
Lucene 初步 之 HelloWorld
万恶的源头 HelloWorld
要完成lucene 的配置 需要几个jar包 (如果需要可以留言我私发)
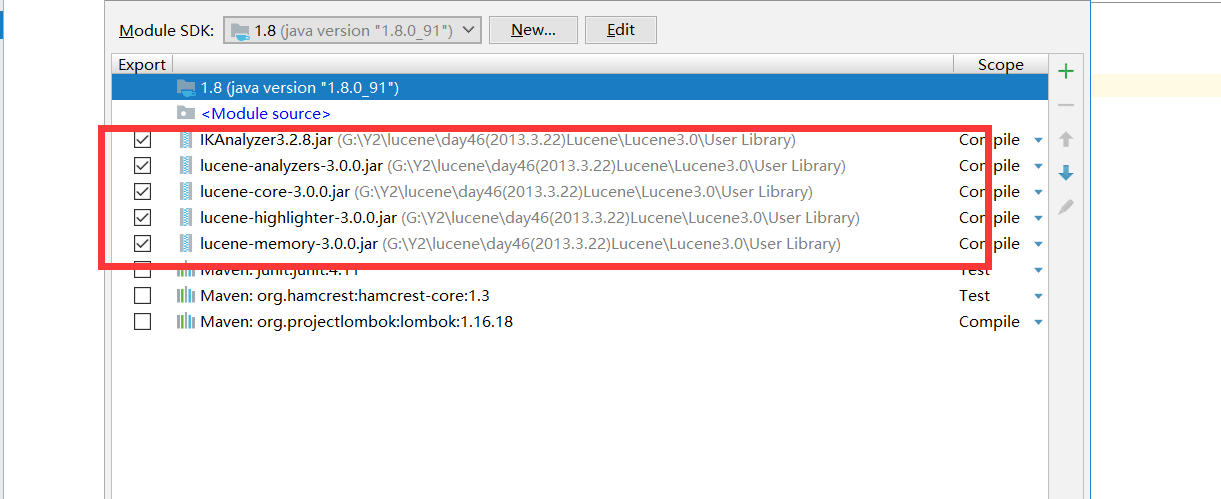
创建索引API分析:
1. Directory: 类代表一个Lucene索引的位置,FSDirectory:它表示一个存储在文件系统中的索引的位置
2. Analyzer 类是一个抽象类, 它有多个实现,在一个文档被入索引库之前,首先需要对文档内容进行分词处理,针对不同的语言和应用需要选择适合的 Analyzer。Analyzer 把分词后的内容交给 IndexWriter 来建立索引
3. IndexWriter:是创建索引和维护索引的中心组件, 这个类创建一个新的索引并且添加文档到一个已有的索引中。IndexWriter只负责索引库的更新(删、更新、插入),不负责查询
4. Document:由多个字段(Field)组成,一个Field代表与这个文档相关的元数据。如作者、标题、主题等等,分别做为文档的字段索引和存储。add(Fieldable field)添加一个字段(Field)到Document
Store,Index介绍
|
枚举类型 |
枚举常量 |
说明 |
|
Store |
NO |
不存储属性的值 |
|
YES |
存储属性的值 |
|
|
Index |
NO |
不建立索引 |
|
ANALYZED |
分词后建立索引 |
|
|
NOT_ANALYZED |
不分词,把整个内容作为一个词建立索引 |
说明:Store是影响搜索出的结果中是否有指定属性的原始内容。Index是影响是否可以从这个属性中查询(No),或是查询时可以查其中的某些词(ANALYZED),还是要把整个内容作为一个词进行查询(NOT_ANALYZED)。
搜索原理图分析:
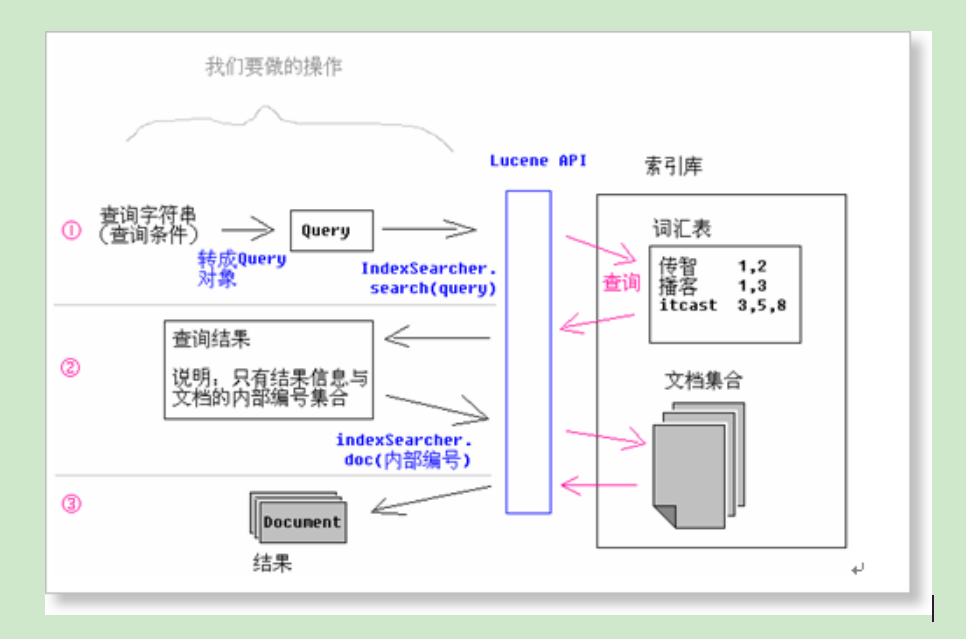
这时我们假设 把商品添加到索引库
1 public void saveGoods(Goods goods) { 2 //创建一个indexWrite 3 IndexWriter indexWriter = null; 4 //指定索引库的目录 5 Directory directory = null; 6 //创建一个分词器 7 Analyzer analyzer = null; 8 9 10 try { 11 //不同分词器,分词的效果不同 12 analyzer = new StandardAnalyzer(Version.LUCENE_30); 13 //目录可以任意指定,最好和项目同级目录 14 directory= FSDirectory.open(new File("./indexData")); 15 //通过分词器和索引创建indexWrite 16 indexWriter=new IndexWriter(directory,analyzer, IndexWriter.MaxFieldLength.LIMITED); 17 //把Goods 转化成lucene可以识别的doument 18 Document doc=new Document(); 19 //Goods 对象中的,每个属性,转化lucene 中的字段 20 doc.add(new Field("gid",goods.getGid().toString(), Store.YES,Index.NOT_ANALYZED)); 21 doc.add(new Field("gname",goods.getGname(), Store.YES,Index.ANALYZED)); 22 doc.add(new Field("gprice",goods.getGprice().toString(), Store.YES,Index.NOT_ANALYZED)); 23 doc.add(new Field("gremark",goods.getGremark(), Store.YES,Index.ANALYZED)); 24 //把document添加到索引库 25 indexWriter.addDocument(doc); 26 //提交 27 indexWriter.commit(); 28 } catch (IOException e) { 29 e.printStackTrace(); 30 throw new RuntimeException(e); 31 }finally { 32 try { 33 indexWriter.close(); 34 } catch (IOException e) { 35 e.printStackTrace(); 36 } 37 } 38 }
商品的实体类
1 package cn.wh; 2 3 import lombok.AllArgsConstructor; 4 import lombok.Data; 5 import lombok.NoArgsConstructor; 6 import lombok.experimental.Accessors; 7 8 //有参构造函数 9 @AllArgsConstructor 10 //无参构造函数 11 @NoArgsConstructor 12 //封装 13 @Data 14 //链式风格访问 15 @Accessors(chain = true) 16 public class Goods implements java.io.Serializable { 17 // Fields 18 private Integer gid; 19 private String gname; 20 private Double gprice; 21 private String gremark; 22 23 }
这时我们执行会产生一个索引的库
这时我们再创建一个查询的方式 (根据商品名查询)
1 public List<Goods> query(String gname){ 2 List<Goods> goodsList=new ArrayList<Goods>(); 3 // 创建查询工具类 4 IndexSearcher indexSearcher=null; 5 // 指定Lucenen索引库目录 6 Directory directory=null; 7 // 创建一个分词器 8 Analyzer analyzer=null; 9 try { 10 // 指定查询的目录 11 directory=FSDirectory.open(new File("./indexData")); 12 // 指定查询的分词器: 钓鱼岛中国的---> 钓鱼 钓鱼岛 中国 13 analyzer=new StandardAnalyzer(Version.LUCENE_30); 14 // QueryParser:查询解析器,用来解析查询的字符串,和分词 15 /* 16 * Version.LUCENE_30:版本号 17 * gname: 要查询的 字段名 Term:key,后面可以到多个字段中查找 18 * analyzer:指定对关键字的分词器 19 * */ 20 QueryParser parse=new QueryParser(Version.LUCENE_30,"gname",analyzer); 21 // 解析要查询的关键字:返回的是Query类型 22 Query query=parse.parse(gname); 23 indexSearcher=new IndexSearcher(directory); 24 // indexSearch做查询操作: n 用户期望查询结果数,后面做分页使用 25 TopDocs topDocs=indexSearcher.search(query,10); 26 /* 27 * TopDocs: 28 * totalHits: 实际查询到的结果数 29 * scoreDocs[]: 存储了所有符合条件的document 编号 30 * */ 31 System.out.println("实际的结果数为:" + topDocs.totalHits); 32 // 存储的是document在lucenen中的逻辑编号 33 ScoreDoc[] docs=topDocs.scoreDocs; //[0]=0 [1]=1 34 /* 35 * ScoreDoc: 36 * doc: 文档逻辑编号 37 * score: 当前文档得分 38 * 39 * */ 40 for(int i=0;i<docs.length;i++){ 41 System.out.println("文档的编号:" + docs[i].doc); 42 System.out.println("此文档的得分:" + docs[i].score); 43 // 通过文档的编号获取真正的文档 44 Document doc=indexSearcher.doc(docs[i].doc); 45 // 把Document类型转化我们自己识别的类型 46 Goods goods=new Goods(); 47 goods.setGid(Integer.parseInt(doc.get("gid"))); 48 goods.setGname(doc.get("gname")); 49 goods.setGprice(Double.parseDouble(doc.get("gprice"))); 50 goods.setGremark(doc.get("gremark")); 51 goodsList.add(goods); 52 } 53 } catch (Exception e) { 54 e.printStackTrace(); 55 throw new RuntimeException(e); 56 } 57 return goodsList; 58 59 }
最后测试
可以根据hello 查询出来东西

这时 lucence 提供了一个jar 包 这个jar包是可以看见索引文件中的元素模样
在cmd 输入 java -jar XXXX jar包的名 (如果要这个jar 包 可以留言 我私法)
打开一个客户端 这时 在path中输入索引文件夹的位置
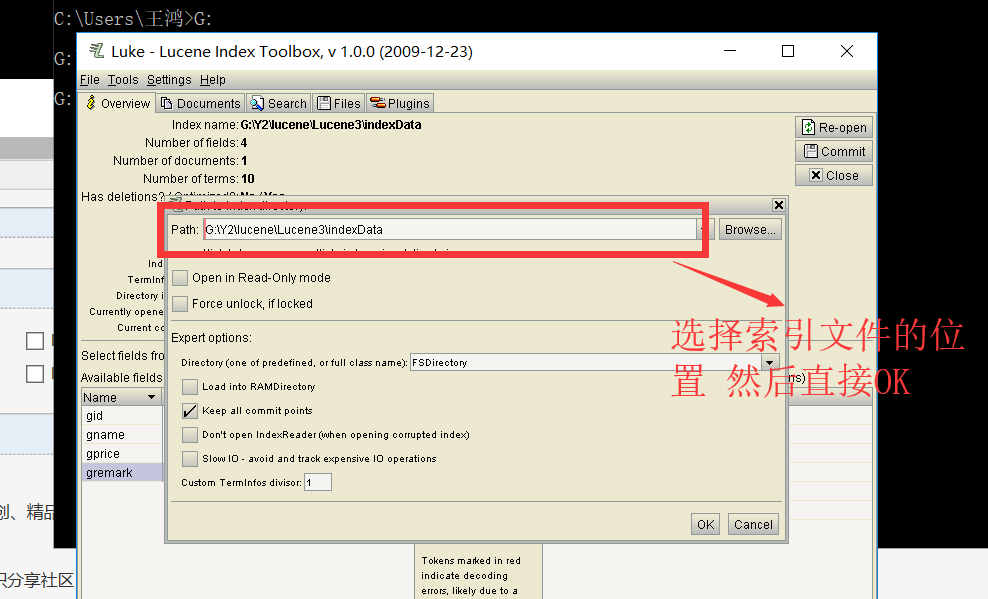
就能看见每个分词的效果就大小和索引

