Flink理论基础
1.Flink的几种运行模式
1.yarn模式(重点)
①Sesson模式
它是启动一个Flink集群,向集群提交任务时,资源是共享的,如果资源不够,其它任务就必须要等待了。
它一般是运行小而快的任务,一般适用于离线任务
②per-job模式
它每一个提交的任务都有一个独立的Flink集群。独立的资源,每个任务都是独占的,它不会释放。
它一般是运行大而慢的任务,其中流式任务就是大而慢的任务,它需要7*24小时不停的执行
2.standalone模式(重点)
3.k8s
4.Mesos模式
2.Flink运行任务提交流程
这里主要说yarn模式(开发常用)
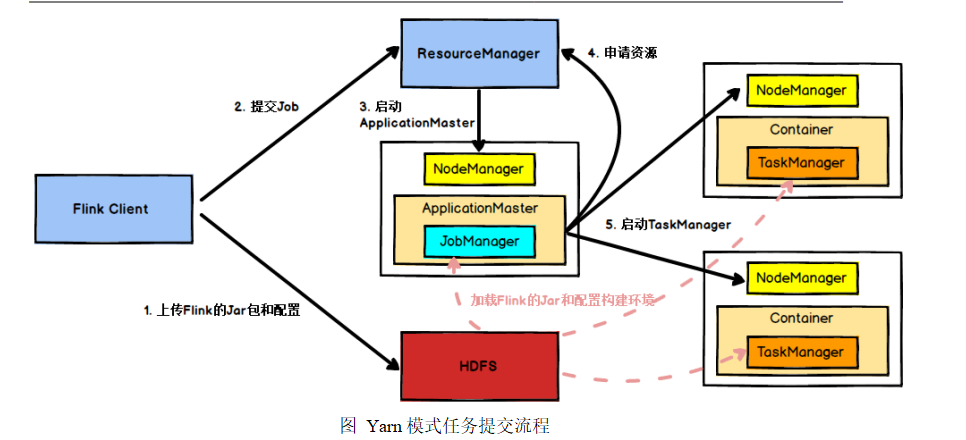
首先,我们有一个类似于提交代码的客户端,然后它上传Flink的jar包和配置到HDFS上,接着它把任务提交给Yarn的ResourceManager,RM接收到应用后,会找到NodeManager
并启动ApplicationMaster,AM里运行着自己的ResourceManager和JobManager。JobManager根据你的slot并行度和共享组把任务进行切分,形成一个任务链。AM里的RM主要用来
申请资源,启动NodeManager里的TaskManager,TaskManager根据配置不同,一个TaskManager可以有多个Slot,任务运行需要用到Slot资源,JobManager把任务发送给TaskManager
的Slot去运行。
这里涉及到几个概念
1.共享组
默认不设置的时候,大家处于同一个共享组,其中一定有某一个slot里保存着从source到Sink完整的数据流。因为从source 到Map ,FlatMap,再到Sink过程中,任务是可以串行的,也就说Source用完资源,就把资源给Map,它并不占用资源,也就不涉及资源的争抢问题。我们可以给每个算子设置共享组,但是keyby不能设置共享组,因为keyby定义的是传输的数据流程,它并不涉及计算。而map,flatMap,reduce,aggregate,sum这些是对数据做计算的,这些算子后面可以跟共享组。
代表数据传输的算子有以下:
hash :由keyby导致,它是将数据集中的发送给某个key,它不能设置共享组它表示传输的数据流程
shuffle: 是将数据打散,随机发送
rebalance: 轮询策略,它发送在oneTOone并行调整的时候
forward:
数据经过keyby之后,数据会根据key传输到不同的slot里,但是打印的时候是拿不到key的。但是如果我们是做keyby操作之后后面我们可以通过keyedProcessFunction来获取key
2.任务链
可以把任务放到同一任务链的四个条件
1.同一个共享组 (可以共用同一个slot) 2.one to one 3.相同并行度 4.同一个任务链
3.DataStreamAPI(属于中间层)
1.source
2.transform
transform有两种
①普通 类似于MapFunction,FlatMapFunction
②富函数 RichFunction 它包含生命周期和运行时上下文
生命周期:当我们涉及和第三方框架进行交互的时候,我们只能用RichFunction,因为它有生命周期,可以在open方法里只获取一次连接
运行时上下文:它可以做状态编程,因为我们所有的状态都是从运行时上下文当中获取的。
状态编程 可以分为两种
1.ManagerState
①算子状态(不常用) 1.list state 2.union list state 3.broadcast state(保证全局状态一致)
②键控状态(常用) 1.valueState 2 listState 3.MapState 4.reduceState 5.aggregateState 后面两个需要根据数据重新计算
2.rawState 它管理存储,以及重启之后重新加载,这些都需要自己去写(生产环境不用)
状态编程:如果任务挂掉,想通过状态编程恢复,首先启动checkpoint 然后设定状态后端。它默认是内存级别(MemoryStateBackend),一般我们用的是 FsStateBackend或RocksDBStateBackend。
3.sink
3.watermark
它是在流里插入的特殊数据
目的:是处理乱序数据
处理乱序,只要我们指定事件时间,指定watermark
接下来就是窗口里的执行,它包括Fire(计算) puge(发送数据)
当watermark超过window最大值时,它就可以让窗口去计算和发送数据
watermark指的是watermark之前的数据全部到齐
watermark传递问题
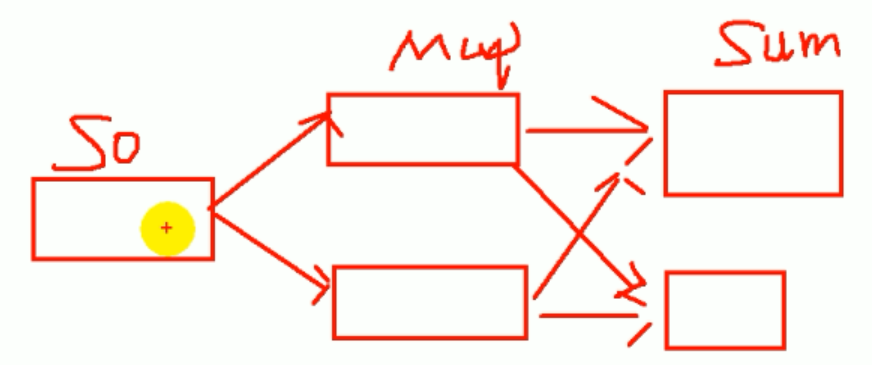
这个是由source到map 再经过keyby到sum过程
如果 watermark在source之后提取,正常数据是轮询发送的,也就是只发送给某一个人,但是当你生成watermark的时候,它是发送给每个人。watermark是向下游的并行度都要传递的。如果在map之后提取watermark对sum来说,它会接受1号并行度和2号并行度两个watermark,并且未来1号并行度只能更新1号,对于sum来说,它最终会取1号和2号中最小的watermark
如果在source之后提取watermark,因为source并行度为1,它只需要传一个Watermark,watermark会同时往下传,并且 1和2同时更新,sum最终只保持同时更新的状态,两个人保持一致。
总结:如果对于这个任务前面有多个并行度传递watermark,它只会取最小的watermark
如果watermark没有涨的话,对于整个世界来说都是静止的,即watermark不会往下游传递
即我们必须要搞一个比watermark还大的watermark往下传递,后面才可以进行运算
4.状态一致性
1.它保留状态的前提条件是所有任务处理完相同数据之后保留的状态
①直接接收完数据之后停掉,等所有人都处理完数据(效率低)
②基于 Chandy-Lamport 算法的分布式快照
当我们jobManager做checkpoint的时候,其实往数据流插入一个barrier(特殊的数据)
由于前面接收的barrier很多,当接收到所有barrier的时候,我们做checkpoint点(barrier对齐)
有两种情况
1.如果barrier已经到了,并且在其它barrier到来之前数据就来了,此时应该将数据缓存起来。(不能合并,数据不对)
2.barrier还没到的那条线数据来了,直接做计算
基于上面的理论,barrier一直往下传,最后传给了jobManager。当jobManager收到所有sink传的barrier之后,它就认为checkpoint真正的完成了。
2.端到端的一致性
首先看的是最弱的一环,
对于整个数据流来说是最好的时候
首先 source 是可重复提交offset
中间exactly once 做checkpoint
最后 幂等性(保证最终一致性)(生成环境更多的选择是幂等性 我们可以存储到hbase或es)
两阶段提交(它能保证完整的一致性)但是它对于外部系统要求特别高 比幂等性还高(很多外部系统sink不支持)(要求太高,很难实现)
5.CEP
主要用来做匹配模式事件
它可以处理匹配上的数据,还可以处理超时数据
超时数据传三个参数
1.侧输出流的标记
2.处理超时数据的业务逻辑
3.正常匹配上的业务逻辑
6.TableApI和TableSql
TableApIFlinkSql 一般用的是1.11版本 ,它对 flink-table-planner-blink_2.12 兼容性比较好。它可以支持Rank和Row_number
跟hive兼容性更好
Flinksql 自定义函数
四种 udf udaf udtf ( tableApi :join flat sql: lateral) 聚合炸裂函数(一般用来求topN)(只有tableAPI: flatAggregate,sql还没实现)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号