GTU:使用三个具有不同S大小的GTU,
Concat操作后,数据维度为\(3M-(S_1+S_2+S_3-3)\),然后通过窗口宽度为W的pooling层,变成\((3M-(S_1+S_2+S_3-3))/W\)。通过调节\(W,S_1,S_2,S_3\),可以让\((3M-(S_1+S_2+S_3-3))/W=M\),最后通过ReLU函数得到\(Z_{out}^{(l)}\in\mathbb R^{N\times M\times C^{(l)}}\)。
不解 总感觉这个论文模型介绍的文字和图片没有对应上。不过我还没有看代码,也不好说那个才是对的。
4 实验结果
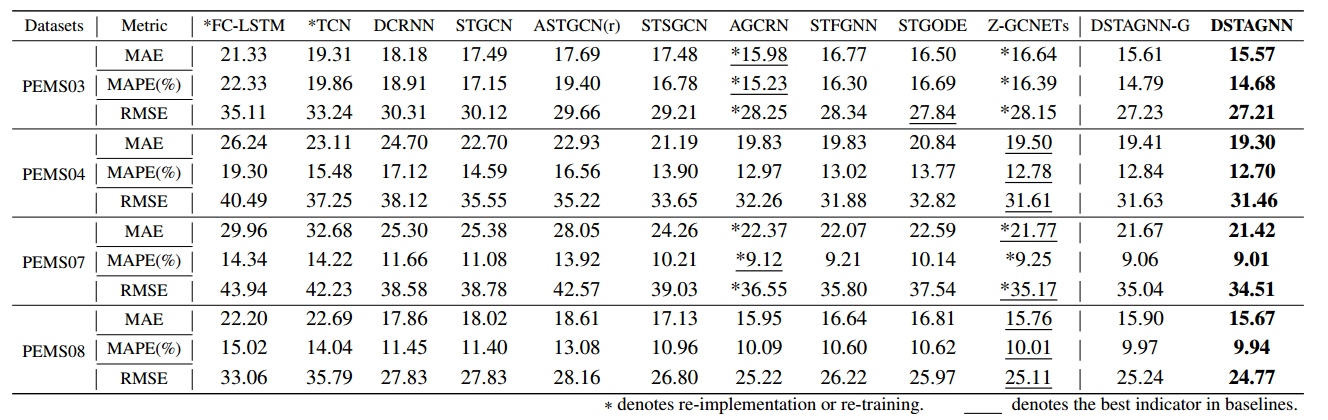 |
|---|
| 图5:对比试验 |
 |
|---|
| 图6:消融实验 |
需要说明的点:
- 基线模型:FC-LSTM(2014), TCN(2018), DCRNN(2017), STGCN(2017), ASTGCN(2019), STSGCN(2020), STFGNN(2021), STGODE(2021), Z-GCNETs(2021), AGCRN(2020)
- DSTAGNN-G使用的是预定义的时空关系图,DSTAGNN使用的是\(A_{STAG}\) 。可以看出使用\(A_{STAG}\)确实会提升一点效果。这里预定义的时空关系图应该就是数据集中路网结构,而\(A_{STAG}\)实际上是根据节点流量自动生成的空间结构,因此说这个模型可以用于没有空间先验信息的情况,且从实验结果上看效果可能会比有空间先验信息的更好。
- 打*号的是作者重新跑了代码复现的,其余是抄的对应论文的结果。可以看出复现的主要是STFGNN和Z-GCNETs这两个模型,或许是因为这两个模型的结果相对较好,有复现一遍的价值?
- 消融实验中,RemSTA去除时空注意力机制,RemM-A去除多头机制,RemM-GTU用传统GTU代替M-GTU,RemRC-OUT去除每个ST块后的残差连接。可以看出时空注意力机制是必不可少的,多头机制是提升最大的,M-GTU和残差连接提升不多。另外,这个消融曲线图画得真好,用颜色深浅表示不同实验,曲线的上下关系和图注的上下对应,看起来很舒服。
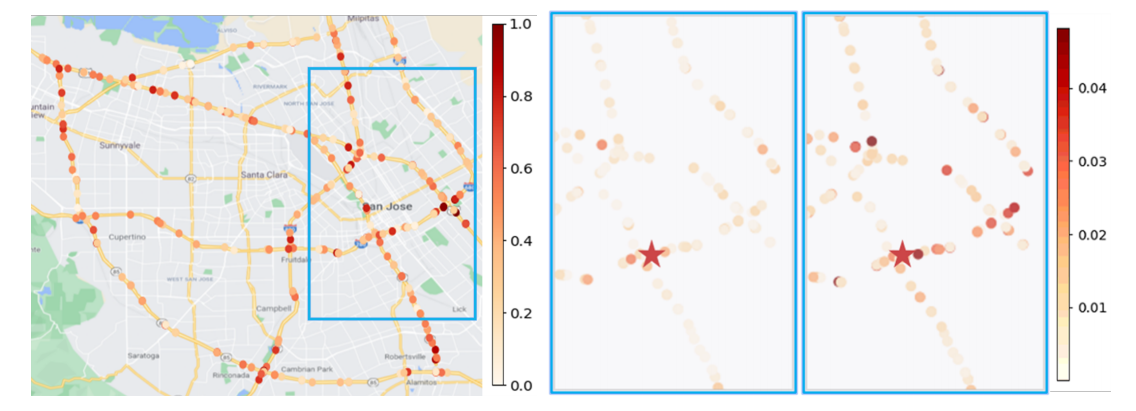 |
|---|
| 图7:注意力可视化 |
论文把时空关系可视化了。左图是第一个注意力头的全局注意力,右图是通过第2、3个头获得的红星点与其它点的时空依赖。论文说这样就提取了路网中的复杂信息,不过我不理解这两个图代表什么含义。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号