


记录一次11表关联查询的SQL优化
一、优化背景
接收的历史项目有一个存储过程,查询涉及 11张表。
单个存储过程在线上查询一次耗时时间较长。
获取该存储过程在无压力的测试库单独执行,最好的情况,执行单次需要耗时 314.758 秒。
二、优化过程
2.1、原存储过程语句
查询最优时,用时 314秒。
{ 原存储过程:略 }
单独查看原语句, 得到信息, 查询结果列 56列, 查询表涉及 11张表
它的执行过程:
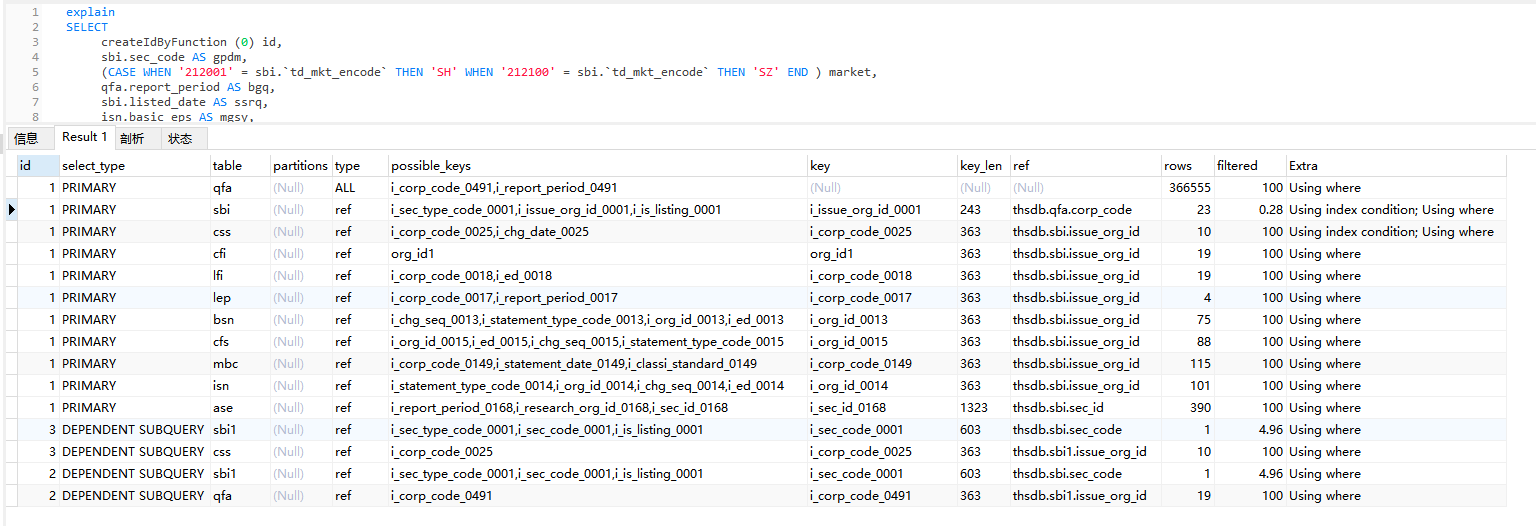
可以看到 qfa 表执行了全量的查询, 检索行为 366555 行。
2.2、对原语句进行分析
共涉及11张表
列出这11张表的数据信息
|
表名 |
记录数 |
数据容量(MB) |
索引容量(MB) |
|
sbi |
2421923 |
922.96 |
1206.51 |
|
qfa |
342002 |
168.85 |
30 |
|
cfi |
421621 |
84.67 |
21.57 |
|
lfi |
374034 |
71.65 |
48.67 |
|
lep |
20205 |
30.57 |
4.54 |
|
bsn |
1678903 |
1246 |
461.32 |
|
cfs |
1695558 |
1220 |
530.1 |
|
mbc |
1751621 |
222.89 |
366.65 |
|
isn |
1984947 |
1142 |
613.26 |
|
ase |
2844362 |
456 |
453.32 |
|
css |
208406 |
47.62 |
22.09 |
2.3、分析sql 关联表 和 查询字段
{ sql :略 }
分析sql 以 sbi 为主表,其他10张表都是 left join 关联查询,
对 sbi 表进行分析,并不是 sbi 中所有数据都会用到。
有查询条件 sec_type_code IN ('001001', '001002') and sbi1.is_listing = 1 的限制。
2.4、提取子查询
{ sql :略 }
这一步就将查询时间压缩在 70秒左右。
查看它的执行过程:

这时查询的大表变成 sbi , 查询数据量 15082 ,
2.5、子查询 + 表排序(正/倒序)
查询的表按照大小进行排序,小表查询靠前,大表查询靠后。
倒叙方式也尝试了 大表查询靠前,小表查询靠后。
使用排序方式,比无序方式有少量的效率提升。
两种方式的查询,没有明显的效率差异。
2.6、子查询 + 表排序(正序) + inner 查询
将当前的 left join 替换为 inner join 查询。
这种方式替换后,发现 inner join 比 left join 查询得到的数据量少,此方法废弃。
2.7、最终确定sql
因为发现当前查询数据量受限于 sbi 表,数据量就在5100左右,删除了之前存储过程中的 limit 0, 10000;
这个sql 在开发库查询,效率最好是 64秒
{ sql :略 }
它的执行过程:

查询的表不变,查询过程也没有变, 这里跟上个的区别就是调整了表查询时的顺序, 按照表数据量从小到大关联的查询。 查询效率有微量的提升。
三、第二阶段, 查询拆分
3.1、 将sql 拆分为多条sql
这个要求时是sql查询压缩在 60秒内,减少数据库压力。
3.1.1、第一组
sbi + css
{ sql :略 }
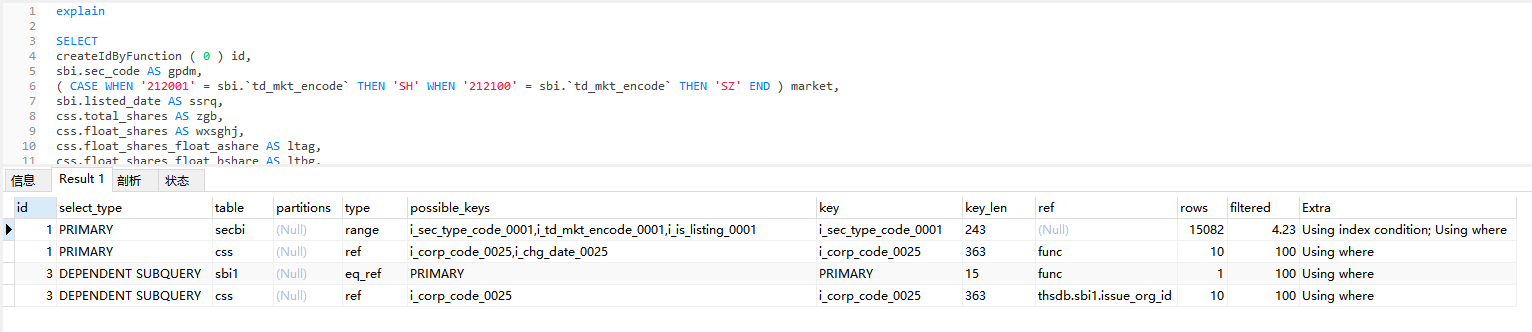
sql执行最快, 16秒, 可以执行完,主信息。
它的执行过程:
3.1.2、第二组
sbi + qfa + lep + lfi + cfi + bsn
{ sql :略 }
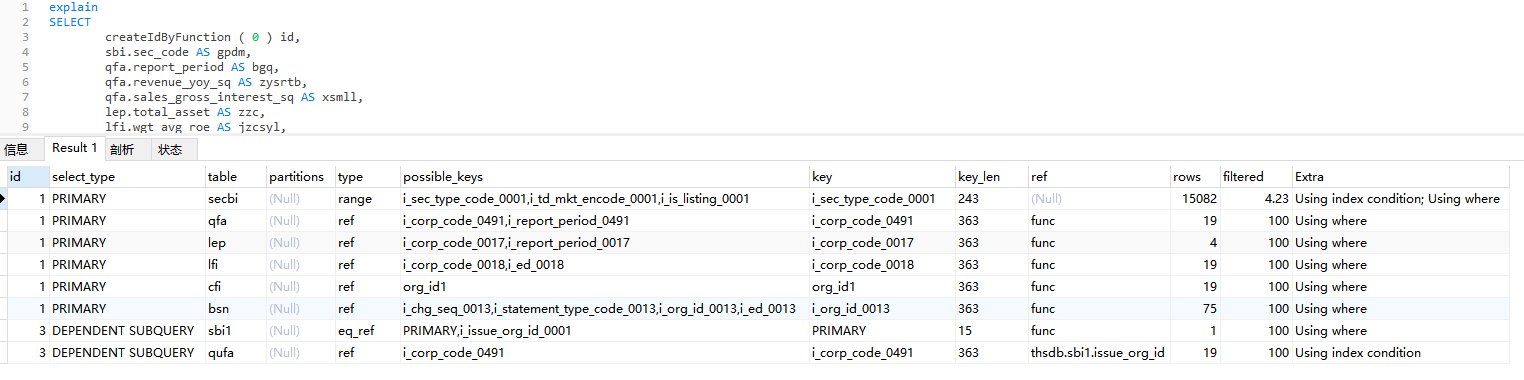
这个查询中, sbi 为主表, 但是所有关联表都需要关联 qfa 表的 report_period 数据,
执行效率约 35秒
它的执行过程
3.1.3、第三组
sbi + qfa + cfs + mbc + isn
{ sql :略 }
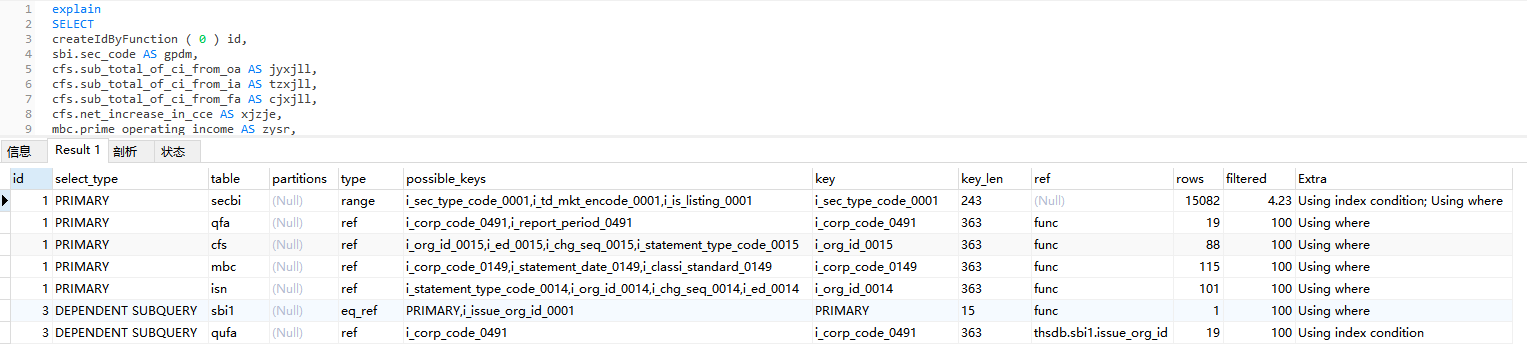
这个查询中, sbi 为主表, 但是所有关联表都需要关联 qfa 表的 report_period 数据,
执行效率约 38秒
它的执行过程:
3.1.4、第四组
sbi + qfs + ase
{ sql :略 }
这个查询中, sbi 为主表,需要关联 qfa 表的 report_period 数据,
执行效率约 37秒
第二组、第三组、第四组 sql 关联性相似, 由于合并到一起 关联 9张表, 执行时间较长, 所以在此对sql进行了拆分。
单独 第四组,只多关联了 ase 情况下,就需要约37秒的时间, 所以对第二组和第三组关联表进行多次调试后,将查询时间平均到 约 37秒左右的查询效果,
它的执行过程:

3.2、代码逻辑合并数据值
代码逻辑上,将四个sql得到四个List集合做合并,
得到最终通一条sql查询出的效果。
四、扩展
4.1、explain 参数含义
|
类型 |
说明 |
值 |
|
id |
列 |
简单子查询 |
|
select_type |
select 的类型 |
SIMPLE:简单查询,不包含子查询 和 union |
|
table |
输出结果集的表 |
{展示的别名} |
|
parititions |
||
|
type |
表的链接类型 |
性能逐渐降低 |
|
possible_keys |
查询时可能用到的索引 |
{可用索引} |
|
key |
实际使用的索引 |
如果没用到索引, 值为 NULL |
|
key_len |
索引字段长度 |
计算: |
|
ref |
key列索引中, |
例: |
|
rows |
估计要读取并检测的行数 |
|
|
filtered |
||
|
Extra |
执行情况的说明 |
Using index :查询的列被索引覆盖,where筛选条件是索引的前导列(最左索引),一般是用到覆盖索引。 |

