
7.逻辑回归实践
1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
怎么防止过拟合:
(1)增加样本量,适用任何模型。
(2)使用正则化:L1、L2正则化
(3)特征选择,检查选取的特征,将一些不重要的特征去除降低模型复杂度;
(4)逐步回归
(4)进行离散化处理,所有特征都离散化
为什么正则化可以防止过拟合:
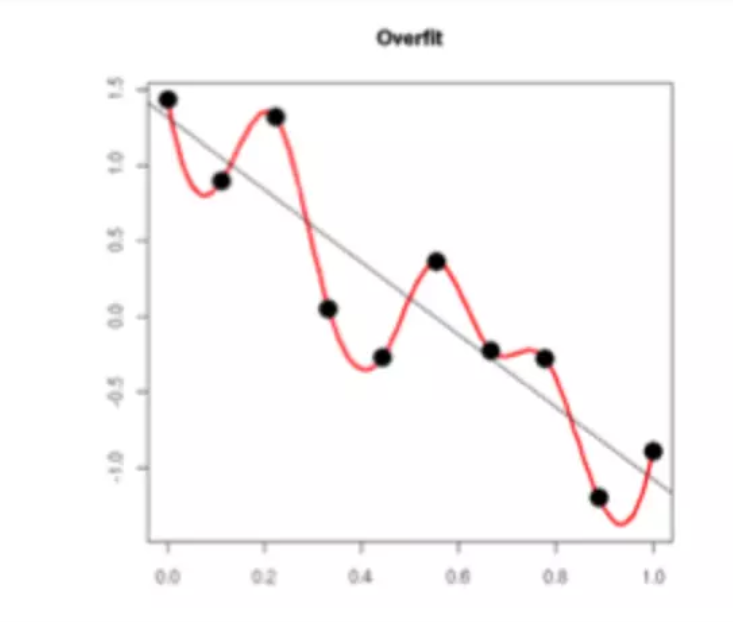
过拟合的时候,拟合函数的系数往往非常大,如下图所示,过拟合,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。而正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况。
2.用logiftic回归来进行实践操作,数据不限。
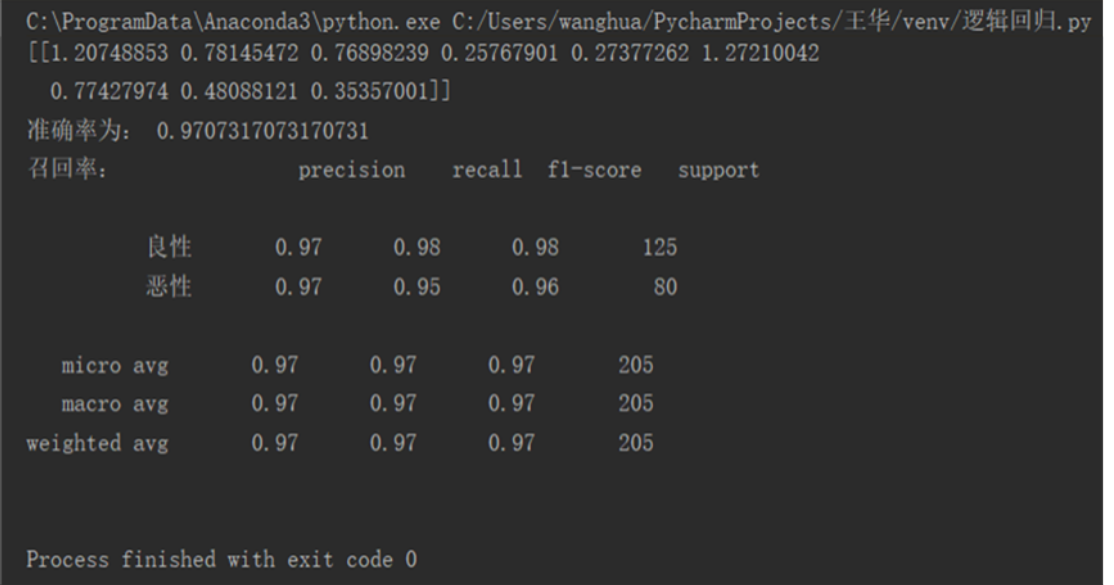
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression from sklearn.metrics import classification_report def logistic(): #加载数据集 names = ['Sample code number',' Clump Thickness','Uniformity of Cell Size','Uniformity of Cell Shape', 'Marginal Adhesion','Single Epithelial Cell Size','Bare Nuclei','Bland Chromatin', 'Normal Nucleoli','Mitoses','Class'] data = pd.read_csv('breast-cancer-wisconsin.csv',names=names) # 缺失值处理 data = data.replace(to_replace='?', value=np.nan) data = data.dropna() X = data.iloc[:, 1:10] y = data.iloc[:, 10] # 数据分割 x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.30) # 数据标准化处理 std = StandardScaler() x_train = std.fit_transform(x_train) x_test = std.fit_transform(x_test) # 逻辑回归 lr = LogisticRegression(C=1.0) lr.fit(x_train, y_train) print(lr.coef_) y_predict = lr.predict(x_test) # 输出准确率 print("准确率为:", lr.score(x_test, y_test)) # 输出召回率 print("召回率:", classification_report(y_test, y_predict, labels=[2, 4], target_names=["良性", "恶性"])) # print(x_train) if __name__ == "__main__": logistic()
结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号