【数仓开发】5-Excel模板生成HiveDDL建表SQL
根据excel模板生成Hive DDL建表SQL
1.excel模板
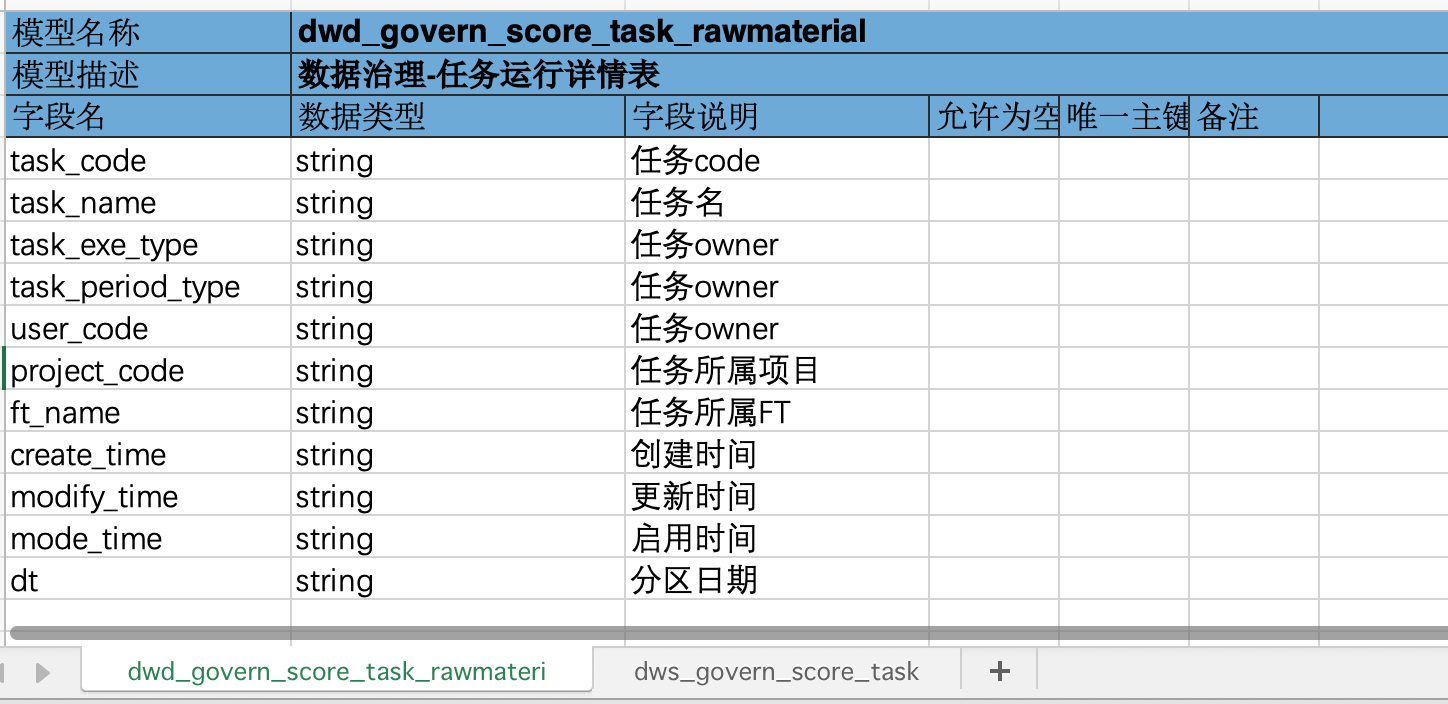
2.excel_gen_ddl_sql.py
#!/usr/bin/python
# -*- coding: utf-8 -*-
"""
功能: excel数据仓库物理模型生成 ddl_表名.sql文件
输入数据:文件名以「数据模型.xls or 数据模型.xlsx」结尾
输出数据:ddl_表名.sql
"""
import os
import numpy as np
import pandas as pd
from pandas import DataFrame
#正则
import re
# HDFS 数据仓库路径
HDFS_DIR = "'hdfs://host:8020/dw/"
# todo 读Excel生成sql文件
def read_excel_gen_sql(file, stored_as="orc", field_delimited="\\t", collection_delimited="-", map_delimited=":"):
excel = pd.read_excel(file, None)
sheet_names = excel.keys()
for sheet_name in sheet_names:
#sheet页以ods、dwd、dim、dws、ads开头
if re.match("^ods.*|^dwd.*|^dim.*|^dws.*|^ads.*",sheet_name):
df = DataFrame(pd.read_excel(file, sheet_name))
# 获取表名和表注释
table_name = df.columns.values[1]
table_comment = df.iloc[0][1]
# 准备获取属性字段
# 删除第一行和第二行无用数据
df.drop([0, 1], inplace=True)
# 删除空行
df.dropna(axis='index', how='all', inplace=True)
# 取出分区字段行
partition_row = np.array(df[-1:]).tolist()[0]
# 获取分区字段名
partition_field_name = partition_row[0]
# 获取分区字段类型
partition_field_type = partition_row[1]
# 判断是否存在分区字段 "dt"
if partition_field_name == "dt":
# 删除分区行,获得所有字段
field_df = df[:-1]
else:
# 获得所有字段
field_df = df
# 获取所有列名
columns = df.columns.values
# 获取字段名
field_name = field_df[columns[0]]
# 获取字段类型
field_type = field_df[columns[1]]
# 获取字段注释
field_comment = field_df[columns[2]]
sql_template = "create table if not exists " + table_name.lower() + " (\n"
count = 1
# 遍历所有字段
for i in field_name.keys():
sql_template += " " + str(field_name[i].lower()) + " " \
+ str(field_type[i]) + " comment \'" + str(field_comment[i]) + "\'"
if count == len(field_name):
sql_template += "\n"
else:
sql_template += ",\n"
count += 1
# 判断是否存在分区字段"dt"
# print(partition_field_name)
if partition_field_name != "dt":
sql_template = sql_template + ")\n" + "comment '" + table_comment + "' \n" \
+ "stored as " + stored_as + " \n" \
+ "location " + HDFS_DIR + table_name[0:3] + "/" + table_name.lower() + "';\n"
else:
sql_template = sql_template + ")\n" + "comment '" + table_comment + "' \n" \
+ "partitioned by(" + partition_field_name + " " + partition_field_type + ") \n" \
+ "row format delimited '" + field_delimited + "' \n" \
+ "stored as " + stored_as + " \n" \
+ "location " + HDFS_DIR + table_name[0:3].lower() + "/" + table_name.lower() + "';\n"
print(sql_template)
# 创建 ddl 文件
file_name = "ddl_" + sheet_name.lower() + ".sql"
# 创建文件对象,覆盖写方式
file_object = open(file_name, 'w')
try:
# 创建文件
file_object.write(sql_template)
finally:
# 关闭文件对象
file_object.close()
# todo 遍历目录下【数据模型.xls】、【数据模型.xlsx】 结尾 excel生成sql文件
def read_dir_gen_sql(dir_name):
file_list = os.listdir(dir_name)
print(file_list)
for file in file_list:
# 处理【数据模型.xls】、【数据模型.xlsx】 结尾的文件
if file.endswith('数据模型.xls') or file.endswith('数据模型.xlsx'):
# 生成建表文件
read_excel_gen_sql(file)
if __name__ == '__main__':
# 当前目录
# read_dir_gen_sql('.')
# 指定文件
file = "/Users/didi/mine/software/idea/code/python_study/gen_sql_ddl/数据治理_生成域_数据模型.xlsx"
read_excel_gen_sql(file)
3.使用说明
1.默认读取和py文件同级目录的以 【数据模型.xls】、【数据模型.xlsx】 结尾 文件,eg:也可以改读文件代码逻辑。
2.在字段转换的会报错,转换str异常,看看表格是否都填充完。
2.excel要保存好,在编辑中,会生成一个‘~$dwd_govern_score_task_rawmaterial_数据模型.xlsx’这种文件,会报错。
3.excel可以多个sheet页,命名以 ods、dwd、dws、ads、dim前缀命名。
4.默认会有LOCATION的路径,可选择不用。
报错
sql_template += " " + str(field_name[i].lower()) + " " \
AttributeError: 'float' object has no attribute 'lower'
原因:字段、字段类型、字段说明有空值


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 25岁的心里话
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现