

Iceberg学习日记(1) 定位两个线上Iceberg查不到文件的问题

前言
Iceberg是我们去年年底(2020)开始调研,目前上线了130多张表。主要用于流量日志清洗,数据报表,推荐特征基础数据。至今为也算是积累了一些使用及定位问题经验。 这篇文章会介绍两个线上Iceberg表查不到数据/快照文件的问题,希望对大家有帮助。
一.Rewrite操作有可能会误删数据文件
现象:
如图: 线上一张Iceberg表的合并任务运行一段时间后开始报错找不到数据文件。

当时找到运维查看删文件的用户和机器,定位出来是合并文件程序所在的机器。最后在合并任务日志中发现了这个异常 如图 (当时忘记保存,相同异常的截图冒充的,所以没有图截方法栈)。在BaseRewriteDataFilesAction.java中发现了问题。

原因:
先解释下 CommitStateUnknownException: 在iceberg向hive Metastore提交报错时,Iceberg会重新去Hive Metastore查询一遍刚才有没有提交成功(有可能代理原因hive是提交成功的)。这时如果Iceberg尝试几次向hive查询查ceberg表都报错,这个时候因为没有办法确定提交的的状态是成功还是失败。就会抛 CommitStateUnknownException。
在Rewrite操作提交的异常处理时,因为没有考虑这种 "提交状态不明确的异常",直接将合并过的文件直接删除做"回滚"操作。但是在hive metastore中已经提交成功, 导致下次在查询时 因为新提交的快照引向被删除的元数据文件导致的。
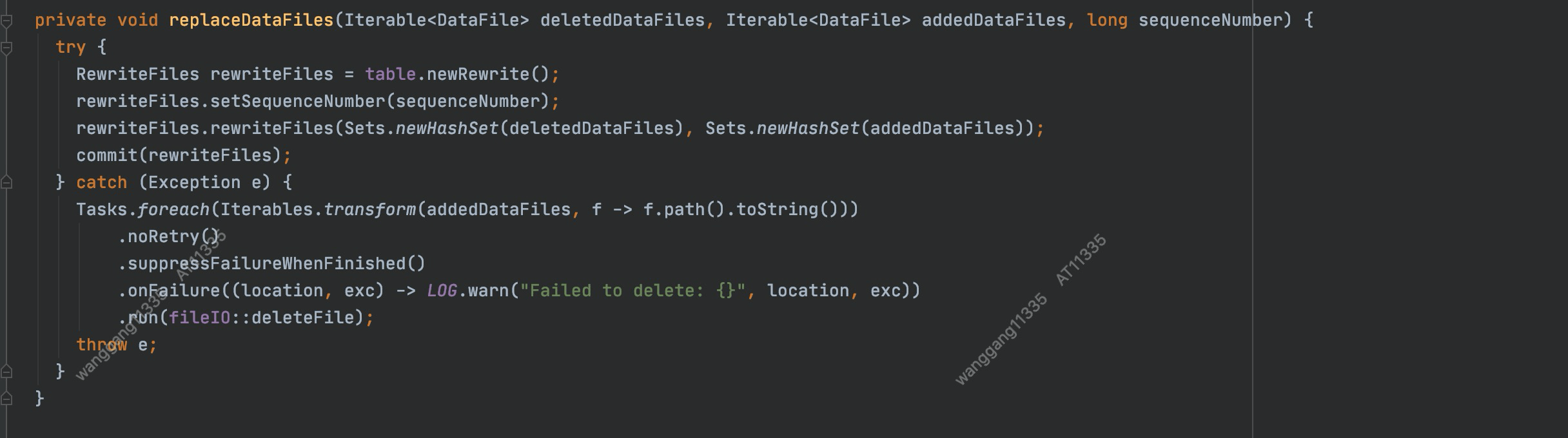
解决办法:
如图,当抛 CommitStateUnknownException异常时不要删这些文件,如果这次提交是提交失败,这些文件会被RemoveOrphanFile操作删掉。
0.12.x之后,spark使用新版本的rewrite api这个问题已经解决了。如果使用iceberg 0.12以前版本的(spark/flink) rewrite action 或者0.12.x的flink rewrite action (目前使用旧的rewrite api)。出现数据文件丢失可以考虑下这种情况。
二.iceberg表快照过期时间过短导致一些查询时间长的查询语句
现象
业务方反映查询iceberg表报快照及manifest文件丢失问题。运维童鞋帮查询是是合并程序删除的(合并程序包含rewrite和expireSnapshot)

排查
发现这个快照的生成时间是上午8点多, 9点多这个快照便被合并程序过期。这个查询程序在开始查询的时候,这个快照是最新的快照。由于查询时间比较长,两个小时后这个查询程序的第n个阶段开始正式读这张表时候发现这个快照文件已经被删了
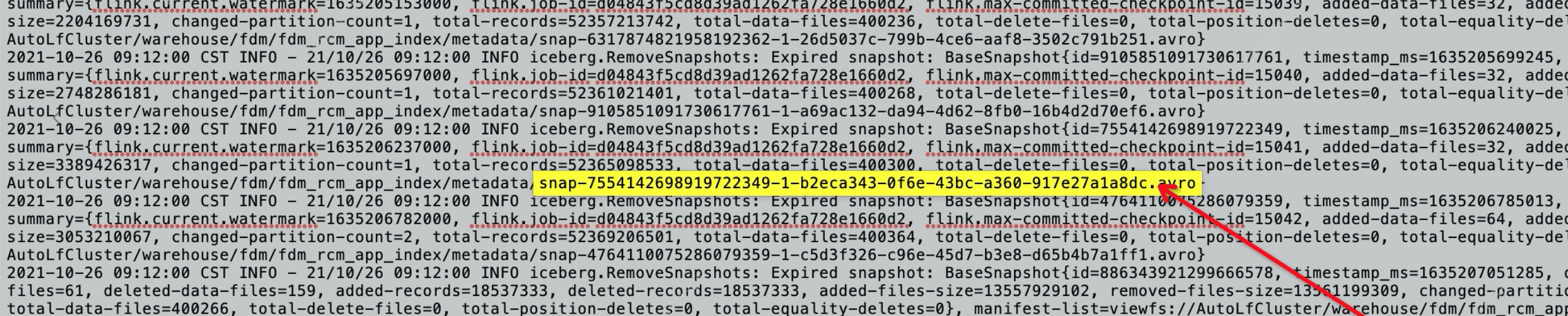
结论
这个问题的原因:这张表的快照过期时间设置得实在太短了。导致稍微耗时的查询就会出现这种问题。调长snapshot过期时间问题就解决了


 浙公网安备 33010602011771号
浙公网安备 33010602011771号