0.PTA得分截图
图题目集总得分,请截图,截图中必须有自己名字。题目至少完成总题数的2/3,否则本次作业最高分5分。没有全部做完扣1分。

1.本周学习总结(0-5分)
1.1 总结图内容
至少包括:
图存储结构:
1.邻接矩阵
typedef struct
{
int e; //图中边数
int n; //图中定点数
int edges[MAX][MAX];
}MGraph;
2.邻接表
typedef struct ANode
{
int adjvex; //该边的终点编号
struct ANode* nextarc; //指向下一条边的指针
int info; //该边的相关信息,如权重
} ArcNode; //边表节点类型
typedef int Vertex;
typedef struct Vnode
{
Vertex data; //顶点信息
int count;
ArcNode* firstarc; //指向第一条边
} VNode; //邻接表头节点类型
typedef VNode AdjList[MAXV];
typedef struct
{
AdjList adjlist; //邻接表
int n, e; //图中顶点数n和边数e
} AdjGraph;
图遍历及应用。包括DFS,BFS.如何判断图是否连通、如何查找图路径、如何找最短路径。
1.DFS
void DFS(MGraph g, int v)//深度遍历
{
visited[v-1] = 1;
if(flag1==0)
{
cout << v;
flag1=1;
}
else
{
cout<<" "<<v;
}
for (int j = 0; j < g.n; j++)
{
if (g.edges[v - 1][j] && !visited[j])
{
DFS(g, g.edges[v - 1][j]);
}
}
}
2.BFS
void BFS(MGraph g, int v)//广度遍历
{
int i;
if(flag2==0)
{
cout << v;
flag2=1;
}
else
{
cout<<" "<<v;
}
visited[v] = 1;
if(!q.empty())
q.pop();
for (int j = 0; j < g.n; j++)
{
if (g.edges[v - 1][j] && !visited[j+1])
{
visited[j+1] = 1;
q.push(j+1);
}
}
if (!q.empty())
BFS(g, q.front());
else return;
}
最小生成树相关算法及应用
1.Prim算法
接着开始我们的Prim算法的学习!首先我们先来认识下Prim算法的基础认识(后面我们会更加严谨的给出其定义与推算过程):通过选点来构造最小生成树,每次(第一次
可随意挑选)从中挑选当前最适合的(即选俩点的权值最小的,使构造的当前生成树最小)点来构造最小生成树。
void Prim(MGraph G, VertexType u)
{
//找到该起始点在顶点数组中的位置下标
int k = LocateVex(G, u);
//首先将与该起始点相关的所有边的信息:边的起始点和权值,存入辅助数组中相应的位置,例如(1,2)边,adjvex为0,lowcost为6,存入theclose[1]中,辅助数组的下标表示该边的顶点2
for (int i = 0; i < G.vexnum; i++) {
if (i != k) {
theclose[i].adjvex = k;
theclose[i].lowcost = G.arcs[k][i].adj;
}
}
//由于起始点已经归为最小生成树,所以辅助数组对应位置的权值为0,这样,遍历时就不会被选中
theclose[k].lowcost = 0;
//选择下一个点,并更新辅助数组中的信息
for (int i = 1; i < G.vexnum; i++)
{
//找出权值最小的边所在数组下标
k = minimun(G, theclose);
//输出选择的路径
theclose[k].lowcost = 0;
//信息辅助数组中存储的信息,由于此时树中新加入了一个顶点,需要判断,由此顶点出发,到达其它各顶点的权值是否比之前记录的权值还要小,如果还小,则更新
for (int j = 0; j < G.vexnum; j++)
{
if (G.arcs[k][j].adj < theclose[j].lowcost)
{
theclose[j].adjvex = k;
theclose[j].lowcost = G.arcs[k][j].adj;
}
}
}
}
2.Kruskal算法
Kruskal算法是基于贪心的思想得到的。首先我们把所有的边按照权值先从小到大排列,接着按照顺序选取每条边,如果这条边的两个端点不属于同一集合,那么就将它们合并,直到所有的点都属于同一个集合为止。
int Kruskal(int n, int m)
{
int nEdge = 0, res = 0;
//将边按照权值从小到大排序
qsort(a, n, sizeof(a[0]), cmp);
for (int i = 0; i < n && nEdge != m - 1; i++)
{
//判断当前这条边的两个端点是否属于同一棵树
if (find(a[i].a) != find(a[i].b))
{
unite(a[i].a, a[i].b);
res += a[i].price;
nEdge++;
}
}
//如果加入边的数量小于m - 1,则表明该无向图不连通,等价于不存在最小生成树
if (nEdge < m - 1) res = -1;
return res;
}
最短路径相关算法及应用,可适当拓展最短路径算法
1.Floyd算法
void ShortestPath_Floyd(MGraph g)
{
int Path[MAXV][MAXV]; //最短路径上顶点 vj 的前一顶点的序号
int [MAXV][MAXV]; //记录顶点 vi 和 vj 之间的最短路径长度
for(int i = 1; i < g.n; i++)
{
for(int j = 1; j < g.n; j++)
{
D[i][j] = g.edges[i][j];
if(D[i][j] < MAXINT && i != j)
{
Path[i][j] = i; //若 i 和 j 之间有弧,则将 j 的前驱置为 i;
}
else
{
Path[i][j] = -1; //若 i 和 j 之间有弧,则将 j 的前驱置为 -1;
}
}
}
for(int k = 0; k < g.n; k++)
{
for(int i = 1; i < g.n; i++)
{
for(int j = 1; j < g.n; j++)
{
if(D[i][k] + D[k][j] < D[i][j]) //从 i 经过 k 到 j 的路径更短
{
D[i][j] = D[i][k] + D[k][j]; //更新路径长
Path[i][j] = Path[k][j]; //更改 j 的前驱为 k
}
}
}
}
}
2.Dijkstra 算法
void Djjkstra(MGraph g, int v0)
{
int v;
int min;
int Path[MAXV];
int S[MAXV];
int D[MAXV];
/*对各个辅助结构初始化*/
for(int i = 0; i < g.n; i++)
{
S[i] = false; //S 初始化为全部单元 false,表示空集
D[i] = g.edges[v0][i]; //将 v0 到各个终点的最短路径初始化为直达路径
if(D[i] < INFINITY) //v0 到 i 的弧存在,设置前驱为 v0
{
Path[i] = v0;
}
else //v0 到 i 的弧不存在,设置前驱为 -1
{
Path[i] = -1;
}
}
S[v0] = true; //将 v0 加入集合 S
D[v0] = 0; //出发到到其本身的距离为 0
/*初始化结束,开始循环添加点*/
for(int i = 1; i < g.n; i++) //依次考虑剩余的 n - 1 个顶点
{
min = INFINITY;
for(int j = 0; j < g.n; j++)
{
if(S[j] == false && D[j] < min) //若 vj 未被添加入集合 S 且路径最短,拷贝信息
{
v = j; //表示选择当前最短路径,终点是 v
min = D[j];
}
}
s[v] = true; //将点 v 加入集合 S
for(int j = 0; j < g.n; j++)
{
if(S[j] == false && (D[v] + g.edges[v][j] < D[j])) //判断是否要修正路径
{
D[j] = D[v] + g .edges[v][j];
Path[j] = v; //修改 vj 的前驱为 v
}
}
}
}
拓扑排序、关键路径
void TopSort(AdjGraph* G) //拓扑排序算法
{
priority_queue <int, vector<int>, greater<int> > q;
int i, j;
int m;
int min;
int k = 0;
stack<int>s;
int count = 0;
if (G->e == 0)
{
for (k = 1; k <= G->n; k++)
{
cout << k << " ";
}
cout << endl;
return;
}
ArcNode* p;
for (i = 1; i <= G->n; i++) //入度置初值0
G->adjlist[i].count = 0;
for (i = 1; i <= G->n; i++) //求所有顶点的入度
{
p = G->adjlist[i].firstarc;
while (p != NULL)
{
G->adjlist[p->adjvex].count++;
p = p->nextarc;
}
}
min = G->n + 1;
for (i = 1; i <= G->n; i++)
if (G->adjlist[i].count == 0&&i<min)min = i;
if(min<G->n+1)s.push(min);
while (!s.empty()) //栈不空循环
{
i = s.top();
visited[i] = 1;
s.pop();
out[k++] = i;
count++;
p = G->adjlist[i].firstarc; //找第一个邻接点
while (p != NULL) //将顶点i的出边邻接点的入度减1
{
j = p->adjvex;
G->adjlist[j].count--;
p = p->nextarc;
}
min = G->n+1 ;
for (m = 1; m <= G->n; m++)
if (G->adjlist[m].count == 0 && m < min&&visited[m]==0)min = m;
if(min<G->n+1)s.push(min);
}
if (count != G->n)
{
cout << -1 << " " << endl;
return;
}
else
{
for (k = 0; k < G->n; k++)
{
cout << out[k] << " ";
}
cout << endl;
}
}
if(idx < G.n)
return false; //图出现回路
return true;
}
1.2.谈谈你对图的认识及学习体会。
1.图存储结构相对于树结构难度有所提升,要很好理解图结构才能在代码上实现
2.图的应用:路由路径搜索,其中设备到设备之间寻求最短路径传输数据包时有应用到迪杰斯特拉算法:GPS定位中寻求两点间的最短路径问题中使用的数据结构就为图。现实生活中每个人的社交群都可用图结构来表示;知识图谱中很多知识点之间互相有关联,可用图结构来表示;外出旅游,选择最短路线或最便宜路线时,也有应用图结构,其中不同道路的路径长度或者驾车费用都可以表示为图结构中边的权值。
2.阅读代码(0--5分)
2.1 题目及解题代码
可截图,或复制代码,需要用代码符号渲染。题目截图后一定要清晰。

#define pii pair<int, int>
class Solution {
public:
int reachableNodes(vector<vector<int>>& edges, int M, int N) {
vector<vector<pii>> graph(N);
for (vector<int> edge: edges) {
int u = edge[0], v = edge[1], w = edge[2];
graph[u].push_back({v, w});
graph[v].push_back({u, w});
}
map<int, int> dist;
dist[0] = 0;
for (int i = 1; i < N; ++i)
dist[i] = M+1;
map<pii, int> used;
int ans = 0;
priority_queue<pii, vector<pii>, greater<pii>> pq;
pq.push({0, 0});
while (!pq.empty()) {
pii top = pq.top();
pq.pop();
int d = top.first, node = top.second;
if (d > dist[node]) continue;
dist[node] = d;
// Each node is only visited once. We've reached
// a node in our original graph.
ans++;
for (auto pair: graph[node]) {
// M - d is how much further we can walk from this node;
// weight is how many new nodes there are on this edge.
// v is the maximum utilization of this edge.
int nei = pair.first;
int weight = pair.second;
used[{node, nei}] = min(weight, M - d);
// d2 is the total distance to reach 'nei' (neighbor) node
// in the original graph.
int d2 = d + weight + 1;
if (d2 < min(dist[nei], M+1)) {
pq.push({d2, nei});
dist[nei] = d2;
}
}
}
// At the end, each edge (u, v, w) can be used with a maximum
// of w new nodes: a max of used[u, v] nodes from one side,
// and used[v, u] nodes from the other.
for (vector<int> edge: edges) {
int u = edge[0], v = edge[1], w = edge[2];
ans += min(w, used[{u, v}] + used[{v, u}]);
}
return ans;
}
};
2.1.1 该题的设计思路
将原始图作为加权无向图处理,我们可以使用 Dijkstra 算法查找原始图中的所有可到达结点。 但是,这不足以解决仅部分使用细分边的示例。
当我们沿着边(沿任一方向)行进时,我们可以跟踪我们使用它的程度。最后,我们想知道我们在原始图中到达的每个结点,以及每条边的利用率之和。
时间复杂度:O(elogN)
空间复杂度:O(N)
2.1.3 运行结果
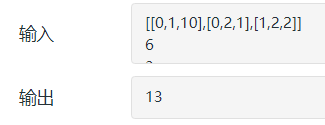
2.1.4分析该题目解题优势及难点。
将原始的图转化为带权无向图,并利用迪杰特斯拉算法实现功能
2.2 题目及解题代码
可截图,或复制代码,需要用代码符号渲染。题目截图后一定要清晰。

class Solution {
public:
bool findWhetherExistsPath(int n, vector<vector<int>>& graph, int start, int target) {
if(n == 0)
return false;
vector<vector<int>> num(n);
for(auto g : graph){
num[g[0]].push_back(g[1]);
}
vector<int> visit(n , 0);
return dfs(num, visit, start, target);
}
private:
bool dfs(vector<vector<int>>& num, vector<int> &visit, int s, int e){
if(s == e){
return true;
}
visit[s] = 1;
bool res;
for(int i = 0; i < num[s].size(); ++i){
if(visit[num[s][i]] == 0){
res = dfs(num, visit, num[s][i], e);
}
if(res)
return true;
}
visit[s] = 0;
return false;
}
};
2.2.1 该题的设计思路
利用DFS算法实现
时间复杂度:O(n+e)
空间复杂度:o(n^2)
2.2.2伪代码
bool findWhetherExistsPath(int n, vector<vector<int>>& graph, int start, int target)
{
if n为0
返回 false
定义voctor容器num(n)
for i = 0 to graph
g[1]入num[g[0]]
定义voctir容器visit(n,0)
返回dfs的返回值
}
bool dfs(vector<vector<int>>& num, vector<int>& visit, int s, int e)
{
if s == e
返回true
visit[s]=1
定义bool类型的res
for i = 0 to num[s].size
if 未访问
res=dfs对e的遍历
if res
返回 true
visit[s] = 0;
返回 false
}
2.2.3 运行结果

2.2.4分析该题目解题优势及难点。
利用DFS对图进行遍历,考验对DFS算法的熟悉程度
2.3 题目及解题代码

class Solution {
public:
bool isBipartite(vector<vector<int>>& graph) {
vector<int>col(graph.size(),-1);
for(int i=0;i<col.size();i++)
{
if(col[i]==-1)
{
col[i]=0;
if(!dfs(graph,col,i,1))return 0;
}
}
return 1;
}
inline bool dfs(vector<vector<int>>&graph,vector<int>&col,int i,int tar)
{
for(int j=0;j<graph[i].size();j++)
{
if(col[graph[i][j]]==-1)
{
col[graph[i][j]]=tar;
if(!dfs(graph,col,graph[i][j],1-tar))return false;
}
else if(col[graph[i][j]]!=tar)return false;
}
return true;
}
};
2.3.1 该题的设计思路
给定一个无向图graph,当这个图为二分图时返回true。如果我们能将一个图的节点集合分割成两个独立的子集A和B,并使图中的每一条边的两个节点一个来自A集合,一个来自B集合,我们就将这个图称为二分图。graph将会以邻接表方式给出,graph[i]表示图中与节点i相连的所有节点。每个节点都是一个在0到graph.length-1之间的整数。这图中没有自环和平行边: graph[i] 中不存在i,并且graph[i]中没有重复的值。
2.3.2
核心内容伪代码
bool isBipartite(vector<vector<int>>& graph)
{
定义voctor容器isBipartite, col
for i = 0 to col.size
if col[i] = -1
令其等于0
if 不是dfs序列颜色 返回0
返回1
}
inline bool dfs(vector<vector<int>>& graph, vector<int>& col, int i, int tar)
{
for i = 0 to graph[i].size
if col[graph[i].size]未被标记
标记为1
if 不是dfs的颜色序列 返回false
else if 不是dfs的颜色序列
返回false
返回true
}
2.3.3 运行结果

2.3.4分析该题目解题优势及难点。
这题其实类似于PTA上编程题第一题的图着色问题,我们只需要用两种颜色来“染”相邻边,然后判断后序结点中是否有某个点拥有和他相同颜色的点即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号