
mysql事务
涉及的内容很多,慢慢写。
1.ACID
原子性 atomicity redo有关
一致性 consistency undo有关
隔离性 isolation lock有关(mysql中只有可串行化能保障,哪怕是rr也不能完全保障隔离性)
持久性 durable redo + undo有关
2.脏读,不可重复度,幻读
脏读:事务1读到事务2未提交的事务。在ru下存在次问题。rc能解决。
不可重复读:但是事务1前后两次查询的结果不一致。rc下存在此问题。rr能解决。
幻读:连续执行两次同样的SQL可能导致不同的结果,第二次执行的SQL语句可能会返回之前不存在的列。
为什么说rr也不能完全保证隔离性。因为可以当前读。你给读操作加一个for update,你会发现在rr下,会出现脏读,不可重复读和幻读。在s下完全解决。
而可串行化,不管什么操作,都是有锁的。哪怕是读,他会默认在后面加上lock in share mode。
3.redo
你的ib_logfile就是redo log(之前说过,这个文件的前面2k是写checkpoint的,而且还是两个checkpoint,mysql怕其中一个坏掉。)
redo log buffer是有很多个512字节大小的的block组成的。放在内存中。主动刷盘:每一秒master thread会把redo log buffer写入磁盘。redo log buffer占用超过1/2时会刷新磁盘。被动刷盘:事务提交时刷新磁盘(由innodb_flush_log_at_trx_commit控制)
设置成1.意思是我的事务只要提交了,我的redo log buffer就需要落盘。请注意,这里只用保证redo log buffer落盘,你在内存中的page可能还是脏页。这个值等于1,在底层就是调用的fsync。
这就带来了组提交。我们设想一个场景。一个事务一个sql,假设我磁盘最大的iops是100,那么是不是说明,我每秒钟,只能调用100次fsync。也就只能写100个事务。但如果,我能在一次fsync中写入多个事务,是不是性能一下子就上去了。这就是组提交。这就带来了两个参数:binlog_group_commit_sync_delay和binlog_group_commit_sync_no_delay_count。前者是组提交等待的微妙数,调大这个参数,每次写入的事务增大,后者是累计多少事务再提交。
不过没人开这两个参数,默认0就行了。
画几幅图,来记录下redo log的结构:
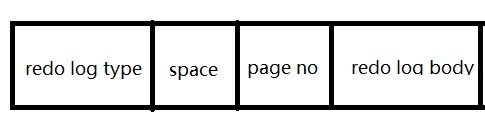
这只是个简略表达,因为根据redo log type的不同,它后面的body是不同的。insert和delete的redo log就完全不一样。
redo和binlog的区别:
binlog日志的顺序就是事务提交的顺序,并且是基于SQL进行记录的。如图:
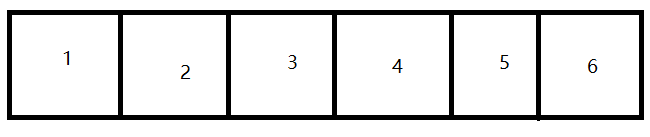
binlog中,这6个事务一定是顺序的。1的提交时间一点最早,6的提交时间一定最晚。
而redo log

redo log记录的是页的变化。事务1的一条sql语句,可能让很多页都改变了。所以一条binlog的语句可能记录了很多条redo log。
而redo log在事务进行的时候就开始写了,比如说上面的redo log图示,可能里面的1,2,3号页所对应的事务根本没有commit。
但是binlog一定是在事务提交之后再写入的。
然后这就带来了一个问题,怎么保障原子性的写入。上文中有提到,redo log buffer的落盘,其实是有主动刷新和被动刷新两种。
这时候假设你有一个事务,并且这个事务的redo log没有主动落盘。这时候你commit了。怎么保障redo log和binlog能原子性落盘。
即,redo log和binlog要么都落盘成功,要么都落盘失败。
如果你先写redo log,在你写binlog的时候系统挂了怎么办。反过来也一样,你先写binlog再写redo log一样有风险。
mysql对此进行了一个分布式事务,也就是说commit本身就是一个事务,分三步:
1.innodb prepare redo log(fsync)
2.write binlog(fsync)
3.innodb commit redo log(这一步其实很复杂,不是单纯地打一个commit标志,而是要把undo中的日志从active列表移到history中)
当1成功,2失败时。rollback
当1,2成功,3失败时。commit(这一步,commit和rollback都能保证数据的ACID。但是mysql的主从复制依赖于binlog,所以mysql选择commit去保障从库的数据。)
3者成功。commit。
你在recove的时候。mysql先scanbinlog,把trx_id都取出来,根据这些trx_id建一张hash table。接着去scan redo log,从checkpoint位置往后扫,这时候也会有个trx_id的list。然后用redo log产生的trx list去search binlog产生的trx hashtable。如果找到了commit,没找到,rollback。
这个分布式事务有一个参数控制:Innodb_support_xa。这个参数5.7之后应该你关不了。
4.undo
undo记录的是逻辑的。而redo其实是物理逻辑日志。
所以回滚是逻辑的,他不是基于页的,是基于记录的(row)。这也就是为什么rollback比commit慢很多的原因。如果你sql执行了半小时,commit可能要2分钟,但是rollback可能需要同样的时间。

undo log record其实是分insert和update的。
一个事务内的insert和update都是分开存放的。
原因是insert操作commit后,undo段是可以马上回收的,但是update不行。原因是MVCC,其他线程可能在引用之前的版本。
而update的undo又分成了TRX_UNDO_UPD_EXSIT_REC(用于简单update)
TRX_UNDO_DEL_MARK_REC(用于delete)
TRX_UNDO_UPD_DEL_REC(如果一个事务中,既有delete,又有insert,那么那一条insert就是这个类型。)
而什么时候undo才能回收哪?在purge thread中。这个线程一来删除undo,一来删除真正的记录(因为delete其实只是标记删除,页中的记录并没有删除,要purge来)。
控制参数:innodb_purge_threads。设成4,8都可以的。
undo本身是无序的。所以开销很大。
线上如果你undo的purge效率不高。很可能是大事务。因为你一直commit不了,他的undo就释放不了。很多情况可能都是没加索引,或者事务本身拆得不够细。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义