
JVM诊断及工具笔记(5) cpu使用率方面的自助诊断

这篇文章描述了因为进程/单线程cpu瓶颈,导致Flink任务延迟的案例,并且分享了从最开始平台工作人员手动去服务器帮用户诊断,再到如何赋能给用户自助诊断的过程。
-
案例一:是TaskManager进程cpu使用率达到瓶颈的案例 (如果读者生产环境未开启cgroup可以跳过这个案例)
-
案例二:是TaskManager中某些线程的cpu使用率到达瓶颈的案例
现象及解决方案 :
平台上Flink任务延迟,最初我们通过去服务器上使用top + TaskManager的进程id命令,查看TaskManager的CPU使用率是否到达瓶颈。
-
如果到达瓶颈,这个任务可能是cpu密集型的任务,引导用户:
-
增加Flink任务的cpu核数或者并行度
-
通过火焰图之类的工具分析代码是否需要优化
-
查看任务是否fullgc (fullgc会占用很多cpu资源)
-
-
如果未到达瓶颈,这个任务可能是io密集型的任务,引导用户:
-
保持cpu核数不变,增加并行度,观察是否改善
-
自助诊断方案 :
提供用户TaskManager进程的cpu使用率 Metric,方便其自助分析任务是 cpu/io 密集型任务 ,进一步优化代码/任务资源。
具体实现 :
-
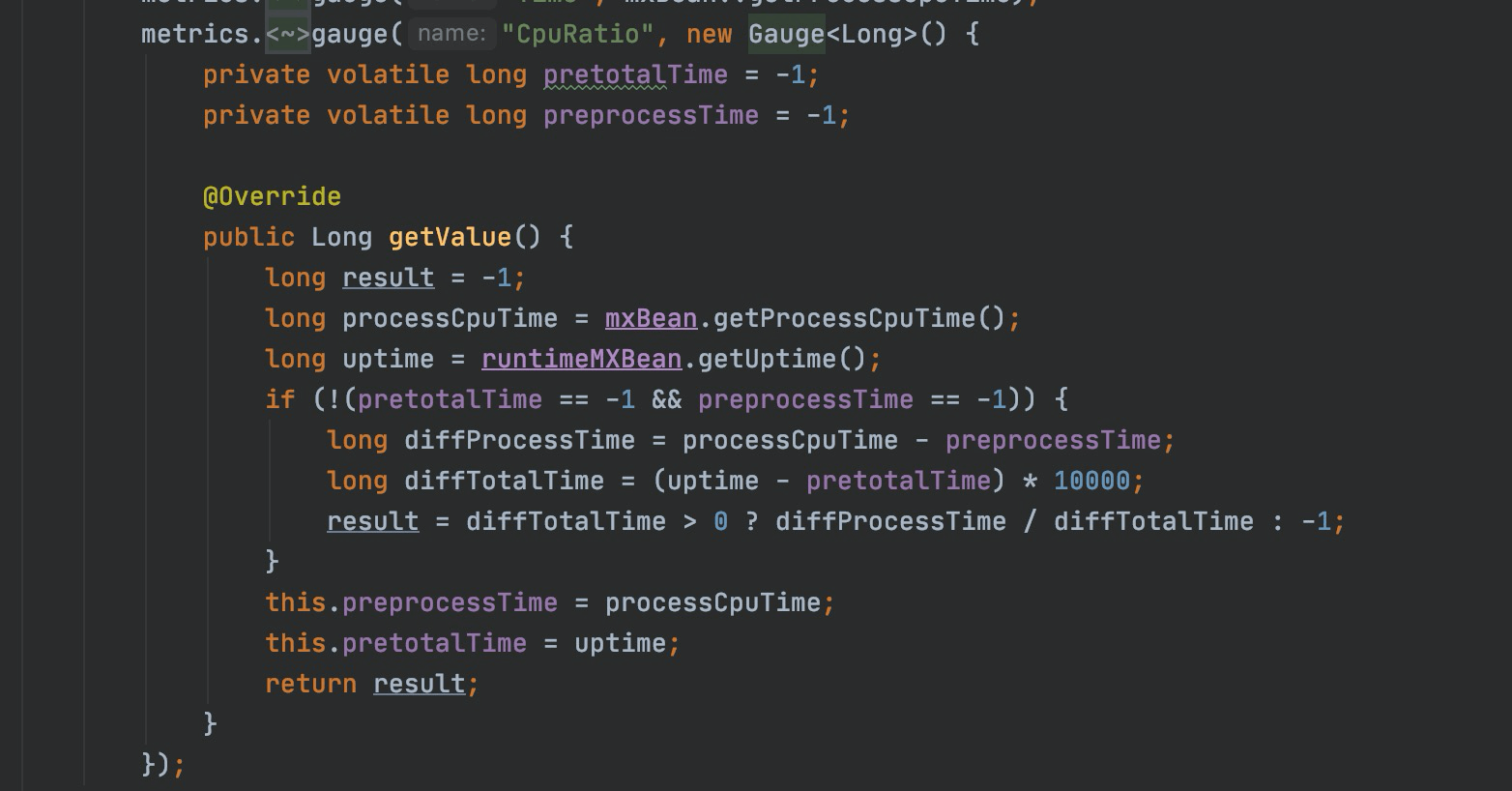
添加cpu使用率metric
方案: 一段时间内的 cpu使用时间/程序运行时间
![image-20220105194535116]()
-
上报cpu核数metric
Flink任务在多核环境运行,所以步骤一上报的cpu使用率metric数值经常都是>100%,需要除以CPU核数才能以0%-100%更加直观地观察cpu使用率。一般情况从Flink配置
yarn.containers.vcores读取cpu核数上报metric即可。
之家这边实现了自动伸缩容功能,TaskManager的cpu核数有可能会有变化。这边的方案是在申请TaskManager Container时,把cpu核数存到TaskManager的环境变量中。TaskManager启动后从环境变量获取cpu核数后上报metric即可。

-
最后配个将步骤1和步骤2的metric相除即可
![image-20220105221315845]()

案例二 :TaskManager 中某个线程cpu使用率瓶颈导致任务延迟
现象
-
top -Hp TaskManager进程号TaskManager进程cpu使用率未耗尽,但是单线程的cpu使用率已到瓶颈。
![image-20220105222100229]()
-
printf '%x\n' 8845获取其线程对应系统的16进制进程号![image-20220105223040990]()
-
jstack -l TaskManager 进程号 |grep 228d定位到这个线程



-
通过火焰图发现消耗cpu的方法是这个udf

解决方案
-
优化udf
-
还可以拆开个线程这行逻辑到多个线程
-
添加并行度
自助诊断方案:
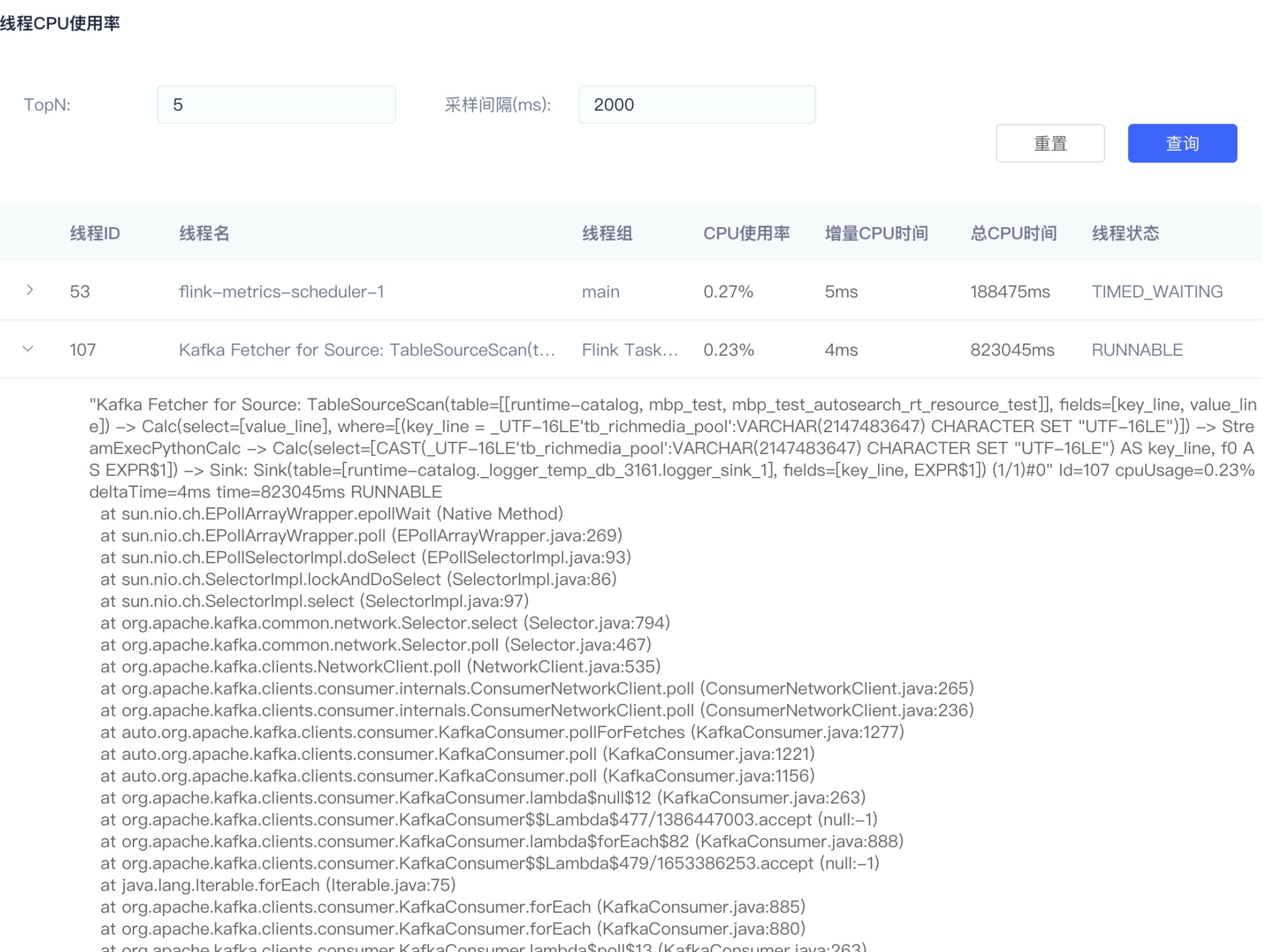
扩展个Flink的rest接口,集成到平台,方便用户可以自助去查询TaskManager进程中cpu占用较高的线程。可以借鉴JVM诊断神器arthas的 thread -n 命令实现
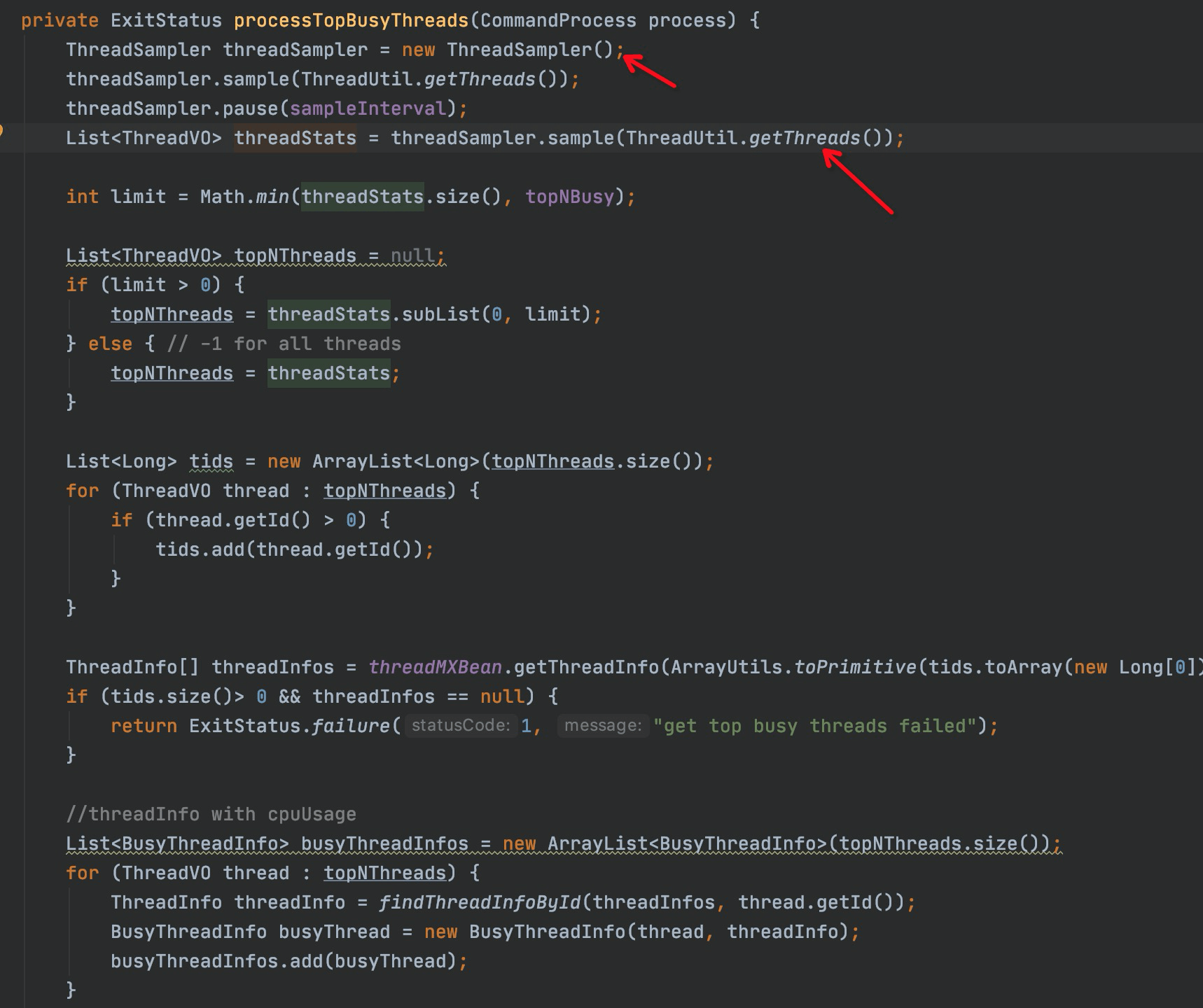
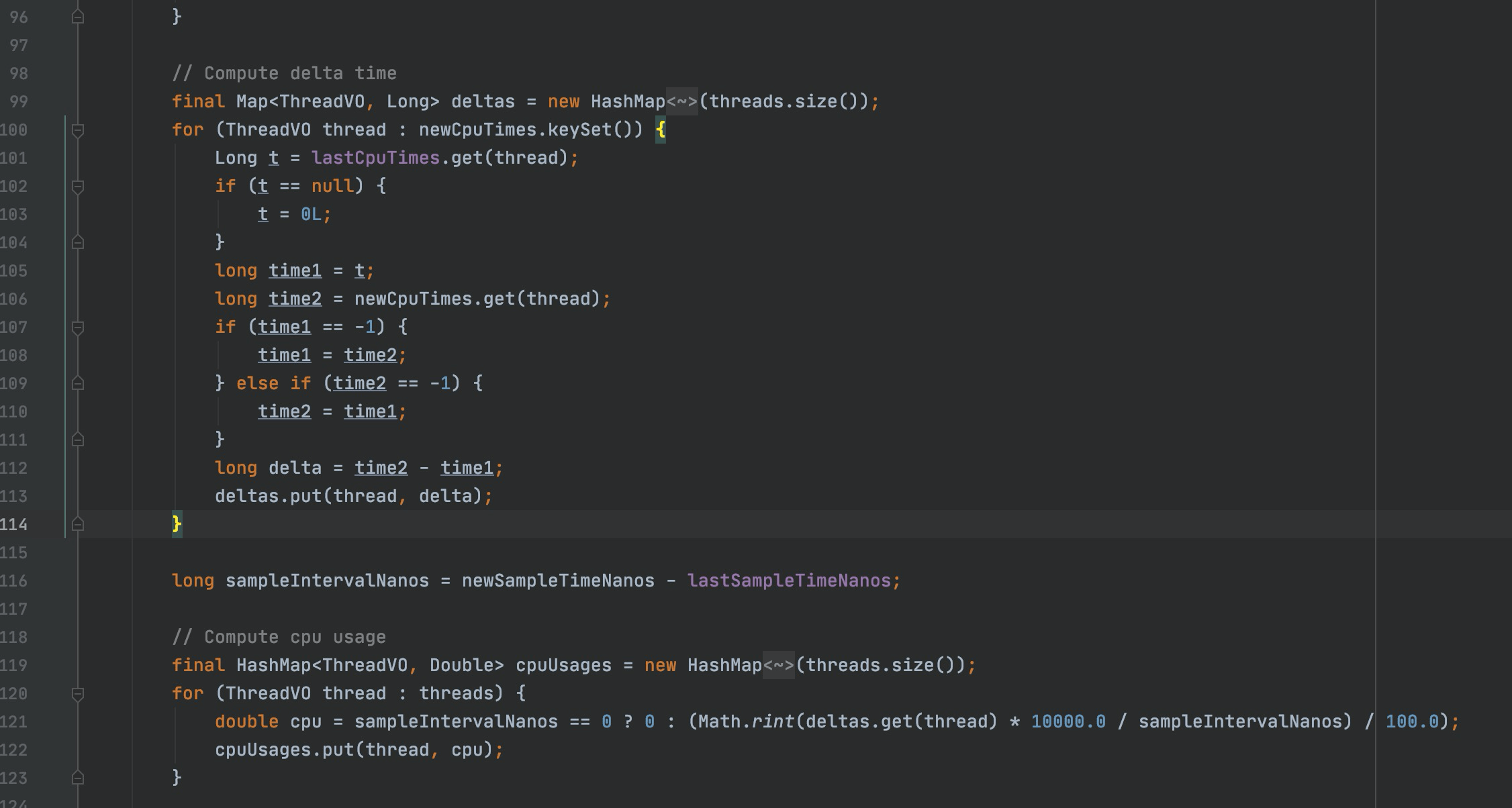
原理: 采样一段时间 JVM每个线程的cpu使用时间 除以 这段JVM程序的运行时间 ,最终再排序 获取top n 。
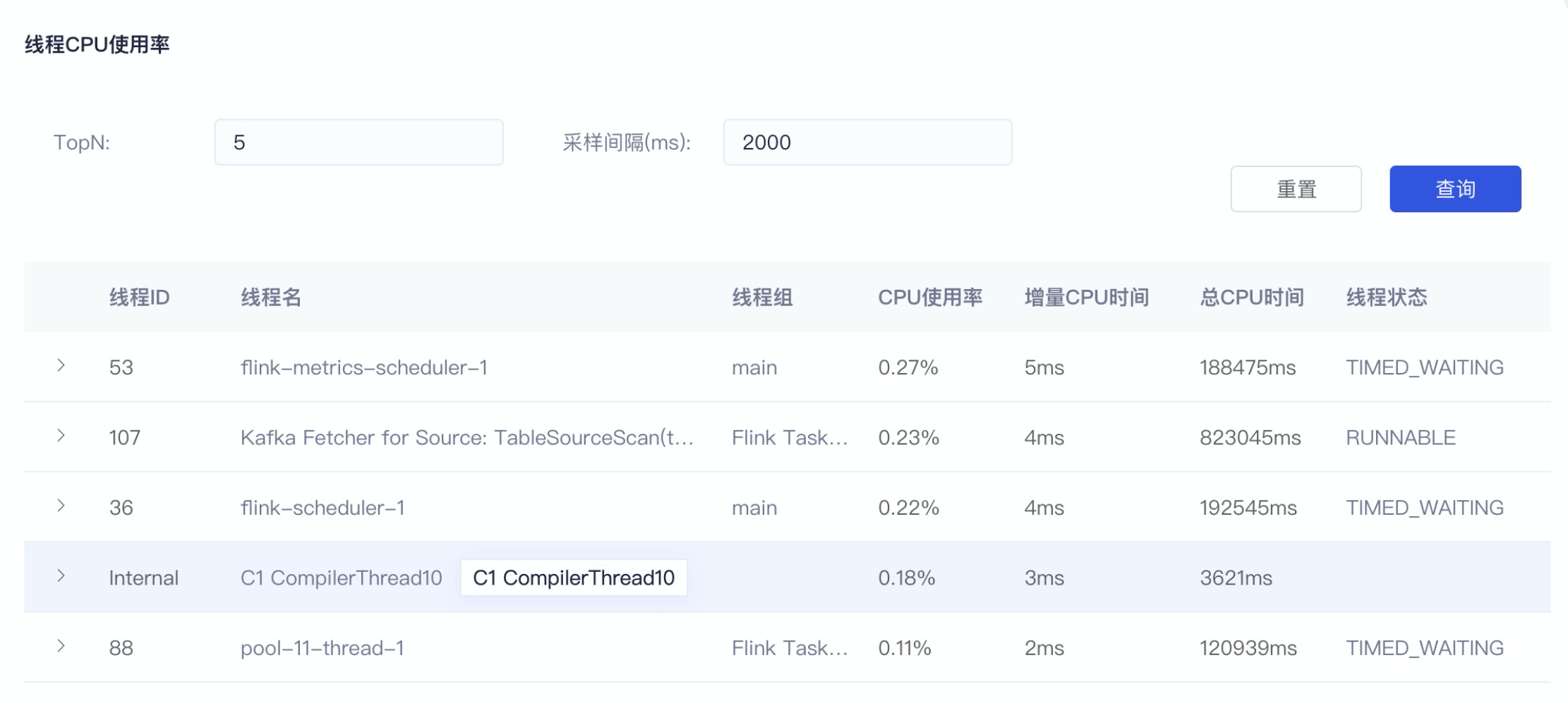
平台上查看 top 5线程使用率及线程栈详情

 浙公网安备 33010602011771号
浙公网安备 33010602011771号