
python基础-函数
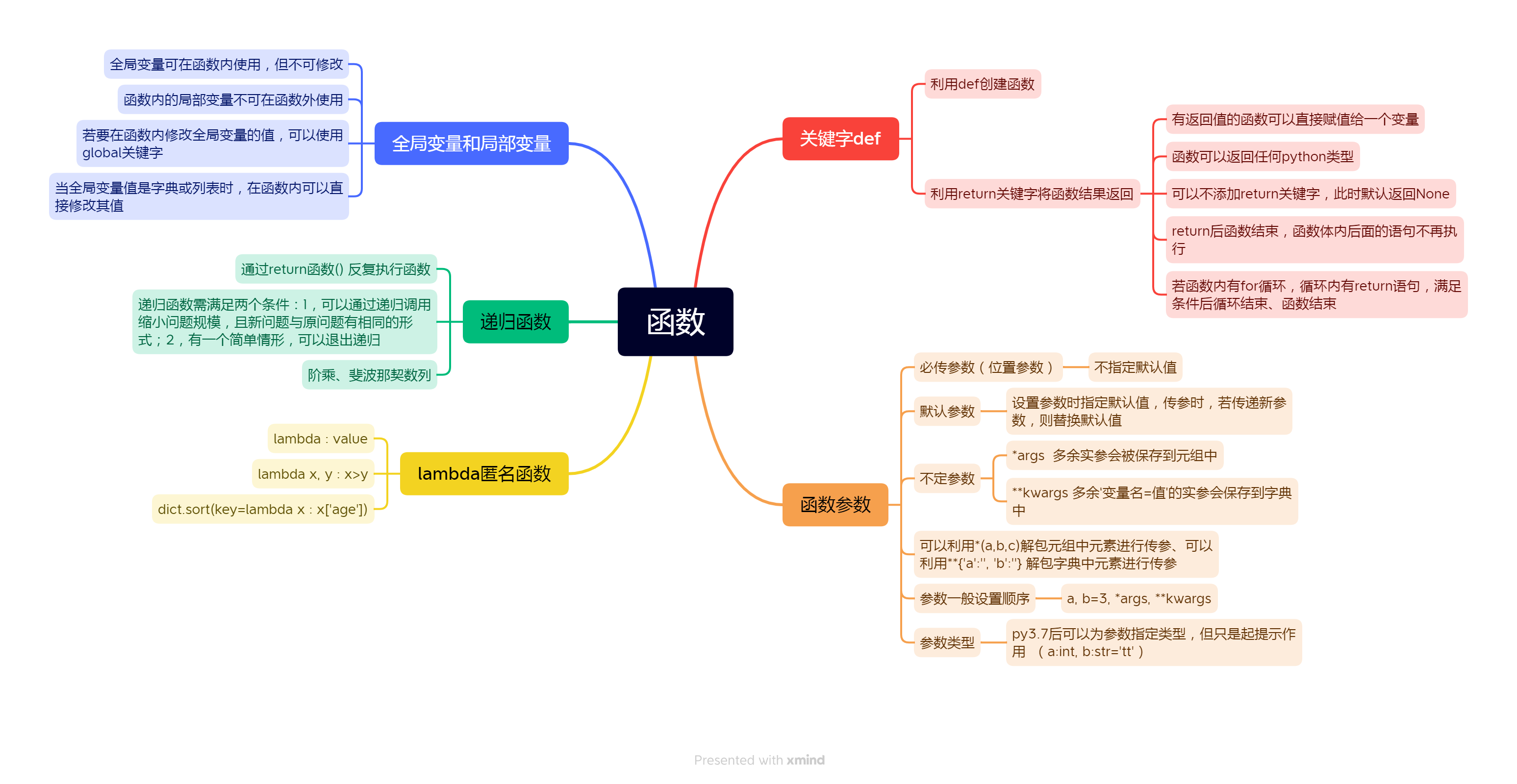
1.函数定义
函数就是将完成一件事情的步骤封装在一起并得到最终的结果;
函数名代表了这个函数要做的事情;
函数体是实现函数功能的流程;
添加一个函数也被叫做实现了一个方法或功能;
函数可以帮助我们重复使用一些操作步骤;
2.def
通过关键字def定义函数;
def name(args...):
print('')
return 是将函数结果返回的关键字;
return只能在函数体中使用;
return支持返回所有python类型;
有返回值的函数可以直接赋值给一个变量;
def add(a, b):
c=a+b
return c # 出现retuen代表函数执行结束,后面有语句也不会执行了
def multiplication(a, b):
re = a * b
return re
print('test')
result = multiplication(3, 4) # 函数返回值可以直接赋值给变量
print(result)
'''
12 return后的语句不会被执行
'''
def no_re():
print('无返回的函数')
no_r = no_re()
print(no_r) # 函数无返回时,默认是None
'''
无返回的函数
None
'''
def test():
for i in range(4):
print(i)
if i == 2:
return i
t = test()
print(t)
'''
0
1
2
2
# return后循环结束,函数结束;只打印到2,且函数返回值2
'''
3.函数的参数
必传参数(位置参数),函数中定义的没有默认值的参数,在调用函数时若不传则会报错;
在定义函数时,参数后无等号和默认值;
且传参时,实际值的顺序与定义的参数顺序要一致;
def add(a, b)
默认参数,定义函数时,定义的参数有默认值,通过赋值语句给他一个值;
如果调用函数时,为默认参数传递了新值,函数会使用新传入的值;
def add(a, b=1)
def add(a, b, c=4):
return a+b+c
re = add(1, 2) # 使用c的默认值
print(re) # 7
re2 = add(1, 2, 5) # 使用c的新值
print(re2) # 8
# 注意,默认参数一定在位置参数之后,否则会报错
def add2(a, b=3, c):
return a+b+c
add2(1, 3, 2)
'''
File "D:\python_exercise\test.py", line 566
def add2(a, b=3, c):
^
SyntaxError: non-default argument follows default argument
'''不确定参数--可变参数,没有固定的参数名和数量(提前不知道要传的参数名和数量);
def add(*args, **kwargs)
*args保存多余实参,保存为元组、**kwargs保存多余的带有变量名的实参,保存为字典;
def add(a, b, c=4, *args, **kwargs):
print(a)
print(b)
print(c)
print(args, type(args))
print(kwargs, type(kwargs))
add(1, 2, 3, 4, 5, d=3, e=4)
'''
1
2
3 # 3给了默认参数c,后面再有的剩余实际参数保存为元组了
(4, 5) <class 'tuple'>
{'d': 3, 'e': 4} <class 'dict'>
# 后面就可以使用元组、字典的方法处理args和kwargs了
'''
def test(*args, **kwargs):
print(args)
print(kwargs)
test((2, 3), {'name': 'll', 'age': 23})
'''
((2, 3), {'name': 'll', 'age': 23})
{}
'''
# 可以发现*args是将多余实参都放到了元组中
# 如果就想对应传递元组和字典,可以在实参前加*和**
test(*(2, 3), **{'name': 'll', 'age': 23})
'''
(2, 3)
{'name': 'll', 'age': 23}
'''
def add3(a, b, c):
return a+b+c
tuple_test = (23, 45, 0)
re = add3(*tuple_test) # 此时也可以借助*tuple对实参进行解包
print(re) # 68参数的规则,
多参数一般添加顺序 :def add(a, b=1, *args, **kwargs) 。
上面的例子可以看到python中函数参数没有定义类型,
其实在py3.7后可以为参数定义类型,但只是用于肉眼上的查看;
def person(name:str, age:int=33):
print(name, age)
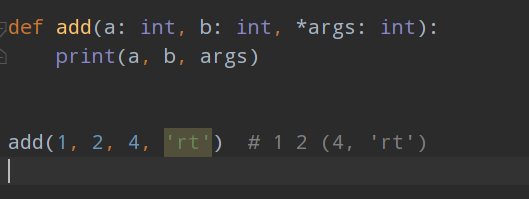
def add(a: int, b: int, *args: int):
print(a, b, args)
add(1, 2, 4, 'rt') # 1 2 (4, 'rt')
# 虽然传递的参数不符合数据类型的要求,但可以正常执行,指定类型只是起提示功能且pycharm中也会有提示标注
4.全局变量和局部变量
python脚本最上层代码块的变量,就是全局变量;全局变量可以在函数中读取使用;
局部变量:只能在局部使用的变量,比如函数体内的变量只能在函数内使用;
name = 'll' # 定义一个全局变量
def test():
print('函数体内'+name)
test() # 函数体内ll (函数体内可以直接使用全局变量)
def test2():
age = 13
print(age)
test2() # 13
print(age) # NameError: name 'age' is not defined (局部变量只能在局部使用)
def test3():
name = 'tt'
print(name)
test3() # tt
print(name) # ll (全局变量未被函数修改,函数只能使用全局变量,不能修改)可以使用global关键字,在函数内修改全局变量;(但在工作中不建议使用global对全局变量进行修改)
name = 'll' # 定义一个全局变量
def test():
global name
name = 'tt'
test()
print(name) # tt当全局变量值是字典或列表时,函数内可以直接修改其值;
name_list = ['ll', 'tt'] # 定义一个全局变量
def test():
name_list.append('rr')
test()
print(name_list) # ['ll', 'tt', 'rr']
5.函数的递归
一个函数不停的将自己反复执行;
def test(a):
print(a)
return test(a) 通过返回值,直接执行函数自身,就可以达到递归的效果;
避免滥用递归,一定要设置满足后退出递归的条件,小心内存溢出;
能用递归解决的问题必须满足两个条件:
1.可以通过递归调用来缩小问题规模,且新问题与原问题有着相同的形式;
2.存在一种简单情形,使用该简单情形可退出递归;
count = 0
def test():
global count
count += 1
if count != 5:
print('继续执行函数')
return test()
else:
print('执行结束')
test()
'''
继续执行函数
继续执行函数
继续执行函数
继续执行函数
执行结束
'''两个经典的递归案例,阶乘和斐波那契数列;
'''
阶乘
n! = 1*2*3*...*n
f(n) = n * f(n-1)
且f(1)=1
'''
def test(n):
if n == 1:
return 1
return n * test(n-1)
re = test(6)
print(re) # 720
'''
斐波那契数列(黄金分割数列)
数列从0开始,数列前两项是0,1,第三项开始每一项是前两项的和
f(0) = 0
f(1) = 1
f(n) = f(n-1) + f(n-2)
'''
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
return fib(n-1) + fib(n-2)
# 求数列的第9项
re2 = fib(9)
print(re2) # 34
# 打印20项
for i in range(20):
if i == 19:
print(fib(i), end=',')
else:
print(fib(i), end=',')
# 0,1,1,2,3,5,8,13,21,34,55,89,144,233,377,610,987,1597,2584,4181
6.匿名函数lambda
可以定义一个轻量化的函数,处理一些简单操作;
即用即删除,适合需要完成一项功能,但此功能只在此一处使用;
无参数lambda, f = lambda : value ; f()调用;lambda函数自带return关键字,此时返回值是value;
有参数lambda, f = lambda x,y: x*y ; f(3, 4)调用; 此时返回值是x*y的值12;
test = lambda: 34
print(test()) # 34
test2 = lambda x, y: x > y
re = test2(4, 6)
print(re) # False
test3 = lambda x, y=4: x + y
re = test3(4, 6)
print(re) # 10
# 此时可以再来看列表的sort(key)方法,key参数值就是函数、可以指定排序的参考值,此处就可以使用lambda函数的写法
name_list = [
{'name': 'll', 'age': 34},
{'name': 'tt', 'age': 4},
{'name': 'rr', 'age': 24}
]
# 按照字典中age对应的值排序
name_list.sort(key=lambda x: x['age'])
print(name_list) # [{'name': 'tt', 'age': 4}, {'name': 'rr', 'age': 24}, {'name': 'll', 'age': 34}]
总结

 浙公网安备 33010602011771号
浙公网安备 33010602011771号