【算法一】布隆过滤器算法学习附维基百科详细说明PDF文件
示例一 来源:https://www.cnblogs.com/yueyue184/p/10037587.html
/// <summary> /// 布隆过滤器 /// </summary> public class BloomFilter { public BitArray _bloomArray; /// <summary> /// 布隆数组的大小 /// </summary> public Int64 BloomArrayLength { get; set; } /// <summary> /// 数据长度 /// </summary> public Int64 DataArrayLength { get; set; } /// <summary> /// hash数 /// </summary> public Int64 BitIndexCount { get; set; } /// <summary> /// 布隆过滤器初始化 /// </summary> /// <param name="bloomArrayLength">布隆数组的大小</param> /// <param name="dataArrayLength">数据长度</param> /// <param name="bitIndexCount">hash数</param> public BloomFilter(int bloomArrayLength, int dataArrayLength, int bitIndexCount) { _bloomArray = new BitArray(bloomArrayLength); this.BloomArrayLength = bloomArrayLength; this.DataArrayLength = dataArrayLength; this.BitIndexCount = bitIndexCount; } /// <summary> /// 添加 /// </summary> /// <param name="str"></param> public void Add(string str) { var hashCode=str.GetHashCode(); var random = new Random(hashCode); for (int i = 0; i < BitIndexCount; i++) { var c=random.Next((int)this.BloomArrayLength - 1); _bloomArray[c] = true; } } /// <summary> /// 判断是否存在 /// </summary> /// <param name="str">字符串</param> /// <returns></returns> public bool IsExists(string str) { var hashCode = str.GetHashCode(); var random = new Random(hashCode); for (int i = 0; i < BitIndexCount; i++) { if (!_bloomArray[random.Next((int)this.BloomArrayLength-1)]) { return false; } } return true; } /// <summary> /// 获取错误概率 /// </summary> /// <returns></returns> public double GetFalsePositiveProbability() { // (1 - e^(-k * n / m)) ^ k return Math.Pow((1 - Math.Exp(-BitIndexCount * (double)DataArrayLength / BloomArrayLength)), BitIndexCount); } }
class Program { static void Main(string[] args) { //五千万条数据 var bloomFilter = new BloomFilter(200000000, 50000000, 3); //添加5千万个数做测试 for (int i = 0; i < bloomFilter.DataArrayLength; i++) { bloomFilter.Add(i.ToString()); } do { var str = Console.ReadLine(); var stopwatch = new Stopwatch(); stopwatch.Start(); var temp = bloomFilter.IsExists(str); stopwatch.Stop(); Console.WriteLine($"查找:{str}\n结果:{temp}\n总耗时:{stopwatch.ElapsedTicks}\n错误概率:{bloomFilter.GetFalsePositiveProbability()}"); } while (true); } }
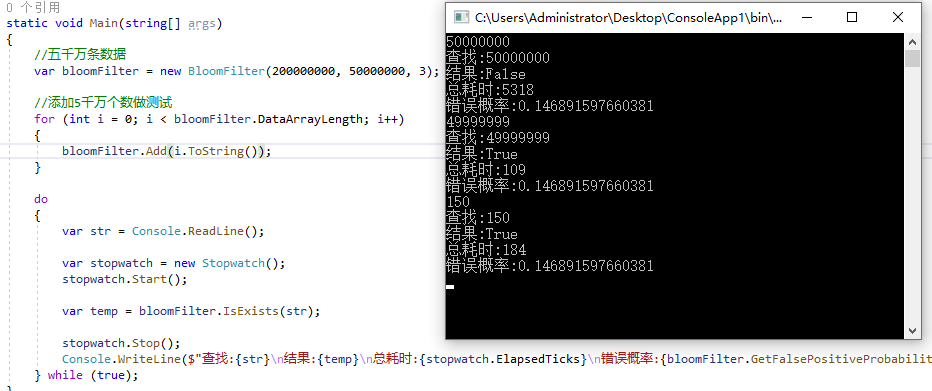
大数据量的查找结果及错误概率:
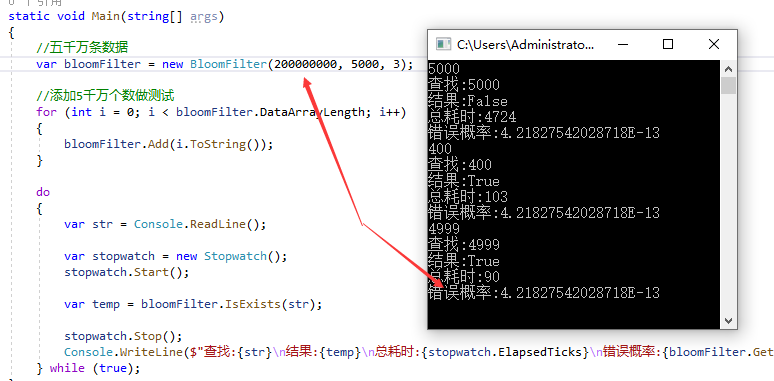
内存占用情况:

小数据量下的查找结果及错误概率:

布隆数组很大,但是数据长度很小的情况下错误概率就会很大,所以两者之间有相关关系,并且查找都很快。
Bloom filter是Bloom在1970年提出的二进制向量数据结构
可控制性
根据其数组长度m、集合大小n、hash函数个数k、误判率p,简单得出下:
- 其他不变,集合大小n越大,越多位被设置1,误判率p越大。
- 其他不变,数组涨肚m越大,剩余为0的位越多,误判率p越小
- 其他不变,添加时k越多,位数组越多被设置为1,即会增大误判率。查询时k越多,明显误判率可能就会越小。
hash函数个数取值公式 k = ln 2 * m/n 。
通常应用在一些大数据下需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合。
例如:
爬虫过程中的重复URL检测。
缓存命中率,垃圾邮件过滤。
内存挡一层,减轻db空查压力。
黑名单验证。
优点在于:
- 插入和查询复杂度都是O(n)
- 空间利用率极高。
算法步骤:
- 创建长度为m的位数组,全部置为0。
- 取出邮件地址集合(m)中的某一个地址(a), 分别使用k个hash函数对a计算。
- 将结果分别映射到位数组中,并设置为1。
- 其他成员依次处理。
其他参考:https://www.cnblogs.com/heaad/archive/2011/01/02/1924195.html
布隆算法维基百科中文说明PDF文件:
作者:江宁织造
博客:http://www.cnblogs.com/wgx0428/
博客:http://www.cnblogs.com/wgx0428/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号