
HashMap和HashTable
一、时间不同
HashTable是JDK1.0出现的,HashMap是JDK1.2版本后出现的。
二·API不同
两者都是通过哈希表来实现键值映射,但是具体的接口和父类不一样
HashTable和HashMap都实现了Map、cloneable、serializable接口,但是HashTable继承自抽象类Dictionary,HashMap继承自抽象类AbstractMap。
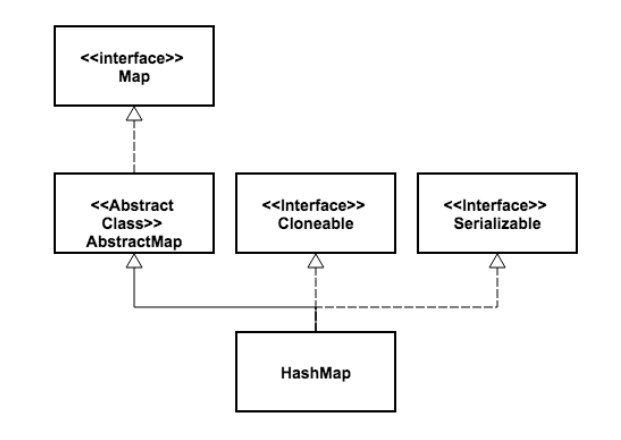

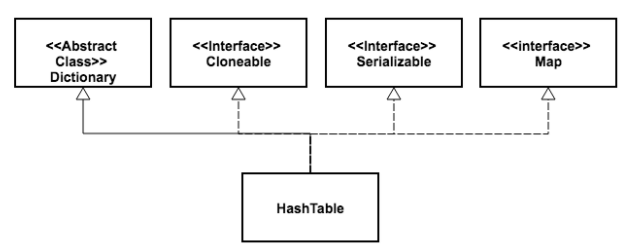
HashMap把HashTable中的 contains方法去掉了,变成了containsKey和containsValue。
三、null key 和 null value
HashTable不允许存放null,如果遇到后会抛出空指针异常。HashMap允许存放null键和NULL值。原因如下:
当key值为空时,会把数据存储在索引为0的buket中,也就是把将空的hashcode值定位了0.在查询的时候,也直接去索引为0的链表中查询。
四、扩容机制
首先知道,在什么时候进行扩容?当size>initialCapacity*loaderFactoyr时调用resize()进行扩容。HashTable默认初始大小为11,加载因子为0.75,每次扩容是2n+1。HashMap的默认初始值为16,加载因子也是0.75,每次扩容2n。但是如果你初始化的时候指定了大小,那么HashTable就会使用你指定的数值,而HashMap会将其扩充为2的幂次方大小。
对于HashMap有两个重要的参数,initialCapacity(初始化容量)和loaderFactory(加载因子)。这两个参数决定着HashMap的效率。如果需要存放的数据过多,散列桶已经存满,再继续放入数据,在不改变initialCapacity的前提下,只能增加链表的长度,那么如果链表过长,就会是get、put效率变得很低(jdk1.8之后,当链表长度大于8时,采用红黑树进行存储),接近线性时间复杂度。但是如果加大initialCapacity,扩容效率就会增加,因为扩容是对数据再散列。因此在使用HashMap时,要考虑好初始化的大小。
五、散列方式
hashTable对hash值对length取模(除留余数法),用到了除法,效率会比较低。hashMap采用了位运算,h&(length-1),h为key的哈希值。


六、线程问题
HashTable的线程是安全的,因为对其中的方法都进行了synchronized操作。
HashMap是线程不安全的,具体体现在:如果两个线程同时进行put操作,而且这两个值得hash(key)是一样的,也就是会放到散列桶的同一个位置,那么就会发生数据覆盖。再比如,多个线程同时发现数组该扩容了,就会同时对他进行扩容,都要进行数据的复制和再散列。最终只有一个线程的数值会赋值给HashMap,其他线程上的数据就会丢失。
那么HashMap能不能实现线程安全呢?HashMap可以通过Collections.synchronizMap(hashMap)来实现线程安全,不过效率也不是很高;或者JDK1.5之后直接使用ConcurrentHashMap.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号