|
匹配任意非十进制数字。在 ecmascript 方式下,等效于 unicode 的 [\p{nd}]、非 unicode 的 [^0-9]。
C#正则表达式编程(一):C#中有关正则的类
正则表达式是一门灵活性非常强的语言,匹配同样的字符串可能在不同的开发人员那里会得到不同的结果,在平常的时候也是用的时候看看相关资料,不用的时候就丢在脑后了,尽管在处理大部分情况下都能迅速处理,但是处理一些复杂的情况效率仍是不高,借着前阵子做过的一个项目涉及到正则表达式的机会,将有关资料阅读了一遍并结合了自己的体会,整理了几篇利用 C# 进行正则表达式编程的文章,一来加深自己的印象和理解,二来供博客上的读者学习借鉴。
在 .NET 中提供了对正则表达式的支持,并且提供了相关的类,分别有: Regex 、 Match 、 Group 、 Capture 、 RegexOptions 、 MatchCollection 、 GroupCollection 、 CaptureCollection 。它们之间的关联如下:
对它们描述如下:
Regex :正则表达式类,代表了一个不可变的正则表达式。
Match :代表了 Regex 类的实例的一次匹配结果,可以通过 Regex 的 Match() 实例方法返回一个 Match 的实例。
MatchCollection :代表了 Regex 类的实例的所有匹配结果,可以通过 Regex 的 Matches() 实例方法返回一个 MatchCollection 的实例。
Group :表示单个捕获组的结果。由于一次匹配可能包含 0 个、 1 个或多个分组,所以 Match 的实例中返回的是捕获组集合的结果,即 GroupCollection 。
GroupCollection :表示单个匹配中的多个捕获组的集合,可以通过 Match 的 Groups 实例属性返回 GroupCollection 的实例。
Capture :表示单个捕获中的一个子字符串。同 Group 一样,由于一个捕获中可能包含 0 个、 1 个或多个子字符串,所以 Group 的实例中返回的是子字符串集合的结果,即 CaptureCollection 。
CaptureCollection :默认表示按照从里到外、从左到右的顺序由捕获组匹配到的所有子字符串集合,可以通过 Group 或者 Match 的 Captures 实例属性返回 CaptureCollection 的实例。注意,可以使用 RegexOptions.RightToLeft 来改变这种匹配顺序。
RegexOptions :提供用于设置正则表达式选项的枚举值。 像上面提到的 RightToLeft 就是它的一个枚举值之一,除此之外还有 None 、 IgnoreCase 、 Multiline 、 ExplicitCapture 、 Compiled 、 Singleline 、 IgnorePatternWhitespace 、 RightToLeft 、 ECMAScript 及 CultureInvariant 。 RegexOptions 枚举值可以相加,比如我们想匹配不区分大小写的字符串“ abc ”并且还想提高一下执行速度,那么可以写如下代码:
RegexOptions options=RegexOptions.IgnoreCase|RegexOptions.Compiled;
Regex regex=new Regex("abc",options);
Regex 、 Match 、 Group 及 Capture 的关系及成员
从上图可以看出 Regex 类提供了许多静态方法,很多方法还提供了多种重载方式(在图中对存在多种参数重载的方法都以“ ... ”表示),除此之外我们还会发现 Capture 、 Group及 Match 之间存在继承关系(说实在话刚开始用的时候我发现它们之间存在着很多相同的字段,这让我当时迷惑不已,希望大家看到这个图后不要再像我当初那样迷惑了)。
在使用 C# 中的正则表达式进行文本处理之前先花点时间了解一下 .NET 中有关正则表达式的类和它们之间的关系是有必要的,这篇就算是预热篇了,在开始学习正则表达式之前做做热身运动。虽然在 C# 中有关正则表达式的类不多,但是对于初学者来说还是容易引起混淆,从而出现不知道该用哪些类的哪些方法或者属性的情况,这篇算是做个初步介绍吧。下一篇就先讲述 Regex 类,利用 Regex 可以用来替换、分割和处理字符串。
C#正则表达式编程(二):Regex类用法
对于正则表达式的应用,基本上可以分为验证、提取、分割和替换。仅仅利用Regex类就可以实现验证和简单替换。
利用Regex类实现验证
经历2009年的备案和DNS停止解析风波之后,大部分的带有反馈性的网站和论坛都对一些敏感词进行了过滤,包含有这类敏感词的文章要么内容被替换要么被禁止发表,利用Regex类就可以实现这个功能,下面是一个例子:
view plaincopy to clipboardprint?
/// <summary>
/// 检查字符串中是否有“孙权”这个敏感词
/// </summary>
public void IsMatchDemo()
{
string source = "刘备ABC关羽ABc张飞Abc赵云abc诸葛亮aBC孙权abC周瑜AbC鲁肃aBc曹操许攸郭嘉需晃袁绍";
Regex regex = new Regex("孙权");
//if (Regex.IsMatch(source, "孙权"))
//下面这句和上面被注释掉的一句作用的同样的
if (regex.IsMatch(source))
{
Console.WriteLine("字符串中包含有敏感词:孙权!");
}
/// <summary>
/// 检查字符串中是否有“孙权”这个敏感词
/// </summary>
public void IsMatchDemo()
{
string source = "刘备ABC关羽ABc张飞Abc赵云abc诸葛亮aBC孙权abC周瑜AbC鲁肃aBc曹操许攸郭嘉需晃袁绍";
Regex regex = new Regex("孙权");
//if (Regex.IsMatch(source, "孙权"))
//下面这句和上面被注释掉的一句作用的同样的
if (regex.IsMatch(source))
{
Console.WriteLine("字符串中包含有敏感词:孙权!");
}
输出结果:字符串中包含有敏感词:孙权!
对于上面的例子,如果要检查的字符串中包含“孙权”这个关键词就会在控制台上输出提示,当然在实际的应用中可能是包含有被禁止的词语的内容不允许提交而不是仅仅提示了。不过这类情况仍有办法可以绕过,可以使用“孙-权”或“孙+权”来替换孙权从而来绕过验证。
对于中文字符串还比较好说,对于英文的字符串还要考虑每个字母的大小写情况了。比如我们禁止在内容中出现某个关键词(如太CCTV的CCTV,或者CCAV),难道我们要针对字符串中每个字母的大小写情况进行多种情况的组合验证?不,完全没有必要,下面就是一个例子:
view plaincopy to clipboardprint?
/// <summary>
/// 检查字符串中是否有“def”的任何大小写形式
/// </summary>
public void IsMatchDemoWithOption()
{
string source = "刘备ABC关羽ABc张飞Abc赵云abc诸葛亮aBC孙权abC周瑜AbC鲁肃aBc曹操DEF许攸郭嘉需晃袁绍";
Regex regex = new Regex("def",RegexOptions.IgnoreCase);
if (regex.IsMatch(source))
{
Console.WriteLine("字符串中包含有敏感词:def!");
}
}
/// <summary>
/// 检查字符串中是否有“def”的任何大小写形式
/// </summary>
public void IsMatchDemoWithOption()
{
string source = "刘备ABC关羽ABc张飞Abc赵云abc诸葛亮aBC孙权abC周瑜AbC鲁肃aBc曹操DEF许攸郭嘉需晃袁绍";
Regex regex = new Regex("def",RegexOptions.IgnoreCase);
if (regex.IsMatch(source))
{
Console.WriteLine("字符串中包含有敏感词:def!");
}
}
输出结果:字符串中包含有敏感词:def!
在上面的例子中,实例化Regex时采用了两个带参数的构造函数,其中第二个参数就是上一篇中提到的RegexOptions枚举,RegexOptions.IgnoreCase表示匹配字符串的时候不管大小写是否一致。
此外,在Regex中存在着一些功能相同的静态方法和实例方法,如:IsMatch()方法,在第一个例子中我还写出了两种方法的实例,如下:
view plaincopy to clipboardprint?
Regex regex = new Regex("孙权");
//if (Regex.IsMatch(source, "孙权"))
//下面这句和上面被注释掉的一句作用的同样的
if (regex.IsMatch(source))
Regex regex = new Regex("孙权");
//if (Regex.IsMatch(source, "孙权"))
//下面这句和上面被注释掉的一句作用的同样的
if (regex.IsMatch(source))
其实在.NET Framework中很多类都有这样类似的情况,在System.IO命名空间下还有File及FileInfo这样的静态类和非静态类的情况,其实它们提供了相似的功能,用小沈阳的话说“这是为什么呢”?有部分是出自效率的考虑,并且也有出自让代码编写方便和看起来简洁的因素。对于偶尔一半次为之的情况,建议使用静态方法,这样有可能会提高效率(因为采用静态方法调用的正则表达式会被内部缓存,默认情况下会缓存15个,可以通过设置Regex类的CacheSize属性来更改缓存个数),如果是要在循环中多次使用,那就采用实例方法吧。
使用Regex类进行替换
上面的处理仅仅是查看提交的内容中是否有被禁止的关键词,其实有时候还可以做到将被禁止的关键词进行替换,例如将上面用到的字符串中的任何形式的"ABC"替换成"|",下面就是一个例子:
view plaincopy to clipboardprint?
/// <summary>
/// 实现字符串替换功能
/// </summary>
public void Replace()
{
string source = "刘备ABC关羽ABc张飞Abc赵云abc诸葛亮aBC孙权abC周瑜AbC鲁肃aBc曹操DEF许攸郭嘉需晃袁绍";
Regex regex = new Regex("abc", RegexOptions.IgnoreCase);
string result=regex.Replace(source, "|");
Console.WriteLine("原始字符串:" + source);
Console.WriteLine("替换后的字符串:" + result);
}
/// <summary>
/// 实现字符串替换功能
/// </summary>
public void Replace()
{
string source = "刘备ABC关羽ABc张飞Abc赵云abc诸葛亮aBC孙权abC周瑜AbC鲁肃aBc曹操DEF许攸郭嘉需晃袁绍";
Regex regex = new Regex("abc", RegexOptions.IgnoreCase);
string result=regex.Replace(source, "|");
Console.WriteLine("原始字符串:" + source);
Console.WriteLine("替换后的字符串:" + result);
}
输出结果:
原始字符串:刘备ABC关羽ABc张飞Abc赵云abc诸葛亮aBC孙权abC周瑜AbC鲁肃aBc曹操DEF许攸郭嘉需晃袁绍
替换后的字符串:刘备|关羽|张飞|赵云|诸葛亮|孙权|周瑜|鲁肃|曹操DEF许攸郭嘉需晃袁绍
实际上有时候我们遇到的情况可能不仅仅这么简单,例如有时候我们希望将字符串中的任何形式的“ABC”及“DEF”实现HTML形式的加粗,也就是替换成<b>abc</b>及<b>def</b>这种形式,当然还保持和原来一致的大小写形式,代码如下:
view plaincopy to clipboardprint?
/// <summary>
/// 实现字符串替换功能
/// </summary>
public void ReplaceMatchEvaluator()
{
string source = "刘备ABC关羽ABc张飞Abc赵云abc诸葛亮aBC孙权abC周瑜AbC鲁肃aBc曹操DEF许攸郭嘉需晃袁绍";
Regex regex = new Regex("[A-Z]{3}", RegexOptions.IgnoreCase);
string result = regex.Replace(source, new MatchEvaluator(OutPutMatch));
Console.WriteLine("原始字符串:" + source);
Console.WriteLine("替换后的字符串:" + result);
}
/// <summary>
/// MatchEvaluator委托中调用的方法,可以对匹配结果进行处理
/// </summary>
/// <param name="match">操作过程中的单个正则表达式匹配</param>
/// <returns></returns>
private string OutPutMatch(Match match)
{
return "<b>" + match.Value + "</b>";
}
/// <summary>
/// 实现字符串替换功能
/// </summary>
public void ReplaceMatchEvaluator()
{
string source = "刘备ABC关羽ABc张飞Abc赵云abc诸葛亮aBC孙权abC周瑜AbC鲁肃aBc曹操DEF许攸郭嘉需晃袁绍";
Regex regex = new Regex("[A-Z]{3}", RegexOptions.IgnoreCase);
string result = regex.Replace(source, new MatchEvaluator(OutPutMatch));
Console.WriteLine("原始字符串:" + source);
Console.WriteLine("替换后的字符串:" + result);
}
/// <summary>
/// MatchEvaluator委托中调用的方法,可以对匹配结果进行处理
/// </summary>
/// <param name="match">操作过程中的单个正则表达式匹配</param>
/// <returns></returns>
private string OutPutMatch(Match match)
{
return "<b>" + match.Value + "</b>";
}
输出结果如下:
原始字符串:刘备ABC关羽ABc张飞Abc赵云abc诸葛亮aBC孙权abC周瑜AbC鲁肃aBc曹操DEF许攸郭嘉需晃袁绍
替换后的字符串:刘备<b>ABC</b>关羽<b>ABc</b>张飞<b>Abc</b>赵云<b>abc</b>诸葛亮<b>aBC</b>孙权<b>abC</b>周瑜<b>AbC</b>鲁肃<b>aBc</b>曹操<b>DEF</b>许攸郭嘉需晃袁绍
在上面的例子中,我们使用了MatchEvaluator委托,并且还涉及到了Match类(Match类将会在下一篇讲述),在MatchEvaluator委托中使用到的Match类表示了单个的正则表达式匹配,通过改变match实例中Value的值来达到完成替换的目的。
在本篇中仅仅是讲述了Regex类的一些简单用法,也没有讲述正则表达式的相关知识,不过即使如此也能减轻我们的一部分工作,学习和灵活运用正则表达式是一个长期积累的过程。
 C#正则表达式编程(三):Match类和Group类用法 C#正则表达式编程(三):Match类和Group类用法 
前面两篇讲述了正则表达式的基础和一些简单的例子,这篇将稍微深入一点探讨一下正则表达式分组,在.NET中正则表达式分组是用Math类来代表的。
首先先看一段代码:
- public void ShowStructure()
- {
-
- string text = "1A 2B 3C 4D 5E 6F 7G 8H 9I 10J 11Q 12J 13K 14L 15M 16N ffee80 #800080";
-
- string pattern = @"((\d+)([a-z]))\s+";
-
- Regex r = new Regex(pattern, RegexOptions.IgnoreCase);
-
- Match m = r.Match(text);
- while (m.Success)
- {
-
- System.Console.WriteLine("Match=[" + m + "]");
- CaptureCollection cc = m.Captures;
- foreach (Capture c in cc)
- {
- Console.WriteLine("\tCapture=[" + c + "]");
- }
- for (int i = 0; i < m.Groups.Count; i++)
- {
- Group group = m.Groups[i];
- System.Console.WriteLine("\t\tGroups[{0}]=[{1}]", i, group);
- for (int j = 0; j < group.Captures.Count; j++)
- {
- Capture capture = group.Captures[j];
- Console.WriteLine("\t\t\tCaptures[{0}]=[{1}]", j, capture);
- }
- }
-
- m = m.NextMatch();
- }
- }
这段代码的执行效果如下:
Match=[1A ]
Capture=[1A ]
Groups[0]=[1A ]
Captures[0]=[1A ]
Groups[1]=[1A]
Captures[0]=[1A]
Groups[2]=[1]
Captures[0]=[1]
Groups[3]=[A]
Captures[0]=[A]
Match=[2B ]
Capture=[2B ]
Groups[0]=[2B ]
Captures[0]=[2B ]
Groups[1]=[2B]
Captures[0]=[2B]
Groups[2]=[2]
Captures[0]=[2]
Groups[3]=[B]
Captures[0]=[B]
..................此去省略一些结果
Match=[16N ]
Capture=[16N ]
Groups[0]=[16N ]
Captures[0]=[16N ]
Groups[1]=[16N]
Captures[0]=[16N]
Groups[2]=[16]
Captures[0]=[16]
Groups[3]=[N]
Captures[0]=[N]
通过对上面的代码结合代码的分析,我们得出下面的结论,在((\d+)([a-z]))\s+这个正则表达式里总共包含了四个Group,即分组,按照默认的从左到右的匹配方式,其中Groups[0]代表了整个分组,其它的则是子分组,用示意图表示如下:
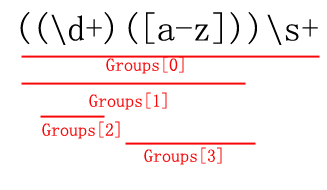
在上面的代码中是采用了Regex类的Match()方法,调用这种方法返回的是一个Match,要处理分析全部的字符串,还需要在while循环的中通过Match类的NextMatch()方法返回下一个可能成功的匹配(可通过Match类的Success属性来判断是否成功匹配)。上面的代码还可以写成如下形式:
- public void Matches()
- {
-
- string text = "1A 2B 3C 4D 5E 6F 7G 8H 9I 10J 11Q 12J 13K 14L 15M 16N ffee80 #800080";
-
- string pattern = @"((\d+)([a-z]))\s+";
-
- Regex r = new Regex(pattern, RegexOptions.IgnoreCase);
-
- MatchCollection matchCollection = r.Matches(text);
- foreach (Match m in matchCollection)
- {
-
- System.Console.WriteLine("Match=[" + m + "]");
- CaptureCollection cc = m.Captures;
- foreach (Capture c in cc)
- {
- Console.WriteLine("\tCapture=[" + c + "]");
- }
- for (int i = 0; i < m.Groups.Count; i++)
- {
- Group group = m.Groups[i];
- System.Console.WriteLine("\t\tGroups[{0}]=[{1}]", i, group);
- for (int j = 0; j < group.Captures.Count; j++)
- {
- Capture capture = group.Captures[j];
- Console.WriteLine("\t\t\tCaptures[{0}]=[{1}]", j, capture);
- }
- }
- }
- }
上面的这段代码和采用While循环遍历所有匹配的结果是一样的,在实际情况中有可能出现不需要全部匹配而是从某一个位置开始匹配的情况,比如从第32个字符处开始匹配,这种要求可以通过Match()或者Matches()方法的重载方法来实现,仅需要将刚才的实例代码中的MatchCollection matchCollection = r.Matches(text);改为MatchCollection matchCollection = r.Matches(text,48);就可以了。
输出结果如下:
Match=[5M ]
Capture=[5M ]
Groups[0]=[5M ]
Captures[0]=[5M ]
Groups[1]=[5M]
Captures[0]=[5M]
Groups[2]=[5]
Captures[0]=[5]
Groups[3]=[M]
Captures[0]=[M]
Match=[16N ]
Capture=[16N ]
Groups[0]=[16N ]
Captures[0]=[16N ]
Groups[1]=[16N]
Captures[0]=[16N]
Groups[2]=[16]
Captures[0]=[16]
Groups[3]=[N]
Captures[0]=[N]
注意上面的MatchCollection matchCollection = r.Matches(text,48)表示从text字符串的位置48处开始匹配,要注意位置0位于整个字符串的之前,位置1位于字符串中第一个字符之后第二个字符之前,示意图如下(注意是字符串“1A”与“2B”之间有空格):
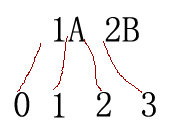
在text的位置48处正好是15M中的5处,因此返回的第一个Match是5M而不是15M。这里还继续拿出第一篇中的图来,如下:
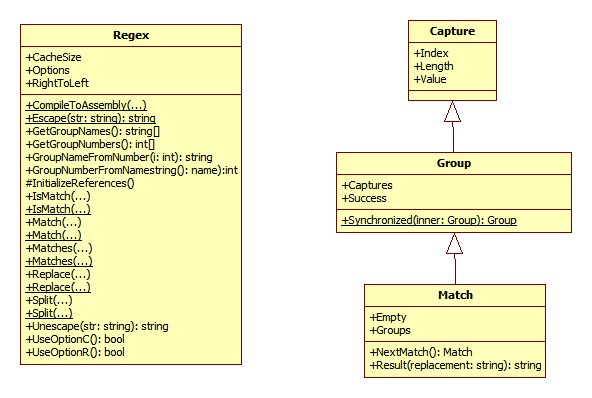
从上图可以看出Capture、Group及Match类之间存在继承关系,处在继承关系顶端的Capture类中就定义了Index、Length和Value属性,其中Index表示原始字符串中发现捕获子字符串的第一个字符的出现位置,Length属性表示子字符串的长度,而Value属性表示从原始字符串中捕获的子字符串,利用这些属性可以实现一些比较复杂的应用。例如在现在还有很多论坛仍没有使用所见即所得的在线编辑器,而是使用了一种UBB编码的编辑器,使用所见即所得的编辑器存在着一定的安全风险,比如可以在源代码中嵌入js代码或者其它恶意代码,这样浏览者访问时就会带来安全问题,而使用UBB代码就不会代码这个问题,因为UBB代码包含了有限的、但不影响常规使用的标记并且支持UBB代码的编辑器不允许直接在字符串中出现HTML代码,也而就避免恶意脚本攻击的问题。在支持UBB代码的编辑器中输入的文本在存入数据库中保存的形式是UBB编码,显示的时候需要将UBB编码转换成HTML代码,例如下面的一段代码就是UBB编码:
http://zhoufoxcn.blog.51cto.com[/url][url=http://blog.csdn.net/zhoufoxcn]周公的专栏
下面通过例子演示如何将上面的UBB编码转换成HTML代码:
- 下面通过例子演示如何将上面的UBB编码转换成HTML代码:
- public void UBBDemo()
- {
- string text = "[url=http://zhoufoxcn.blog.51cto.com][/url][url=http://blog.csdn.net/zhoufoxcn]周公的专栏[/url]";
- Console.WriteLine("原始UBB代码:" + text);
- Regex regex = new Regex(@"(\[url=([ \S\t]*?)\])([^[]*)(\[\/url\])", RegexOptions.IgnoreCase);
- MatchCollection matchCollection = regex.Matches(text);
- foreach (Match match in matchCollection)
- {
- string linkText = string.Empty;
-
- if (!string.IsNullOrEmpty(match.Groups[3].Value))
- {
- linkText = match.Groups[3].Value;
- }
- else
- {
- linkText = match.Groups[2].Value;
- }
- text = text.Replace(match.Groups[0].Value, "<a href="\" mce_href="\""" + match.Groups[2].Value + "\" target=\"_blank\">" + linkText + "</a>");
- }
- Console.WriteLine("替换后的代码:"+text);
- }
程序执行结果如下:
原始UBB代码:[url=http://zhoufoxcn.blog.51cto.com][/url][url=http://blog.csdn.net/zhoufoxcn]周公的专栏[/url]
替换后的代码:<a href="http://zhoufoxcn.blog.51cto.com" target="_blank">http://zhoufoxcn.blog.51cto.com</a><a href="http://blog.csdn.net/zhoufoxcn"target="_blank">周公的专栏</a>
上面的这个例子就稍微复杂点,对于初学正则表达式的朋友来说,可能有点难于理解,不过没有关系,后面我会讲讲正则表达式。在实际情况下,可能通过match.Groups[0].Value这种方式不太方便,就想在访问DataTable时写string name=dataTable.Rows[i][j]这种方式一样,一旦再次调整,这种通过索引的方式极容易出错,实际上我们也可以采用名称而不是索引的放来来访问Group分组,这个也会在以后的篇幅中去讲。
|

