

2-机器学习-KNN近邻算法分类模型、交叉验证
总结
K近邻法的工作原理:某个未知类型点的特征数据距离K个已有类型近邻点特征数据的距离,根据这个距离对未知类型的数据进行分类
- KNN模型超参数K值:K值不同会导致分类结果的不同
- 距离:采用欧几里得公式求得距离
- 适用范围:KNN适用于样本量级不够大得项目,因为它得运算成本比较高,数据量级越大,建模会耗时越长
KNN分类模型
- 分类:将一个未知归类的样本归属到某一个已知的类群中
- 预测:可以根据数据的规律计算出一个未知的数据
- 概念:
- 简单地说,K-近邻算法采用测量不同特征值之间的距离方法进行分类(k-Nearest Neighbor,KNN)
A(x1,y1) # 点A B(x2,y2) # 点B # A点到B点的距离 dist(A,B) = ((x1-x2)**2 + (y1-y2)**2)**0.5

- k值的作用

- 欧几里得距离(Euclidean Distance)

如何进行电影分类
众所周知,电影可以按照题材分类,然而题材本身是如何定义的?由谁来判定某部电影属于哪 个题材?也就是说同一题材的电影具有哪些公共特征?这些都是在进行电影分类时必须要考虑的问 题。没有哪个电影人会说自己制作的电影和以前的某部电影类似,但我们确实知道每部电影在风格 上的确有可能会和同题材的电影相近。那么动作片具有哪些共有特征,使得动作片之间非常类似, 而与爱情片存在着明显的差别呢?动作片中也会存在接吻镜头,爱情片中也会存在打斗场景,我们 不能单纯依靠是否存在打斗或者亲吻来判断影片的类型。但是爱情片中的亲吻镜头更多,动作片中 的打斗场景也更频繁,基于此类场景在某部电影中出现的次数可以用来进行电影分类。
工作原理
存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据 与所属分类的对应关系。输人没有标签的新数据后,将新数据的每个特征与样本集中数据对应的 特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们 只选择样本数据集中前K个最相似的数据,这就是K-近邻算法中K的出处,通常K是不大于20的整数。 最后,选择K个最相似数据中出现次数最多的分类,作为新数据的分类。
回到前面电影分类的例子,使用K-近邻算法分类爱情片和动作片。有人曾经统计过很多电影的打斗镜头和接吻镜头,下图显示了6部电影的打斗和接吻次数。假如有一部未看过的电影,如何确定它是爱情片还是动作片呢?我们可以使用K-近邻算法来解决这个问题。

首先我们需要知道这个未知电影存在多少个打斗镜头和接吻镜头,上图中问号位置是该未知电影出现的镜头数图形化展示,具体数字参见下表。

即使不知道未知电影属于哪种类型,我们也可以通过某种方法计算出来。首先计算未知电影与样本集中其他电影的距离,如图所示。

现在我们得到了样本集中所有电影与未知电影的距离,按照距离递增排序,可以找到K个距 离最近的电影。假定k=3,则三个最靠近的电影依次是California Man、He's Not Really into Dudes、Beautiful Woman。K-近邻算法按照距离最近的三部电影的类型,决定未知电影的类型,而这三部电影全是爱情片,因此我们判定未知电影是爱情片。
# 根据?这个点得特征数据求它到其他电影类型特征数据得距离 import pandas as pd df = pd.read_excel('./datasets/my_films.xlsx') df.head()
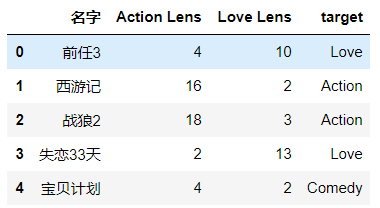
feature = df[['Action Lens','Love Lens']] # 特征数据 target = df['target'] # 标签数据 from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier(n_neighbors=3) # n_neighbors就是K值,默认为5 knn.fit(feature,target) # 这里模型就训练好了 # 使用模型做分类 knn.predict([[18,90]]) # 需要传一个二维数据 array(['Love'], dtype=object)
在scikit-learn库中使用k-近邻算法
- 分类问题:from sklearn.neighbors import KNeighborsClassifier
- 模型的超参数
- 如果模型类中的相关参数的不同,会导致分类或者回归效果的不同,则这些参数叫做模型的超参数。
鸢尾花分类的实现
from sklearn.neighbors import KNeighborsClassifier import pandas as pd import sklearn.datasets as datasets from sklearn.model_selection import train_test_split # 1.捕获鸢尾花数据 iris = datasets.load_iris() # 2.提取样本数据 feature = iris.data # 特征数据 target = iris.target # 标签数据 feature.shape # (150, 4) target.shape # (150,) # 3.数据集进行拆分 x_train,x_test,y_train,y_test = train_test_split(feature,target,test_size=0.2,random_state=2020) x_train.shape # (120, 4) # 训练集 特征数据 y_train.shape # (120,) # 训练集 标签数据 x_test.shape # (30, 4) # 测试集 特征数据 y_test.shape # (30,) # 测试集 标签数据 # 4.观察数据集:看是否需要进行特征工程的处理 x_train # 5.实例化模型对象 knn = KNeighborsClassifier(n_neighbors=5) # n_neighbors就是K值,超参数 # 6.使用训练集数据训练模型 # X:特征(特征数据的维度必须是二维(表格型数据)) # y:标签 knn.fit(x_train,y_train) # 训练模型 这里就把模型训练好了 KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, n_neighbors=5, p=2, weights='uniform') # 7.测试模型:使用测试数据 knn.score(x_test,y_test) # 0.9评分 # 8.使用模型进行分类 print('真实的分类结果:',y_test) print('模型的分类结果:',knn.predict(x_test)) # predict就是使用模型为测试数据进行分类 真实的分类结果: [2 0 1 1 1 2 2 1 0 0 2 2 0 2 2 0 1 1 2 0 0 2 1 0 2 1 1 1 0 0] 模型的分类结果: [2 0 1 1 1 1 2 1 0 0 2 1 0 2 2 0 1 1 2 0 0 2 2 0 2 1 1 1 0 0]
预测年收入是否大于50K美元
特征工程使用-one-hot编码-归一化
from sklearn.preprocessing import StandardScaler,MinMaxScaler df = pd.read_csv('./datasets/adults.txt') df.head()
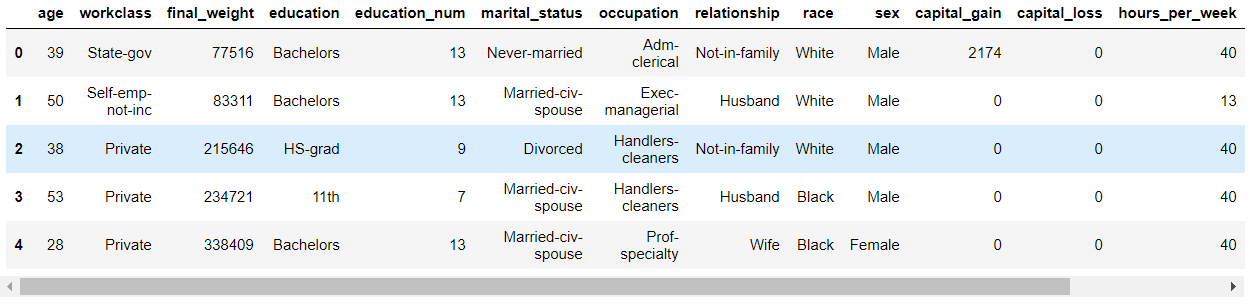
# 1.提取样本数据 feature = df[['age','education_num','occupation','hours_per_week']] target = df['salary'] # 2.特征工程-特征抽取-特征值化 # one-hot编码 one_hot = pd.get_dummies(feature['occupation']) # 级联one-hot表 one_hot_feature = pd.concat((feature[['age','education_num','hours_per_week']],one_hot),axis=1)

# 归一化处理 s = StandardScaler() one_hot_feature = s.fit_transform(one_hot_feature) # 3.切分数据集 x_train,x_test,y_train,y_test = train_test_split(s_feature,target,test_size=0.2,random_state=20) knn = KNeighborsClassifier(30) knn.fit(x_train,y_train) knn.score(x_test,y_test) # 0.7982496545370796
不用one-hot编码形式
#1.提取样本数据 feature = df[['age','education_num','occupation','hours_per_week']] target = df['salary'] # 2.特征工程,使用映射对occupation做特征值化 count = 1 dic = {} # 作为映射关系表 for occ in feature['occupation'].unique().tolist(): dic[occ] = count count += 1 feature['occupation'] = feature['occupation'].map(dic)
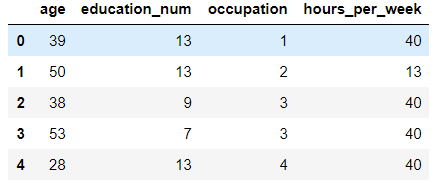
# 3.数据集得切分 x_train,x_test,y_train,y_test = train_test_split(feature,target,test_size=0.2,random_state=20) # 4训练模型,得出评分 knn = KNeighborsClassifier(n_neighbors=18) knn.fit(x_train,y_train) knn.score(x_test,y_test) # 0.7953324120988792
特征工程使用one-hot编码和映射俩者对评分影响差别不大
使用模型对未知数据进行分类
# 使用模型对未知数据进行分类 print('真实分类结果:',y_test[0:10]) print('模型分类结果:',knn.predict(x_test)[0:10]) 真实分类结果: 13376 <=50K 7676 >50K 32188 <=50K 30550 <=50K 18873 >50K 21652 >50K 29911 <=50K 27398 <=50K 5757 >50K 4303 <=50K Name: salary, dtype: object 模型分类结果: ['<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '<=50K' '>50K' '<=50K']
模型分类效果不好的原因
- 1.超参数设置不合理
- 2.样本数据的特征工程没有做好
- 3.模型没有选对,模型不适合这个分类
绘制学习曲线寻找最优的k值
- 穷举不同的k值
k-近邻算法之约会网站配对效果判定(datingTestSet.txt)
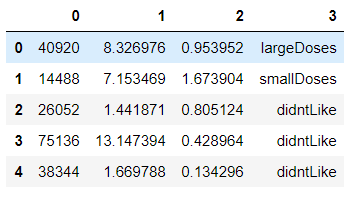
df = pd.read_csv('./datasets/datingTestSet.txt',header=None,sep='\t') df.head() # 0 为男性一年飞行里程数 # 1 为男性吃冰激凌公斤数 # 2 为男性玩游戏消耗时间 # 3 分类结果
# 1.样本提取,如果列比较多的话可以这样做 feature_col = [col for col in df.columns if col !=3] feature = df[feature_col] target = df[3] feature.shape # (1000, 3) target.shape # (1000,) # 2.特征工程,数值大小严重不平衡,必须进行对其进行无量纲化 # 归一化 mm = MinMaxScaler() feature = mm.fit_transform(feature) array([[0.44832535, 0.39805139, 0.56233353], [0.15873259, 0.34195467, 0.98724416], [0.28542943, 0.06892523, 0.47449629], ..., [0.29115949, 0.50910294, 0.51079493], [0.52711097, 0.43665451, 0.4290048 ], [0.47940793, 0.3768091 , 0.78571804]]) # 3.数据级切分 x_train,x_test,y_train,y_test = train_test_split(feature,target,test_size=0.2,random_state=2020) # 4.训练模型 knn = KNeighborsClassifier(n_neighbors=10) knn.fit(x_train,y_train) knn.score(x_test,y_test) # 0.95 # 5.穷举绘制曲线寻找最优K值 ks = [5,7,9,12,15,20,25,30,35,40,45,50,60,70,80,90,100] scores = [] for k in ks: knn = KNeighborsClassifier(n_neighbors=k) knn.fit(x_train,y_train) score = knn.score(x_test,y_test) scores.append(score) # 绘制曲线 import matplotlib.pyplot as plt plt.plot(ks, scores) plt.xlabel('k') plt.ylabel('score')
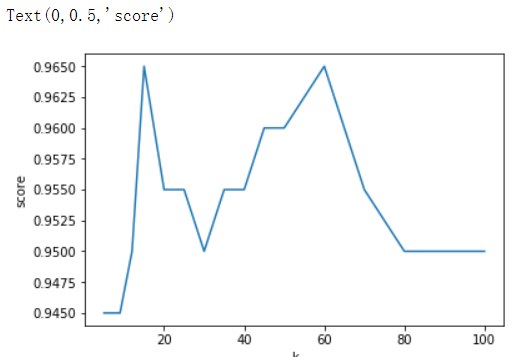
# 寻找最优K值 import numpy as np arr_scores = np.array(scores) np.argmax(arr_scores) # np.argmax可以获取最大值的索引 4 ks[np.argmax(arr_scores)] # 由这个索引取ks列表中获取最高分值所对应的K值 15 # 6.基于最优K值建模 knn = KNeighborsClassifier(n_neighbors=ks[np.argmax(arr_scores)]) knn.fit(x_train,y_train) knn.score(x_test,y_test) # 0.965
问题:约会数据中发现标签数据为非数值型数据,可行吗?
- 可行!因为在knn中样本的标签数据是不需要参与运算。
k的取值问题:学习曲线&交叉验证选取K值
- K值较小,则模型复杂度较高,容易发生过拟合,学习的估计误差会增大,预测结果对近邻的实例点非常敏感。
- K值较大可以减少学习的估计误差,但是学习的近似误差会增大,与输入实例较远的训练实例也会对预测起作用,使预测发生错误,k值增大模型的复杂度会下降。在应用中,k值一般取一个比较小的值,通常采用交叉验证法来来选取最优的K值。
- 适用场景
- 小数据场景,样本为几千,几万的
K折交叉验证
- 目的:
- 选出最为适合的模型超参数的取值,然后将超参数的值作用到模型的创建中。
- 思想:
- 将样本的训练数据交叉的拆分出不同的训练集和验证集,使用交叉拆分出不同的训练集和验证集测分别试模型的精准度,然就求出的精准度的均值就是此次交叉验证的结果。将交叉验证作用到不同的超参数中,选取出精准度最高的超参数作为模型创建的超参数即可!
- 实现思路:
- 将数据集平均分割成K个等份
- 使用1份数据作为测试数据,其余作为训练数据
- 计算测试准确率
- 使用不同的测试集,重复2、3步骤
- 对准确率做平均,作为对未知数据预测准确率的估计

- API
- from sklearn.model_selection import cross_val_score
- cross_val_score(estimator,X,y,cv):
- estimator:模型对象
- X,y:训练集数据
- cv:折数
import matplotlib.pyplot as plt import numpy as np import pandas as pd from sklearn.preprocessing import MinMaxScaler from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import cross_val_score df = pd.read_csv('./datasets/datingTestSet.txt',header=None,sep='\t') df.head() # 1.样本提取,如果列比较多的话可以这样做 feature_col = [col for col in df.columns if col !=3] feature = df[feature_col] target = df[3] # 2.特征工程,数值大小严重不平衡,必须对其进行无量纲化 # 归一化 mm = MinMaxScaler() feature = mm.fit_transform(feature) array([[0.44832535, 0.39805139, 0.56233353], [0.15873259, 0.34195467, 0.98724416], [0.28542943, 0.06892523, 0.47449629], ..., [0.29115949, 0.50910294, 0.51079493], [0.52711097, 0.43665451, 0.4290048 ], [0.47940793, 0.3768091 , 0.78571804]]) # 3.数据级切分 x_train,x_test,y_train,y_test = train_test_split(feature,target,test_size=0.2,random_state=2020) # 4.使用交叉验证&学习曲线找寻最优的超参数 ks = [5,7,9,12,15,20,25,30,35,40,45,50,60,70,80,90,100] scores = [] for k in ks: knn = KNeighborsClassifier(n_neighbors=k) # 参数1模型,参数2训练集的特征数据,参数3训练集的标签数据 ,参数cv将训练集拆分为几个等份 # 将训练集拆分为5个等份,4个用来训练模型,1个用来测模型 # 会得到5个得分,取它的平均分 array([0.9382716 , 0.95031056, 0.96226415, 0.95597484, 0.94339623]) score = cross_val_score(knn,x_train,y_train,cv=5).mean() # 0.9500434768140538 scores.append(score) plt.plot(ks,scores)
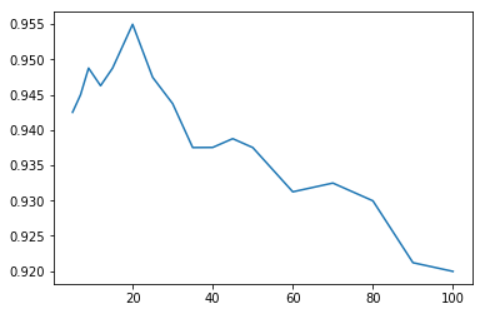
# 定位最优K值 ks[np.argmax(np.array(scores))] # 最高分值对应最优K值为20 # 5.使用最优K值建模 knn = KNeighborsClassifier(n_neighbors=20) knn.fit(x_train,y_train) knn.score(x_test,y_test) # 0.955 # 6.使用模型对数据进行分类 print('真实数据分类:',y_test[:10]) print('使用模型分类:',knn.predict(x_test)[:10]) # 使用模型对数据进行分类 print('真实数据分类:',y_test[:10]) print('使用模型分类:',knn.predict(x_test)[:10]) # 使用模型对数据进行分类 print('真实数据分类:',y_test[:10]) print('使用模型分类:',knn.predict(x_test)[:10]) 真实数据分类: 725 largeDoses 986 smallDoses 815 didntLike 656 smallDoses 469 smallDoses 76 didntLike 668 didntLike 286 largeDoses 904 smallDoses 284 largeDoses Name: 3, dtype: object 使用模型分类: ['largeDoses' 'smallDoses' 'didntLike' 'smallDoses' 'smallDoses' 'didntLike' 'didntLike' 'largeDoses' 'smallDoses' 'largeDoses']
交叉验证也可以帮助我们进行模型选择,以下是一组例子,分别使用iris数据,KNN和logistic回归模型进行模型的比较和选择。
from sklearn.linear_model import LogisticRegression knn = KNeighborsClassifier(n_neighbors=5) print (cross_val_score(knn, x_train, y_train, cv=10).mean()) lr = LogisticRegression() print(cross_val_score(lr,x_train,y_train,cv=10).mean()) 0.9488017134918184 0.8976485798085829
K-Fold&cross_val_score
- Scikit中指供了K-Fold的API
- n-split就是折数
- shuffle指是否对数据洗牌
- random_state为随机种子,固定随机性
from numpy import array from sklearn.model_selection import KFold # data sample data = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6]) kfold = KFold(n_splits=3, shuffle = True, random_state= 1) for train, test in kfold.split(data): print('train: %s, test: %s' % (data[train], data[test])) train: [0.1 0.4 0.5 0.6], test: [0.2 0.3] train: [0.2 0.3 0.4 0.6], test: [0.1 0.5] train: [0.1 0.2 0.3 0.5], test: [0.4 0.6]
Scikit中提取带K-Fold接口的交叉验证接口sklearn.model_selection.cross_validate,但是该接口没有数据shuffle功能,所以一般结合Kfold一起使用。如果Train数据在分组前已经经过了shuffle处理,比如使用train_test_split分组,那就可以直接使用cross_val_score接口
from sklearn.model_selection import cross_val_score from sklearn import datasets iris = datasets.load_iris() X, y = iris.data, iris.target knn = KNeighborsClassifier(n_neighbors=5) n_folds = 5 kf = KFold(n_folds, shuffle=True, random_state=42).get_n_splits(X) # 都样本数据打乱顺序 scores = cross_val_score(knn, X, y, cv = kf) scores.mean() # 0.9733333333333334
