

Java HashMap跟LinkedHashMap区别和效率比较,解决字段乱序问题
今天写一个java webservice,用Delphi 调用。发现生成的数据字段是乱序的,一检查,Resultset返回的数据是正常顺序,但在封装成json传送给Delphi时出现了问题,根本原因是因为resultset转JSON时先封装成hashmap集导致(ps:因为是根据客户端传来的SQL语句进行查询并封装JSON,事前并不确定要查的表名,字段名,字段个数等)
Java测试代码如下:
List<Map<String, Object>> data = new ArrayList<Map<String, Object>>(); try { while (rs.next()) { ResultSetMetaData metaData = rs.getMetaData(); int columnCount = metaData.getColumnCount(); // 遍历每一列 //Map<String, Object> map = new HashMap<String, Object>(); //HashMap不能保证插入顺序和读取顺序一致 Map<String, Object> map = new LinkedHashMap<String, Object>(); for (int i = 1; i <= columnCount; i++) { String columnName =metaData.getColumnLabel(i); String value = rs.getString(columnName); map.put(columnName, value); //System.out.println(columnName+ value); } data.add(map); } jsonString = JSON.toJSONString(data); //fastjson --bean to json
而HahsMap是不能保证顺序的(插入顺序和读取顺序不一致)。
所以解决方法是:改用可以保证正确顺序的LinkedHashMap。
总结:
1、LinkedHashMap可以认为是HashMap+LinkedList,即它既使用HashMap操作数据结构,又使用LinkedList维护插入元素的先后顺序。
2、LinkedHashMap的基本实现思想就是----多态。可以说,理解多态,再去理解LinkedHashMap原理会事半功倍;反之也是,对于LinkedHashMap原理的学习,也可以促进和加深对于多态的理解。
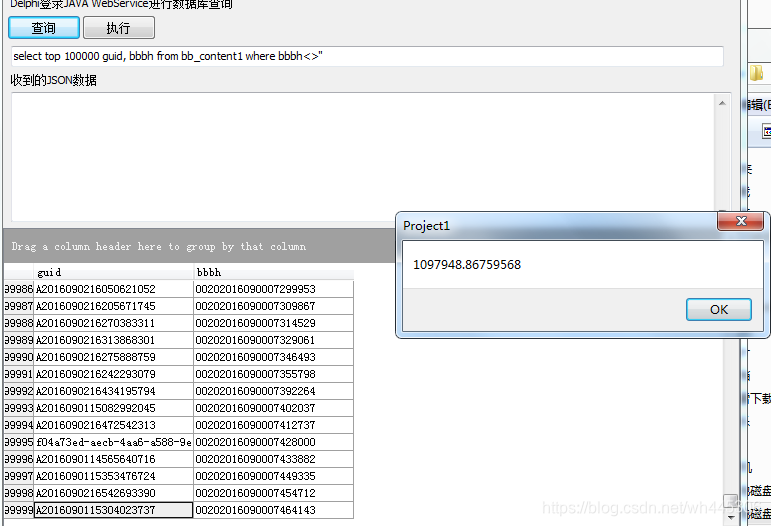
经过实际测试,LinkedHashMap在保证了顺序情况下速度也跟Hashmap几乎无差别。查询结果10万条以内的记录集,封装成map再转json再发送到客户端,Delphi 客户端用SuperObject解析json并显示到Tcxgrid中。多次测试平均耗时都在0.6-1秒左右。(PS:本机测试环境,机械硬盘,无ssd。java webservice 跟Delphi客户端均为本人开发)
Delphi测试代码如下:
procedure TForm1.Button4Click(Sender: TObject); var sjson, sSql: string; Websvr:WebSvrImpl; cds:TClientDataSet; c1:int64; t1,t2:int64; r1:double; begin Websvr:=GetWebSvrImpl(); sSql := sqlText.SelText; if sSql = '' then sSql := sqlText.Text; sjson := Websvr.OpenSQL(sSql); if sjson = '' then begin ShowMessage('执行数据失败。'); Exit; end else // memJson.Text:=sjson; // QryCom.LoadFromFile('Source.xml'); //如果是xml可以直接用ADOQuery载入解析 QueryPerformanceFrequency(c1);//WINDOWS API 返回计数频率(Intel86:1193180)(获得系统的高性能频率计数器在一毫秒内的震动次数) QueryPerformanceCounter(t1);//WINDOWS API 获取开始计数值 //sleep(50);{do...}//执行要计时的代码 cds:=TClientDataSet.Create(nil); //JsonToClientDataSet(memJson.Text,cds,''); JsonToClientDataSet(sjson,cds,''); ds.DataSet := cds; //QryCom.DataSource:=ds; MainView.ClearItems; MainView.DataController.CreateAllItems(); QryComAfterOpen(ds.DataSet); QueryPerformanceCounter(t2);//获取结束计数值 r1:=(t2-t1)/c1;//取得计时时间,单位秒(s) r1:=(t2-t1)/c1*1000;//取得计时时间,单位毫秒(ms) r1:=(t2-t1)/c1*1000000;//取得计时时间,单位微秒 showmessage(floattostr(r1)); end;
关于linkedHashMap,这篇文章介绍的很详细,有兴趣的可以去看看
本文来自博客园,作者:IT情深,转载请注明原文链接:https://www.cnblogs.com/wh445306/p/16751927.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?