实时数仓(二):DWD层-数据处理
实时数仓(二):DWD层-数据处理
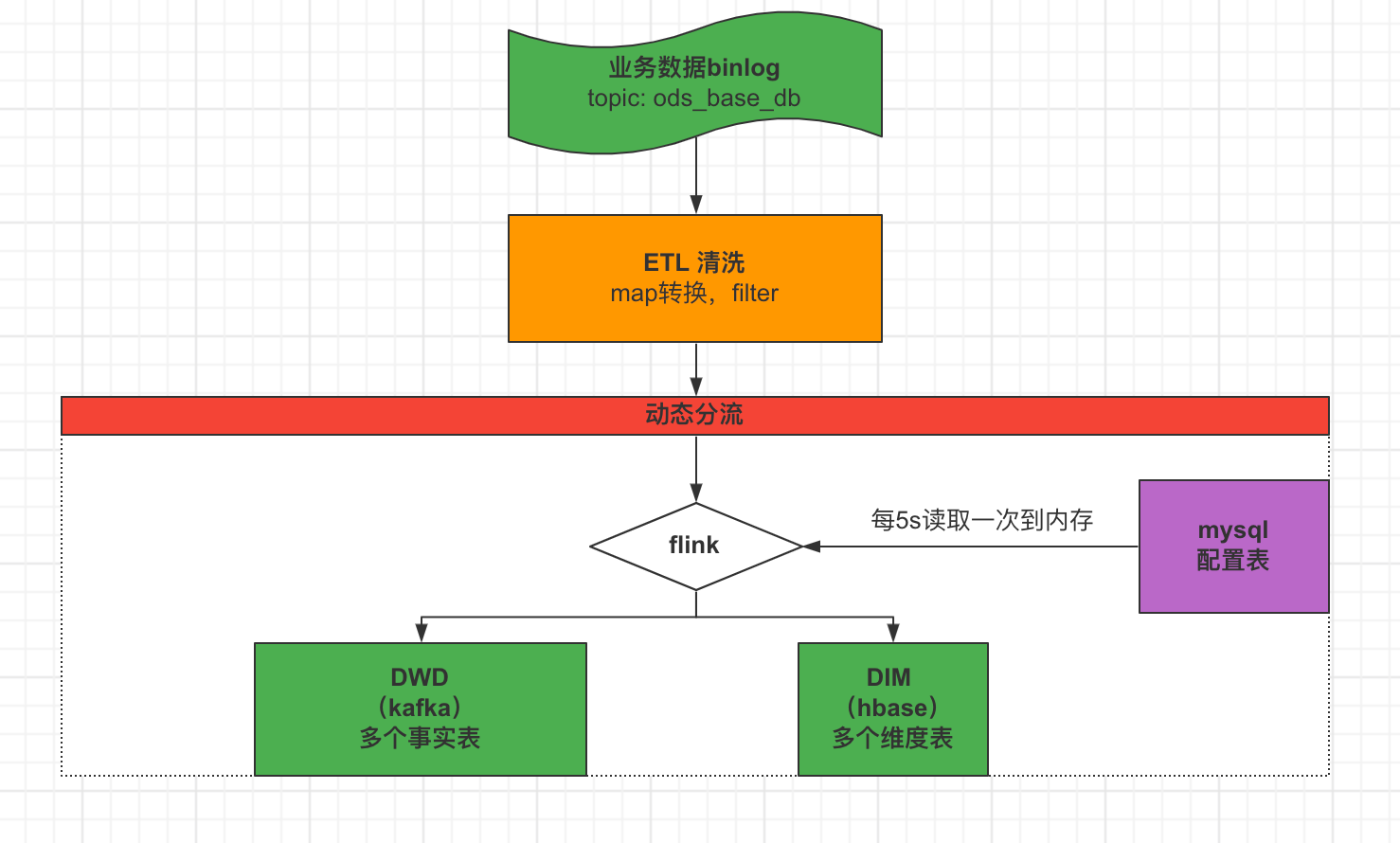
1.数据源
dwd的数据来自Kafka的ods层原始数据:业务数据(ods_base_db) 、日志数据(ods_base_log)
从Kafka的ODS层读取用户行为日志以及业务数据,并进行简单处理,写回到Kafka作为DWD层。
2.用户行为日志
2.1开发环境搭建
1)包结构
2)pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>03_gmall2021</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<java.version>1.8</java.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
<flink.version>1.12.0</flink.version>
<scala.version>2.12</scala.version>
<hadoop.version>3.1.3</hadoop.version>
</properties>
<dependencies>
<!-- flink Web UI -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_2.11</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.68</version>
</dependency>
<!--如果保存检查点到hdfs上,需要引入此依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!--Flink默认使用的是slf4j记录日志,相当于一个日志的接口,我们这里使用log4j作为具体的日志实现-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
</dependency>
<dependency>
<groupId>com.alibaba.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>1.2.0</version>
</dependency>
<!--lomback插件依赖-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-spark</artifactId>
<version>5.0.0-HBase-2.0</version>
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--commons-beanutils是Apache开源组织提供的用于操作JAVA BEAN的工具包。
使用commons-beanutils,我们可以很方便的对bean对象的属性进行操作-->
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
<version>1.9.3</version>
</dependency>
<!--Guava工程包含了若干被Google的Java项目广泛依赖的核心库,方便开发-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>29.0-jre</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.2.4</version>
<exclusions>
<exclusion>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</exclusion>
<exclusion>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
3)MykafkaUtil.java
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.producer.ProducerConfig;
import java.util.Arrays;
import java.util.List;
import java.util.Properties;
public class MyKafkaUtil {
private static Properties properties = new Properties();
private static String DEFAULT_TOPIC = "dwd_default_topic";
static {
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092,hadoop104:9092");
}
/**
* todo kafka sink:自定义序列化,各种类型自定义传输
*
* @return
*/
public static <T> FlinkKafkaProducer<T> getKafkaSinkBySchema(KafkaSerializationSchema<T> kafkaSerializationSchema) {
Properties props = new Properties();
//kafka地址
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092,hadoop104:9092");
//生产数据超时时间
props.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 15 * 60 * 1000 + "");
return new FlinkKafkaProducer<T>(DEFAULT_TOPIC, kafkaSerializationSchema, props, FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
}
/**
* 获取生产者对象 ,只能传输String类型
*
* @param topic 主题
*/
public static FlinkKafkaProducer<String> getFlinkKafkaProducer(String topic) {
return new FlinkKafkaProducer<String>(topic,
new SimpleStringSchema(),
properties);
}
/**
* todo 构建消费者 -> 优化
*
* @param bootstrapServers:kafka地址
* @param topic :topic可以用逗号分隔
* @param groupId:消费者组
* @param isSecurity:是否kafka设置sasl
* @param offsetStrategy:消费策略:3种
* @return
*/
public static FlinkKafkaConsumer<String> getKafkaConsumer(String bootstrapServers, String topic, String groupId, String isSecurity, String offsetStrategy) {
SimpleStringSchema simpleStringSchema = new SimpleStringSchema();
Properties props = new Properties();
props.setProperty("bootstrap.servers", bootstrapServers);
props.setProperty("group.id", groupId);
props.setProperty("flink.partition-discovery.interval-millis", "60000");
//kafka开启sasl认证
if ("true".equalsIgnoreCase(isSecurity)) {
props.setProperty("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"\" password=\"\";");
props.setProperty("security.protocol", "SASL_PLAINTEXT");
props.setProperty("sasl.mechanism", "PLAIN");
}
//消费多个topic
String[] split = topic.split(",");
List<String> topics = Arrays.asList(split);
//kafka消费者
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>(topics, simpleStringSchema, props);
//消费方式:earliest,latest,setStartFromTimestamp
switch (offsetStrategy) {
case "earliest":
consumer.setStartFromEarliest();
return consumer;
case "latest":
consumer.setStartFromLatest();
return consumer;
default:
consumer.setStartFromTimestamp(System.currentTimeMillis() - Integer.valueOf(offsetStrategy) * 60 * 1000);
return consumer;
}
}
/**
* 获取消费者对象
*
* @param topic 主题
* @param groupId 消费者组
*/
public static FlinkKafkaConsumer<String> getFlinkKafkaConsumer(String topic, String groupId) {
//添加消费组属性
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, groupId);
return new FlinkKafkaConsumer<String>(topic,
new SimpleStringSchema(),
properties);
}
//拼接Kafka相关属性到DDL
public static String getKafkaDDL(String topic, String groupId) {
return "'connector' = 'kafka', " +
" 'topic' = '" + topic + "'," +
" 'properties.bootstrap.servers' = 'hadoop102:9092', " +
" 'properties.group.id' = '" + groupId + "', " +
" 'format' = 'json', " +
" 'scan.startup.mode' = 'latest-offset'";
}
}
4)log4j.properties
log4j.rootLogger=info,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
2.2 实现功能
我们前面采集的日志数据已经保存到Kafka中,作为日志数据的ODS层,从Kafka的ODS层读取的日志数据分为3类, 页面日志、启动日志和曝光日志。这三类数据虽然都是用户行为数据,但是有着完全不一样的数据结构,所以要拆分处理。将拆分后的不同的日志写回Kafka不同主题中,作为日志DWD层。
页面日志输出到主流,启动日志输出到启动侧输出流,曝光日志输出到曝光侧输出流
- 1)从kafka读取ods数据
- 2)判断新老用户
- 3)分流
- 4)写回到kafka的dwd层
1)代码实现
package com.flink.realtime.app.dwd;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.flink.realtime.utils.MyKafkaUtil;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* @description: todo->准备用户行为日志dwd层
* @author: HaoWu
* @create: 2021年06月22日
*/
public class BaseLogApp {
public static void main(String[] args) throws Exception {
// TODO 1.获取执行环境
// 1.1 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 1.2 并行度设置为Kafka的分区数
env.setParallelism(4);
/*
// 1.3 设置checkpoint
env.enableCheckpointing(5000L); //每5000ms做一次ck
env.getCheckpointConfig().setCheckpointTimeout(60000L); // ck超时时间:1min
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); //ck模式,默认:exactly_once
//正常Cancel任务时,保留最后一次CK
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//重启策略
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000L));
//状态后端:
env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/gmall/checkpoint/base_log_app"));
// 访问hdfs访问权限问题
// 报错异常:Permission denied: user=haowu, access=WRITE, inode="/":atguigu:supergroup:drwxr-xr-x
// 解决:/根目录没有写权限 解决方案1.hadoop fs -chown 777 / 2.System.setProperty("HADOOP_USER_NAME", "atguigu");
System.setProperty("HADOOP_USER_NAME", "atguigu");
*/
//TODO 2.获取kafka ods_base_log 主题数据
String sourceTopic = "ods_base_log";
String groupId = "base_log_app_group";
//FlinkKafkaConsumer<String> consumer = MyKafkaUtil.getFlinkKafkaConsumer(sourceTopic, groupId);
FlinkKafkaConsumer<String> consumer = MyKafkaUtil.getKafkaConsumer("hadoop102:9092", sourceTopic, groupId, "false", "earliest");
DataStreamSource<String> kafkaDS = env.addSource(consumer);
//TODO 3.将每行数据转换为JSONObject
// 处理脏数据
OutputTag<String> dirty = new OutputTag<String>("DirtyData") {};
SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.process(new ProcessFunction<String, JSONObject>() {
@Override
public void processElement(String value, Context context, Collector<JSONObject> collector) throws Exception {
try {
JSONObject jsonObject = JSON.parseObject(value);
//转JSON对象
collector.collect(jsonObject);
} catch (Exception e) {
//JSON解析异常输出脏数据
context.output(dirty, value);
}
}
});
//jsonObjDS.print("json>>>>>>>>");
//TODO 4.按照设备ID分组、使用状态编程做新老用户校验
//4.1 根据mid对日志进行分组
SingleOutputStreamOperator<JSONObject> jsonObjWithNewFlag = jsonObjDS.keyBy(json -> json.getJSONObject("common").getString("mid"))
.process(new KeyedProcessFunction<String, JSONObject, JSONObject>() {
//声明状态用于表示当前Mid是否已经访问过
private ValueState<String> firstVisitDateState;
private SimpleDateFormat simpleDateFormat;
//初始化状态
@Override
public void open(Configuration parameters) throws Exception {
firstVisitDateState = getRuntimeContext().getState(new ValueStateDescriptor<String>("new-mid", String.class));
simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
}
@Override
public void processElement(JSONObject value, Context ctx, Collector<JSONObject> out) throws Exception {
//取出新用户标记 :is_new:1->新用户 ,0->老用户
String isNew = value.getJSONObject("common").getString("is_new");
//如果当前前端传输数据表示为新用户,则进行校验
if ("1".equals(isNew)) {
//取出状态数据并取出当前访问时间
String firstDate = firstVisitDateState.value();
Long ts = value.getLong("ts");
//判断状态数据是否为Null
if (firstDate != null) {
//修复
value.getJSONObject("common").put("is_new", "0");
} else {
//更新状态
firstVisitDateState.update(simpleDateFormat.format(ts));
}
}
out.collect(value);
}
});
//测试打印
//jsonObjWithNewFlag.print();
//TODO 5.使用侧输出流将 启动、曝光、页面数据分流
OutputTag<String> startOutPutTag = new OutputTag<String>("start"){}; //启动
OutputTag<String> displayOutputTag = new OutputTag<String>("display"){}; //曝光
SingleOutputStreamOperator<String> pageDS = jsonObjWithNewFlag.process(new ProcessFunction<JSONObject, String>() {
@Override
public void processElement(JSONObject value, Context ctx, Collector<String> out) throws Exception {
//判断是否为启动数据
String start = value.getString("start");
if (start != null && start.length() > 0) {
//启动数据
ctx.output(startOutPutTag, value.toJSONString());
} else {
//不是启动数据一定是页面数据
out.collect(value.toJSONString());
//抽取公共字段、页面信息、时间戳
JSONObject common = value.getJSONObject("common");
JSONObject page = value.getJSONObject("page");
Long ts = value.getLong("ts");
//获取曝光数据
JSONArray displayArr = value.getJSONArray("displays");
if (displayArr != null && displayArr.size() > 0) {
JSONObject displayObj = new JSONObject();
displayObj.put("common", common);
displayObj.put("page", page);
displayObj.put("ts", ts);
//遍历曝光信息
for (Object display : displayArr) {
displayObj.put("display", display);
//输出曝光数据到侧输出流
ctx.output(displayOutputTag, displayObj.toJSONString());
}
}
}
}
});
//TODO 6.将三个流的数据分别写入Kafka
//打印
jsonObjDS.getSideOutput(dirty).print("Dirty>>>>>>>>>>>");
//主流:页面
pageDS.print("Page>>>>>>>>>>>");
//侧流:启动
pageDS.getSideOutput(startOutPutTag).print("Start>>>>>>>>>>>>");
//侧流:曝光
pageDS.getSideOutput(displayOutputTag).print("Display>>>>>>>>>>>>>");
//输出到kafka
String pageSinkTopic = "dwd_page_log";
String startSinkTopic = "dwd_start_log";
String displaySinkTopic = "dwd_display_log";
pageDS.addSink(MyKafkaUtil.getFlinkKafkaProducer(pageSinkTopic));
pageDS.getSideOutput(startOutPutTag).addSink(MyKafkaUtil.getFlinkKafkaProducer(startSinkTopic));
pageDS.getSideOutput(displayOutputTag).addSink(MyKafkaUtil.getFlinkKafkaProducer(displaySinkTopic));
env.execute();
}
}
2)部署运行
BaseLogApp.sh
#!/bin/bash
source ~/.bashrc
cd $(dirname $0)
day=$(date +%Y%m%d%H%M)
#flink
job_name=02_dwd_BaseLogApp
clazz=com.flink.realtime.app.dwd.BaseLogApp
jar_path=/opt/module/gmall-flink/03_gmall2021-1.0-SNAPSHOT-jar-with-dependencies.jar
#-----------------------run----------------------------------------------
#yarn模式:per-job
/opt/module/flink-1.12.0/bin/flink run \
-t yarn-per-job \
-Dyarn.application.name=${job_name} \
-Dyarn.application.queue=default \
-Djobmanager.memory.process.size=1024m \
-Dtaskmanager.memory.process.size=1024m \
-Dtaskmanager.numberOfTaskSlots=2 \
-c ${clazz} ${jar_path}
3.业务数据
3.1 实现功能
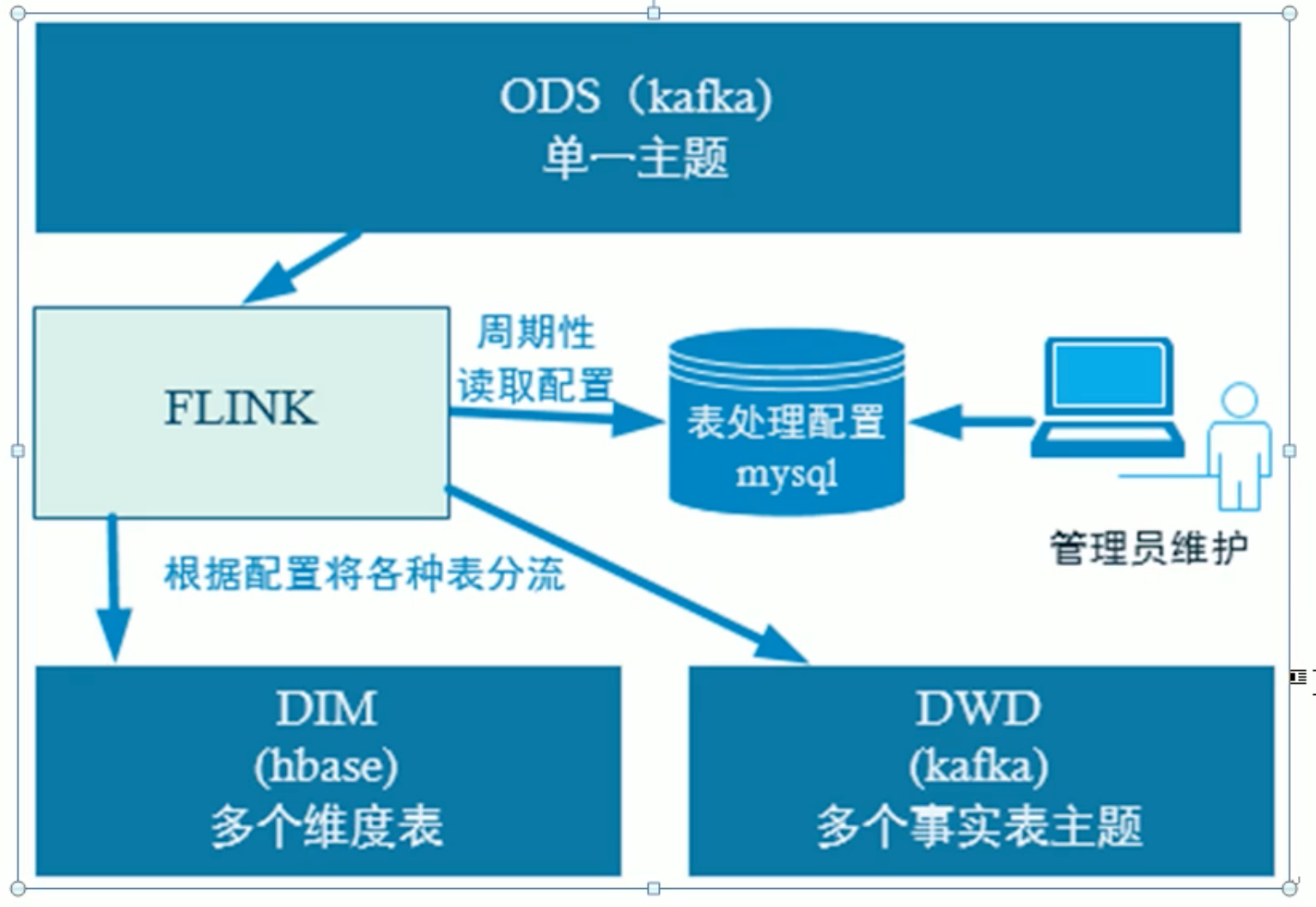
业务数据的变化,我们可以通过FlinkCDC采集到,但是FlinkCDC是把全部数据统一写入一个Topic中, 这些数据包括事实数据,也包含维度数据,这样显然不利于日后的数据处理,所以这个功能是从Kafka的业务数据ODS层读取数据,经过处理后,将维度数据保存到HBase,将事实数据写回Kafka作为业务数据的DWD层。
3.2 动态分流
由于FlinkCDC是把全部数据统一写入一个Topic中, 这样显然不利于日后的数据处理。所以需要把各个表拆开处理。但是由于每个表有不同的特点,有些表是维度表,有些表是事实表。
在实时计算中一般把维度数据写入存储容器,一般是方便通过主键查询的数据库比如HBase,Redis,MySQL等。一般把事实数据写入流中,进行进一步处理,最终形成宽表。
这样的配置不适合写在配置文件中,因为这样的话,业务端随着需求变化每增加一张表,就要修改配置重启计算程序。所以这里需要一种动态配置方案,把这种配置长期保存起来,一旦配置有变化,实时计算可以自动感知。
这种可以有两个方案实现
-
一种是用Zookeeper存储,通过Watch感知数据变化。
-
另一种是用mysql数据库存储,周期性的同步。
这里选择第二种方案,主要是MySQL对于配置数据初始化和维护管理,使用FlinkCDC读取配置信息表,将配置流作为广播流与主流进行连接。
1)建配置表:create.sql
--配置表
CREATE TABLE `table_process` (
`source_table` varchar(200) NOT NULL COMMENT '来源表',
`operate_type` varchar(200) NOT NULL COMMENT '操作类型 insert,update,delete',
`sink_type` varchar(200) DEFAULT NULL COMMENT '输出类型 hbase kafka',
`sink_table` varchar(200) DEFAULT NULL COMMENT '输出表(主题)',
`sink_columns` varchar(2000) DEFAULT NULL COMMENT '输出字段',
`sink_pk` varchar(200) DEFAULT NULL COMMENT '主键字段',
`sink_extend` varchar(200) DEFAULT NULL COMMENT '建表扩展',
PRIMARY KEY (`source_table`,`operate_type`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
品牌维表
CREATE TABLE `base_trademark` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '编号',
`tm_name` varchar(100) NOT NULL COMMENT '属性值',
`logo_url` varchar(200) DEFAULT NULL COMMENT '品牌logo的图片路径',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=19 DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='品牌表'
--品牌表:base_trademark表 insert 操作,插入hbase的dim_base_trademark只要 `id`,`name` 字段, `id`作为主键
insert into table_process values ('base_trademark','insert','hbase','dim_base_trademark','id,name','id','');
mysql> select * from table_process;
+----------------+--------------+-----------+--------------------+--------------+---------+-------------+
| source_table | operate_type | sink_type | sink_table | sink_columns | sink_pk | sink_extend |
+----------------+--------------+-----------+--------------------+--------------+---------+-------------+
| base_trademark | insert | hbase | dim_base_trademark | id,name | id | |
+----------------+--------------+-----------+--------------------+--------------+---------+-------------+
1 row in set (0.00 sec)
2)配置类:TableProcess.java
import lombok.Data;
/**
* @description: TODO 配置表实体类
* @author: HaoWu
* @create: 2021年06月25日
*/
@Data
public class TableProcess {
//动态分流Sink常量
public static final String SINK_TYPE_HBASE = "hbase";
public static final String SINK_TYPE_KAFKA = "kafka";
public static final String SINK_TYPE_CK = "clickhouse";
//来源表
String sourceTable;
//操作类型 insert,update,delete
String operateType;
//输出类型 hbase kafka
String sinkType;
//输出表(主题)
String sinkTable;
//输出字段
String sinkColumns;
//主键字段
String sinkPk;
//建表扩展
String sinkExtend;
}
3)MysqlUtil.java
import com.flink.realtime.bean.TableProcess;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.flink.shaded.curator4.org.apache.curator.shaded.com.google.common.base.CaseFormat;
import java.lang.reflect.InvocationTargetException;
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
/**
* @description: TODO Mysql工具类
* @author: HaoWu
* @create: 2021年07月23日
* 完成ORM,对象关系映射
* O:Object对象 Java中对象
* R:Relation关系 关系型数据库
* M:Mapping映射 将Java中的对象和关系型数据库的表中的记录建立起映射关系
*/
public class MysqlUtil {
/**
* @param sql 执行sql语句
* @param clazz 封装bean类型
* @param underScoreToCamel 是否列名转驼峰命名
* @param <T>
* @return
*/
public static <T> List<T> queryList(String sql, Class<T> clazz, Boolean underScoreToCamel) {
Connection con = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
// 注册驱动
Class.forName("com.mysql.jdbc.Driver");
// 获取连接
con = DriverManager.getConnection("jdbc:mysql://hadoop102:3306/gmall-realtime?characterEncoding=utf-8&useSSL=false", "root", "root");
// 获取数据库操作对象
ps = con.prepareStatement(sql);
// 执行sql
rs = ps.executeQuery();
// 处理结果集,封装list对象
ResultSetMetaData metaData = rs.getMetaData(); //获取结果集元数据
ArrayList<T> resultList = new ArrayList<>();
while (rs.next()) {
// 将单条记录封装对象
T obj = clazz.newInstance();
// 遍历所有列,转驼峰,对象属性赋值
for (int i = 1; i < metaData.getColumnCount(); i++) {
String columnName = metaData.getColumnName(i);
String propertyName = "";
if (underScoreToCamel) {
// 通过guava工具类,将表中的列转换为类属性的驼峰命名
propertyName = CaseFormat.LOWER_UNDERSCORE.to(CaseFormat.LOWER_CAMEL, columnName);
}
// 给属性赋值
BeanUtils.setProperty(obj,propertyName,rs.getObject(i));
}
resultList.add(obj);
}
return resultList;
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException("从Mysql查询数据失败");
} finally {
// 释放资源
if (rs != null) {
try {
rs.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
if (ps != null) {
try {
ps.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
if (con != null) {
try {
con.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
}
}
public static void main(String[] args) throws InvocationTargetException, IllegalAccessException {
String sql="select * from table_process";
List<TableProcess> list = MysqlUtil.queryList(sql, TableProcess.class, true);
System.out.println(list);
TableProcess tableProcess = new TableProcess();
BeanUtils.setProperty(tableProcess,"sourceTable","redis");
System.out.println(tableProcess);
}
}
4)常量类:GmallConfig.java
package com.flink.realtime.common;
/**
* @description: TODO 常量配置类
* @author: HaoWu
* @create: 2021年06月25日
*/
public class GmallConfig {
//Phoenix库名
public static final String HBASE_SCHEMA = "bigdata";
//Phoenix驱动
public static final String PHOENIX_DRIVER = "org.apache.phoenix.jdbc.PhoenixDriver";
//Phoenix连接参数
public static final String PHOENIX_SERVER = "jdbc:phoenix:hadoop102,hadoop103,hadoop104:2181";
public static final String CLICKHOUSE_DRIVER = "ru.yandex.clickhouse.ClickHouseDriver";
public static final String CLICKHOUSE_URL = "jdbc:clickhouse://hadoop102:8123/default";
}
5)主程序:BaseDBApp.java
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.flink.realtime.app.func.DimSink;
import com.flink.realtime.app.func.TableProcessFunction;
import com.flink.realtime.bean.TableProcess;
import com.flink.realtime.utils.MyKafkaUtil;
import org.apache.flink.api.common.serialization.SerializationSchema;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;
import org.apache.flink.util.OutputTag;
import org.apache.kafka.clients.producer.ProducerRecord;
import javax.annotation.Nullable;
/**
* @description: todo->准备业务数据dwd层
* @author: HaoWu
* @create: 2021年06月22日
*/
public class BaseDbApp {
public static void main(String[] args) throws Exception {
// TODO 1.创建执行环境
// 1.1 创建stream执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 1.2 设置并行度
env.setParallelism(1);
/*
// 1.3 设置checkpoint参数
env.enableCheckpointing(5000L); //每5000ms做一次ck
env.getCheckpointConfig().setCheckpointTimeout(60000L); // ck超时时间:1min
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); //ck模式,默认:exactly_once
//正常Cancel任务时,保留最后一次CK
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//重启策略
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 5000L));
//状态后端:
env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/gmall/checkpoint/base_db_app"));
// 访问hdfs访问权限问题
// 报错异常:Permission denied: user=haowu, access=WRITE, inode="/":atguigu:supergroup:drwxr-xr-x
// 解决:/根目录没有写权限 解决方案1.hadoop fs -chown 777 / 2.System.setProperty("HADOOP_USER_NAME", "atguigu");
System.setProperty("HADOOP_USER_NAME", "atguigu");
*/
// TODO 2.获取kafka的ods层业务数据:ods_basic_db
String ods_db_topic = "ods_base_db";
FlinkKafkaConsumer<String> kafkaConsumer = MyKafkaUtil.getKafkaConsumer("hadoop102:9092", ods_db_topic, "ods_base_db_consumer1", "false", "latest");
DataStreamSource<String> jsonStrDS = env.addSource(kafkaConsumer);
//jsonStrDS.print();
// TODO 3.对jsonStrDS结构转换
SingleOutputStreamOperator<JSONObject> jsonDS = jsonStrDS.map(jsonStr -> JSON.parseObject(jsonStr));
// TODO 4.对数据ETL
SingleOutputStreamOperator<JSONObject> filterDS = jsonDS.filter(
json -> {
boolean flag = json.getString("table") != null //表名不为null
&& json.getString("data") != null //数据不为null
&& json.getString("data").length() >= 3; //数据长度大于3
return flag;
}
);
//filterDS.print("filterDS>>>>>>>>>>");
// TODO 5. 动态分流:事实表放-主流 -> kafka dwd层 ,维度表-侧输出流 -> hbase
// 5.1 定义输出到Hbase的侧输出流标签
OutputTag<JSONObject> hbaseTag = new OutputTag<JSONObject>(TableProcess.SINK_TYPE_HBASE) {
};
// 5.2 主流输出到kafka
SingleOutputStreamOperator<JSONObject> kafkaDS = filterDS.process(new TableProcessFunction(hbaseTag));
// 5.3 获取侧输出流到hbase
DataStream<JSONObject> hbaseDS = kafkaDS.getSideOutput(hbaseTag);
kafkaDS.print("实时:kafkaDS>>>>>>>>");
hbaseDS.print("维度:hbaseDS>>>>>>>>");
// TODO 6.维度数据保存到Hbase中
hbaseDS.addSink(new DimSink());
// TODO 7.实时数据保存到Kafka中,自定义序列化
FlinkKafkaProducer<JSONObject> kafkaSink = MyKafkaUtil.getKafkaSinkBySchema(new KafkaSerializationSchema<JSONObject>() {
@Override
public void open(SerializationSchema.InitializationContext context) throws Exception {
System.out.println("kafka序列化");
}
@Override
public ProducerRecord<byte[], byte[]> serialize(JSONObject jsonObject, @Nullable Long aLong) {
String sink_topic = jsonObject.getString("sink_table");
JSONObject data = jsonObject.getJSONObject("data");
return new ProducerRecord<>(sink_topic, data.toString().getBytes());
}
});
kafkaDS.addSink(kafkaSink);
// TODO 8.执行
env.execute();
}
}
6)自定义分流函数:TableProcessFunction.java
import com.alibaba.fastjson.JSONObject;
import com.flink.realtime.bean.TableProcess;
import com.flink.realtime.common.GmallConfig;
import com.flink.realtime.utils.MysqlUtil;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.*;
import java.util.List;
/**
* @description: TODO 业务数据分流自定义Process函数
* @author: HaoWu
* @create: 2021年07月26日
*/
public class TableProcessFunction extends ProcessFunction<JSONObject, JSONObject> {
//维表侧输出标签
private OutputTag<JSONObject> outputTag;
//内存中存储表配置对象{表名,表配置信息}
private Map<String, TableProcess> tableProcessMap = new HashMap<>();
//内存中判断是否已经存在Hbase表
private Set<String> existsTables = new HashSet<>();
//定义Phoenix连接
private Connection connection;
public TableProcessFunction() {
}
public TableProcessFunction(OutputTag<JSONObject> outputTag) {
this.outputTag = outputTag;
}
@Override
public void open(Configuration parameters) throws Exception {
//初始化phoenix连接
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
connection = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);
//初始化配置表信息
initTableProcessMap();
//配置表的信息可能会发生表更,需要开启定时任务从现在起5000ms后,每隔5000ms更新一次
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
initTableProcessMap();
}
}, 5000, 5000);
}
@Override
public void processElement(JSONObject jsonObj, Context ctx, Collector<JSONObject> out) throws Exception {
//表名
String tableName = jsonObj.getString("table");
//操作类型
String type = jsonObj.getString("type");
//注意:问题修复 如果使用maxwell同步历史数据,他的操作类型是bootstrap-insert
if ("bootstrap-insert".equals(type)) {
type = "insert";
jsonObj.put("type", type);
}
if (tableProcessMap != null && tableProcessMap.size() > 0) {
//根据key取出配置信息
String key = tableName + ":" + type;
TableProcess tableProcess = tableProcessMap.get(key);
//判断是否获取到配置对象
if (tableProcess != null) {
//获取sinkTable,指明数据发往何处。 维度数据->hbase , 事实数据->kafka ,给这条数据打上一个标记。
jsonObj.put("sink_table", tableProcess.getSinkTable());
//指定了sinkcolumn,对需要保留的字段进行过滤
String sinkColumns = tableProcess.getSinkColumns();
if (sinkColumns != null && sinkColumns.length() > 0) {
filterColumn(jsonObj.getJSONObject("data"), sinkColumns);
}
} else {
System.out.println("No this Key <<<< " + key + ">>>> in MySQL");
}
//根据sinkType输出到不同的流
if (tableProcess != null && tableProcess.getSinkType().equals(TableProcess.SINK_TYPE_HBASE)) {
//sinkType=hbase 输出到侧输出流
ctx.output(outputTag, jsonObj);
} else if (tableProcess != null && tableProcess.getSinkType().equals(TableProcess.SINK_TYPE_KAFKA)) {
//sinkType=kafka 输出到主流
out.collect(jsonObj);
}
}
}
/**
* 从mysql查询配置信息,保存到map内存中
*/
private void initTableProcessMap() {
System.out.println("查询配置表信息");
//1.从mysql中查询配置信息
List<TableProcess> tableProcesses = MysqlUtil.queryList("select * from table_process", TableProcess.class, true);
for (TableProcess tableProcess : tableProcesses) {
String sourceTable = tableProcess.getSourceTable(); //源表
String operateType = tableProcess.getOperateType(); //操作类型
String sinkType = tableProcess.getSinkType(); //目标表类型
String sinkTable = tableProcess.getSinkTable(); //目标表名
String sinkPk = tableProcess.getSinkPk(); //目标表主键
String sinkColumns = tableProcess.getSinkColumns(); //目标表字段
String sinkExtend = tableProcess.getSinkExtend(); //扩展字段
//2.将配置信息封装成map集合
tableProcessMap.put(sourceTable + ":" + operateType, tableProcess);
//3.检查是表是否内存中存在
//如果向Hbase保存的表,那么判断内存中set是否存在过。
if ("insert".equals(operateType) && "hbase".equals(sinkType)) {
boolean isExist = existsTables.add(sinkTable);
//4.如果内存中不存在表数据信息,则创建新Hbase表
if (isExist) {
checkTable(sinkTable, sinkColumns, sinkPk, sinkExtend);
}
}
}
}
/**
* 通过Phoenix创建Hbase表
*
* @param tableName 表名
* @param columns 列属性
* @param pk 主键
* @param extend 扩展字段
*/
private void checkTable(String tableName, String columns, String pk, String extend) {
//主键不存在给默认值
if (pk == null) {
pk = "id";
}
//扩展字段给默认值
if (extend == null) {
extend = "";
}
//拼接sql建表语句
StringBuilder createSql = new StringBuilder("create table if not exists " + GmallConfig.HBASE_SCHEMA + "." + tableName + "(");
//拼接列属性
String[] fieldArr = columns.split(",");
for (int i = 0; i < fieldArr.length; i++) {
String field = fieldArr[i];
//判断是否为主键
if (field.equals(pk)) {
createSql.append(field).append(" varchar primary key ");
} else {
createSql.append("info.").append(field).append(" varchar");
}
//非最后一个字段需要添加逗号
if (i < fieldArr.length - 1) {
createSql.append(",");
}
}
createSql.append(")");
createSql.append(extend);
System.out.println("建表sql:" + createSql);
//通过Phoenix创建hbase表
PreparedStatement ps = null;
try {
ps = connection.prepareStatement(createSql.toString());
ps.execute();
} catch (SQLException throwables) {
throwables.printStackTrace();
throw new RuntimeException("建表失败!!!!!" + tableName);
} finally {
if (ps != null) {
try {
ps.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
}
}
/**
* 筛选配置表中保留的字段
*
* @param data 每行数据记录
* @param sinkColumns 配置表保留字段
*/
private void filterColumn(JSONObject data, String sinkColumns) {
//需要保留的字段
String[] columns = sinkColumns.split(",");
//数组转集合,判断集合中是否包含某个元素
List<String> columnList = Arrays.asList(columns);
//获取json中封装的键值对,每个键值对封装为一个Entry类型
Set<Map.Entry<String, Object>> entrySet = data.entrySet();
/*for (Map.Entry<String, Object> entry : entrySet) {
if (!columnList.contains(entry.getKey())) {
entrySet.remove();
} 遍历集合删除元素使用迭代器,for循环删除会报错
}*/
Iterator<Map.Entry<String, Object>> iterator = entrySet.iterator();
while (iterator.hasNext()) {
Map.Entry<String, Object> entry = iterator.next();
if (!columnList.contains(entry.getKey())) {
iterator.remove();
}
}
}
}
7)HbaseSink:DimSink.java
import com.alibaba.fastjson.JSONObject;
import com.flink.realtime.common.GmallConfig;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Set;
/**
* @description: TODO Hbase sink 通过Phoenix向Hbase表中写数据
* @author: HaoWu
* @create: 2021年07月30日
*/
public class DimSink extends RichSinkFunction<JSONObject> {
//定义Phoenix连接
Connection connection = null;
@Override
public void open(Configuration parameters) throws Exception {
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
connection = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);
}
/**
* 生成语句提交hbase
*
* @param jsonObj
* @param context
* @throws Exception
*/
@Override
public void invoke(JSONObject jsonObj, Context context) {
String sinkTableName = jsonObj.getString("sink_table");
JSONObject dataObj = jsonObj.getJSONObject("data");
if (dataObj != null && dataObj.size() > 0) {
String upsertSql = genUpdateSql(sinkTableName.toUpperCase(), jsonObj.getJSONObject("data"));
System.out.println(upsertSql);
try {
PreparedStatement ps = connection.prepareStatement(upsertSql);
ps.executeUpdate();
connection.commit();
} catch (SQLException throwables) {
throwables.printStackTrace();
throw new RuntimeException("执行upsert语句失败!!!");
}
}
}
/**
* 生成upsert语句
*
* @param sinkTableName
* @param data
* @return
*/
private String genUpdateSql(String sinkTableName, JSONObject data) {
Set<String> fields = data.keySet();
String upsertSql = "upsert into " + GmallConfig.HBASE_SCHEMA + "." + sinkTableName + " (" + StringUtils.join(fields, ",") + ")";
String valuesSql = " values ('" + StringUtils.join(data.values(), "','") + "')";
return upsertSql + valuesSql;
}
}
8)自定义序列化 kafka sink
/**
* todo kafka sink 自定义序列化,各种类型自定义传输
*
* @return
*/
public static <T> FlinkKafkaProducer<T> getKafkaSinkBySchema(KafkaSerializationSchema<T> kafkaSerializationSchema) {
Properties props = new Properties();
//kafka地址
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092,hadoop104:9092");
//生产数据超时时间
props.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 15 * 60 * 1000 + "");
return new FlinkKafkaProducer<T>(DEFAULT_TOPIC, kafkaSerializationSchema, props, FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
}
// TODO 7.实时数据保存到Kafka中,自定义序列化
FlinkKafkaProducer<JSONObject> kafkaSink = MyKafkaUtil.getKafkaSinkBySchema(new KafkaSerializationSchema<JSONObject>() {
@Override
public void open(SerializationSchema.InitializationContext context) throws Exception {
System.out.println("kafka序列化");
}
@Override
public ProducerRecord<byte[], byte[]> serialize(JSONObject jsonObject, @Nullable Long aLong) {
String sink_topic = jsonObject.getString("sink_table");
JSONObject data = jsonObject.getJSONObject("data");
return new ProducerRecord<>(sink_topic, data.toString().getBytes());
}
});
3.4 主程序:流程总结分析
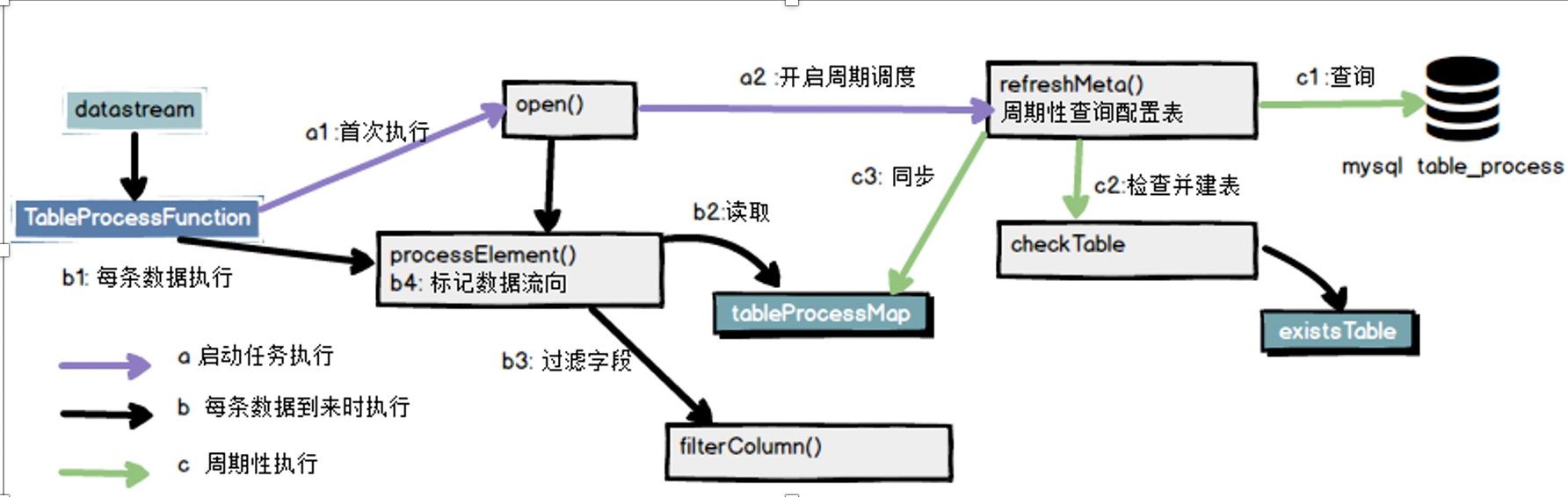
TableProcessFunction是一个自定义算子,主要包括三条时间线任务
-
图中紫线,这个时间线与数据流入无关,只要任务启动就会执行。主要的任务方法是open()这个方法在任务启动时就会执行。他的主要工作就是初始化一些连接,开启周期调度。
-
图中绿线,这个时间线也与数据流入无关,只要周期调度启动,会自动周期性执行。主要的任务是同步配置表(tableProcessMap)。通过在open()方法中加入timer实现。同时还有个附带任务就是如果发现不存在数据表,要根据配置自动创建数据库表。
-
图中黑线,这个时间线就是随着数据的流入持续发生,这部分的任务就是根据同步到内存的tableProcessMap,来为流入的数据进行标识,同时清理掉没用的字段。
3.5 思考
1.目前的配置表只能识别新增的配置项,不支持修改原有的配置项 ?
4.整体流程图分析