IDEA中使用JDBC访问SQL SERVER(六)缓存结果集数据
https://docs.microsoft.com/zh-cn/sql/connect/jdbc/caching-result-set-data-sample?view=sql-server-ver15
此 Microsoft JDBC Driver for SQL Server 示例应用程序说明了如何从数据库中检索大量数据,然后使用 SQLServerResultSet 对象的 setFetchSize 方法控制在客户端中缓存的数据行数。
备注
限制客户端中缓存的行数与限制结果集中包含的总行数不同。 要控制结果集中包含的总行数,请使用 SQLServerStatement 对象的 setMaxRows 方法,该对象具有继承对象 SQLServerPreparedStatement 和 SQLServerCallableStatement 对象。
要对客户端中缓存的行数进行限制,首先必须在创建 Statement 对象时使用服务器端游标,并且在创建 Statement 对象时专门声明要使用的游标类型。 例如,JDBC 驱动程序提供了 TYPE_SS_SERVER_CURSOR_FORWARD_ONLY 游标类型,该类型是用于 SQL Server 数据库的快速只进、只读的服务器端游标。
备注
如果不使用 SQL Server 的特定游标类型,也可以使用 selectMethod 连接字符串属性,并将其值设置为“cursor”。 有关 JDBC 驱动程序支持的游标类型的详细信息,请参阅了解游标类型。
运行完 Statement 对象中包含的查询且数据已经以结果集的形式返回到客户端后,可以调用 setFetchSize 方法来控制一次可从数据库中检索的数据量。 例如,某表格包含 100 行数据,提取大小设置为 10,则无论何时,客户端中都仅缓存 10 行数据。 尽管这样会降低数据处理速度,但其优势是所占用的客户端内存较少,这在需要处理大量数据时尤为有用。
示例
在下面的示例中,示例代码将建立与 AdventureWorks 示例数据库的连接。 接下来,它会使用带有 SQLServerStatement 对象的 SQL 语句,指定服务器端游标类型,然后运行 SQL 语句并将所返回的数据放入 SQLServerResultSet 对象。
随后,示例代码调用自定义的 timerTest 方法,需要传递的参数为要使用的提取大小和结果集。 timerTest 方法接下来将使用 setFetchSize 方法设置结果集的提取大小,设置测试的起始时间,然后使用 While 循环访问结果集。 While 循环退出后,该代码立即设置测试的停止时间,然后显示测试结果,其中包括提取大小、已处理的行数以及执行该测试所用的时间。
查文档得知与sqlserver jdbc驱动的select Method有关。selectMethod分为direct和cursor。当使用direct时,驱动会一次性载入所有结果集到jvm内存中,因此造成了out of memory;而使用cursor时,会在服务器端创建一个cursor,因此不会占据客户端的大量内存,办法有两种:
[list=1]
修改SQLServer2005 jdbc的URL: jdbc.url=jdbc:sqlserver://127.0.0.1;instanceName=ProductDB;databaseName=product_index; selectMethod=cursor
这种方式会影响整个应用程序,可能引起其他普通情况的读取性能下降。
使用如下代码:
Statement stmt = con.createStatement(SQLServerResultSet.TYPE_SS_SERVER_CURSOR_FORWARD_ONLY,ResultSet.CONCUR_READ_ONLY);
这种方式会造成SQLServer的API侵入,但不失为一种更好的办法。
在Statement和ResultSet接口中都有setFetchSize方法
void setFetchSize(int rows) throws SQLException
查看API文档
Statement接口中是这样解释的:
为 JDBC 驱动程序提供一个提示,它提示此 Statement 生成的 ResultSet 对象需要更多行时应该从数据库获取的行数。指定的行数仅影响使用此语句创建的结果集合。如果指定的值为 0,则忽略该提示。默认值为 0。
ResultSet中是这样解释的:
为 JDBC 驱动程序设置此 ResultSet 对象需要更多行时应该从数据库获取的行数。如果指定的获取大小为零,则 JDBC 驱动程序忽略该值,随意对获取大小作出它自己的最佳猜测。默认值由创建结果集的 Statement 对象设置。获取大小可以在任何时间更改。
网上的摘录:
摘录1:
缺省时,驱动程序一次从查询里获取所有的结果。这样可能对于大的数据集来说是不方便的, 因此JDBC 驱动提供了一个用于设置从一个数据库游标抽取若干行的 ResultSet 的方法。在连接的客户端这边缓冲了一小部分数据行,并且在用尽之后, 则通过重定位游标检索下一个数据行块。
摘录2:
setFetchSize最主要是为了减少网络交互次数设计的。访问ResultSet时,如果它每次只从服务器上取一行数据,则会产生大量的开销。setFetchSize的意思是当调用rs.next时,ResultSet会一次性从服务器上取得多少行数据回来,这样在下次rs.next时,它可以直接从内存中获取出数据而不需要网络交互,提高了效率。 这个设置可能会被某些JDBC驱动忽略的,而且设置过大也会造成内存的上升。
另外在《Best practices to improve performance in JDBC》一文中也提及该方法的使用用于提高查询效率,有名词将之成为batch retrieval
控制器代码:
package com.example.wfydemo.controller; import com.microsoft.sqlserver.jdbc.SQLServerResultSet; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import java.sql.*; import java.util.ArrayList; @RestController public class jdbc_CacheResultSet { @SuppressWarnings("serial") @RequestMapping("/jdbc_CacheResultSet") public String jdbc_CacheResultSet( ) { String connectionUrl = "jdbc:sqlserver://127.0.0.1:1433;databaseName=springbootTestDB;user=sa;password=6617saSA";//sa身份连接 //TYPE_SS_SERVER_CURSOR_FORWARD_ONLY:指定 SQL Server 快速只进只读游标类型 // try (Connection con = DriverManager.getConnection(connectionUrl);) { //游标读取 Statement stmt = con.createStatement(SQLServerResultSet.TYPE_SS_SERVER_CURSOR_FORWARD_ONLY, SQLServerResultSet.CONCUR_READ_ONLY); //默认一次读取,无游标 //Statement stmt = con.createStatement(); insertTable(con); String SQL = "SELECT * FROM T_User;"; for (int n : new ArrayList<Integer>() { { add(1); add(10); add(100); add(1000); add(0); } }) { // Perform a fetch for every nth row in the result set. try (ResultSet rs = stmt.executeQuery(SQL)) { timerTest(n, rs); } } } // Handle any errors that may have occurred. catch (SQLException e) { e.printStackTrace(); } return "jdbc_CacheResultSet"; } private static void timerTest(int fetchSize, ResultSet rs) throws SQLException { // Declare the variables for tracking the row count and elapsed time. int rowCount = 0; long startTime = 0; long stopTime = 0; long runTime = 0; // 设置缓冲区大小,用游标查询才有用 rs.setFetchSize(fetchSize); startTime = System.currentTimeMillis(); while (rs.next()) { rowCount++; } stopTime = System.currentTimeMillis(); runTime = stopTime - startTime; // Display the results of the timer test. System.out.println("FETCH SIZE: " + rs.getFetchSize()); System.out.println("ROWS PROCESSED: " + rowCount); System.out.println("TIME TO EXECUTE: " + runTime); System.out.println(); } //插入2000条记录 private static void insertTable (Connection con) throws SQLException { String sql = "insert into T_User(name,password) values(?,?);"; try (PreparedStatement pstmt = con.prepareStatement(sql)) { for(int i=1;i<2000;i++) { pstmt.setObject(1, "user" + (1000+i)); pstmt.setObject(2, "123456"); pstmt.execute(); } } } }
运行结果:http://localhost:8888/website/jdbc_CacheResultSet
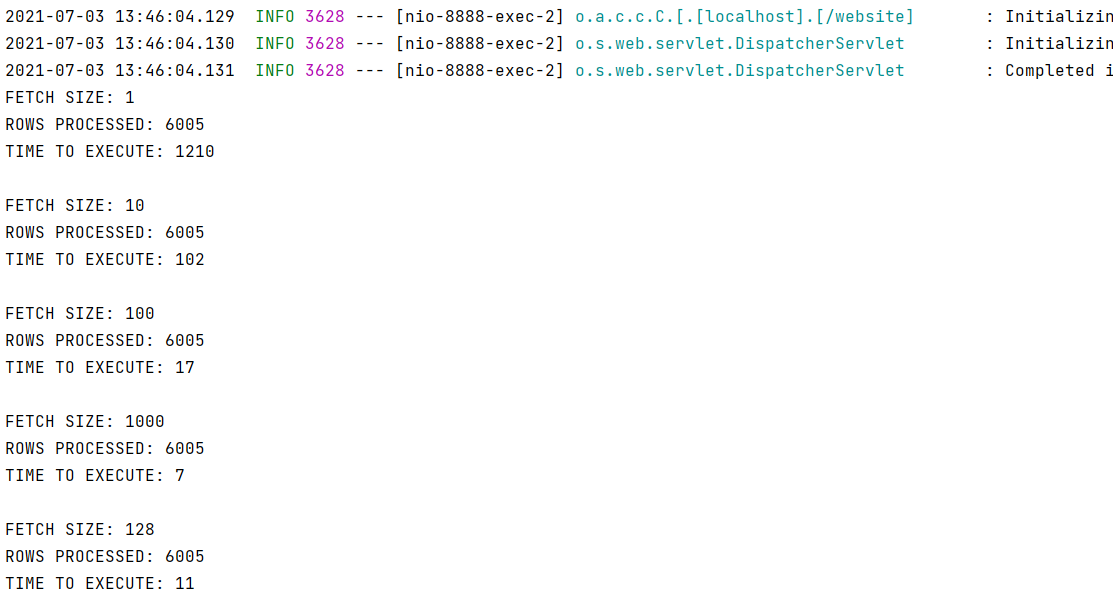
缓冲区大,一次取较多的记录,时间就短。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号