
过拟合问题详解
具体内容来自于读芯术:https://mp.weixin.qq.com/s?__biz=MzI2NjkyNDQ3Mw==&mid=2247487002&idx=1&sn=05d13bd67a31e38434285c5f0262b95d&chksm=ea87f6ccddf07fdae17a71819ba0577d099bb49b291093e7c6c7927456febfb3d8d308c30ad6&scene=21#wechat_redirect
理论部分:
过拟合可以从以下几个方面进行解释:
1. 模型复杂度:
从模型的角度上看,参数越多,模型的复杂度越高。高复杂度的模型也叫做高容量的模型,对于很多不同种类的数据都能有很好的拟合效果。模型的复杂度越高,越容易过拟合。
2. 性能度量的必然结果:
一个模型是否能够准确的预测,需要有一个度量标准,典型的度量标准有均方误差,指数误差等。性能度量衡量的是数据的拟合能力,训练集上模型的误差小,说明模型在训练集能够很好的拟合,但是机器学习的目的并不是拟合训练集,而是为了预测,是为了获取预测能力强的模型。
误差的一种理解是预测值和真实值之间的差值,另一种理解是偏差+方差+噪声的值。
偏差,指的是样本预测值的平均值和样本真实值之间的差距,它体现的模型的拟合能力。
方差,指的是样本预测值偏离样本预测平均值的程度,它体现的是模型的泛化能力。
噪声取决于数据,一般认为它的期望值为0。
如果一个模型在训练集上表现优异,但是测试集上表现很差,是过拟合的典型表现。
如果一个模型在训练集上表现就很差的话,说明该模型欠拟合。缓解欠拟合问题可以通过增加模型复杂度和增加训练数据
降低过拟合的方法:
1. early stopping
2. 在高方差的情况下,可以通过增加训练数据和减少特征维度来减少测试误差
3. 正则化:L1正则化和L2正则化, L1正则化和L2正则化都能够衰减权重,但是前者可以让权重为0,这是一种重要的稀疏表示的方式,后者只会让权重趋于0,但是不会等于0.
经典解释图: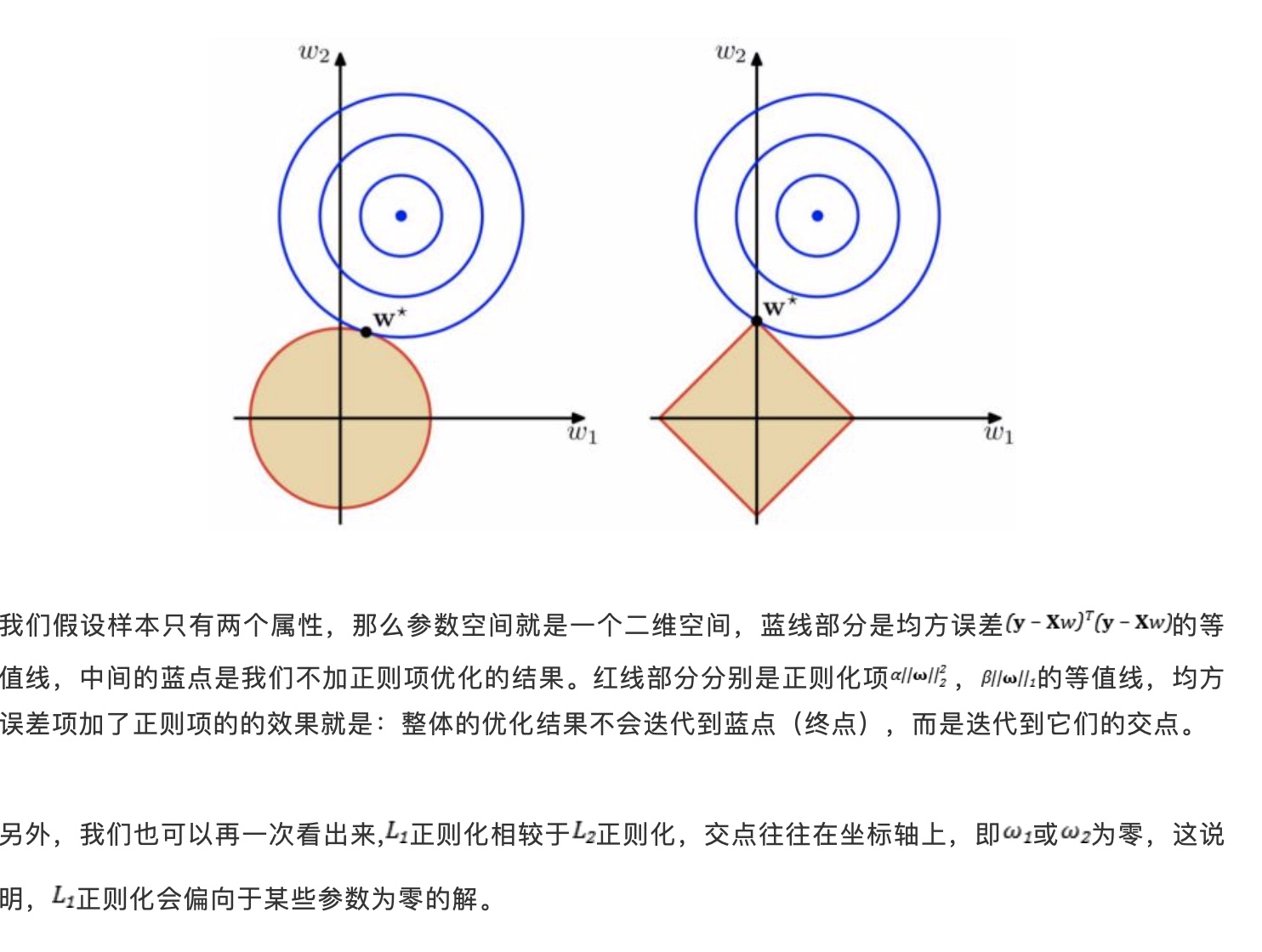
用贝叶斯的框架解释的化,L1本质上是加了均值为0的拉普拉斯先验,而L2是加了均值为0的高斯先验。
对数据进行特征选择的过程,也可以理解成一种降低过拟合的手段,因为特征的减少也就一定程度上减少了模型复杂度。尤其是存在多重共线性问题时,L1正则化具有使得权重稀疏缩减为0的特性,实际上就是去除了线性相关的特征。
4. dropout, 通过一定的概率去除某些神经元的连接权重的方式来形成多个模型,而且这些模型之间天然就具备了参数共享的特性。
代码部分:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号