


关于核酸架构思考后感
看到一个推文,
原文地址:
起因是 成都核算系统崩溃。
一位架构想象,作为核酸系统的架构师,的理解。
看完文章,学习到的
1、明确系统边界。
架构师首先明确系统边界,
熟悉项目流程 1 2 3 4 5 等
2、崩溃疑云
这个是对已有项目出现问题点的分析和排查方向。根据已有的信息,锁定问题可能出现的点位。
可能的问题 1、 可能的问题 2 等
3、应用层涉及
项目是否属于高并发应用,这个对数据做个估算。
人口估算,2000W+ 人,6小时内做核酸,每秒 tps 约 1000。假设高峰期时平均并发 2 - 3 倍。则 tps 为 2000 ~ 3000.
核酸点估算,1.5W+ 核酸点, 医护扫码间隔 10s - 15s之间,设每个核酸点两排队伍,并发核酸登记 tps 2000 ~ 3000
-- 估算得到系统请求并发度不高。
每日数据量,每天 1200W,假定每天 1000W, 一周 7000W, 一个月 3亿数据量
-- 大数据量 势必要使用分库分表。
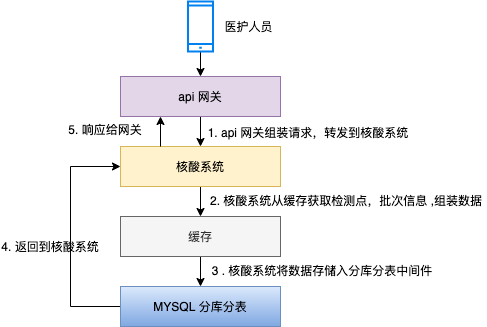
【第一次设计架构,使用分库分表 硬挡高流量访问。这里架构,用到api网关、核酸系统、缓存、分库分表中间件(这里模块用来单独做数据存储功能) 】
第一次分析后,还要考虑核酸等级需要同步给健康码服务。
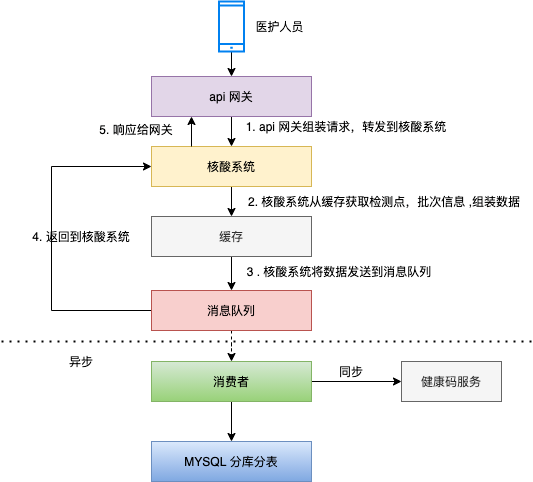
【第二次设计架构,加入了 消息队列MQ,异步和解耦,还可以起到消峰作用。
这里有一句提醒:架构设计中,不是引入组件就完事了,更需要考虑如何精准使用组件,
例:使用消息队列kafka,如何保证不丢消息,保证高可用。
例:使用分库分表中间件,是否需要数据异构,冷热分离 等 】
4、监控平台
研发的双眼,监控平台 + 日志平台
监控平台
4.1、基础运维监控
负责监控服务器的 CPU、网络、磁盘、负载、网络流量、TCP连接等指标,通过设定报警阈值,实时通知指定负责人。
4.2、应用系统监控
研发接触最多的一种监控类型。系统出现瓶颈时候,应用系统监控有最直观的体现。
| 监控 | 备注 |
|
性能监控 (性能调优重点关注对象) |
不同时段性能分布,实时统计 TP99、TP999、AVG、MAX 等维度指标。 |
| 方法调用次数监控 | 按照机器、时间段分析接口或者方法的调用次数,当大流量来袭,可以清晰看到请求波动。 |
|
方法可用性监控 (系统出现严重问题时,重要参考指标) |
接口被调用或方法被执行,可能返回异常或者方法执行抛异常,分析该方法是否调用正常。 |
|
JVM监控 (特别关注对象) |
重点关注 堆内存、GC频率、线程数 等。 |
4.3、业务监控
对业务数据、业务功能进行监控,根据设置的策略对业务流程中不符合预期部分进行预警和报警。
并对收集到业务监控数据进行集中统一的存储和各种方式进行展示。
例:订单系统中的定时结算服务,每两分钟执行一次,可以在定时JOB中添加埋点,配置业务监控,如果十分钟该定时任务未执行,则发送邮件、短信给相关负责人。
5、多方协作
多厂商协同作战,需要顶层统筹强压,让厂商多沟通协调,联合测验。
【性能测试 非常重要,通过压测可以知道系统的极限值,系统承受不住访问时,就会暴露出瓶颈,如服务器 CPU、数据库、内存、相应速度等。从而促使研发团队进行再优化。】
6、总结 (这个总结非常好)
假如我是核酸架构师
6.1、我会使用 消息队列 + 分库分表 来最大程度提升系统的吞吐量。
6.2、我会在使用 消息队列中间件的时候,重点关注如何不会丢失消息,消息系统如何做到高可用。
6.3、我会在使用 分库分表中间件的时候,重点关注 冷热分离,如何向数据异构到数据库仓库。
6.4、我会在部署监控系统,提供 基础运维监控、应用系统监控、业务监控 的能力,当系统出现问题时,团队可以以最快的速度发现问题,并解决问题。
后感 :
几个重点知识点原理还要再深入学习下。
1、消息队列,如何保证不丢消息,保证高可用。
这里消息队列 有 kafka、 RocketMq、RabbitMq 每种的实现方式都需要再整理对比下,加深记忆。
2、数据库的 数据异构,冷热分离
这里常用的是Mysql、最近几年用Oracle 比较少, 如果需要用Oracle 实现, 就需要对比下跟mysql 的区别。再换PostgreSql ,将会如何实施。 具体过程要操作一两次。
3、实时统计 TP99、TP999、AVG、MAX 等维度指标 这几个参数如果不依靠已存在的UPM监控,自己实现的话需要如何实现?


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
2021-11-05 CountDownLatch 和 CyclicBarrier