MySQL Select tables optimized away
Select tables optimized away
场景
cloud_system_wf表有两个索引date_time,sys_code
CREATE TABLE `cloud_system_wf` (
`id` bigint(10) NOT NULL AUTO_INCREMENT,
`sys_code` varchar(255) NOT NULL COMMENT '系统',
`date_time` varchar(255) DEFAULT NULL COMMENT '日期时间',
`add_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_system_code` (`sys_code`) USING BTREE,
KEY `idx_date_time` (`date_time`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1728472 DEFAULT CHARSET=utf8mb4 ROW_FORMAT=DYNAMIC COMMENT='';
EXPLAIN有max( date_time )函数的执行计划
EXPLAIN
SELECT
max( date_time )
FROM
cloud_system_wf
Extra中返回Select tables optimized away

问题
- 为什么会出现
Select tables optimized away
分析
- MySQL执行查询过程
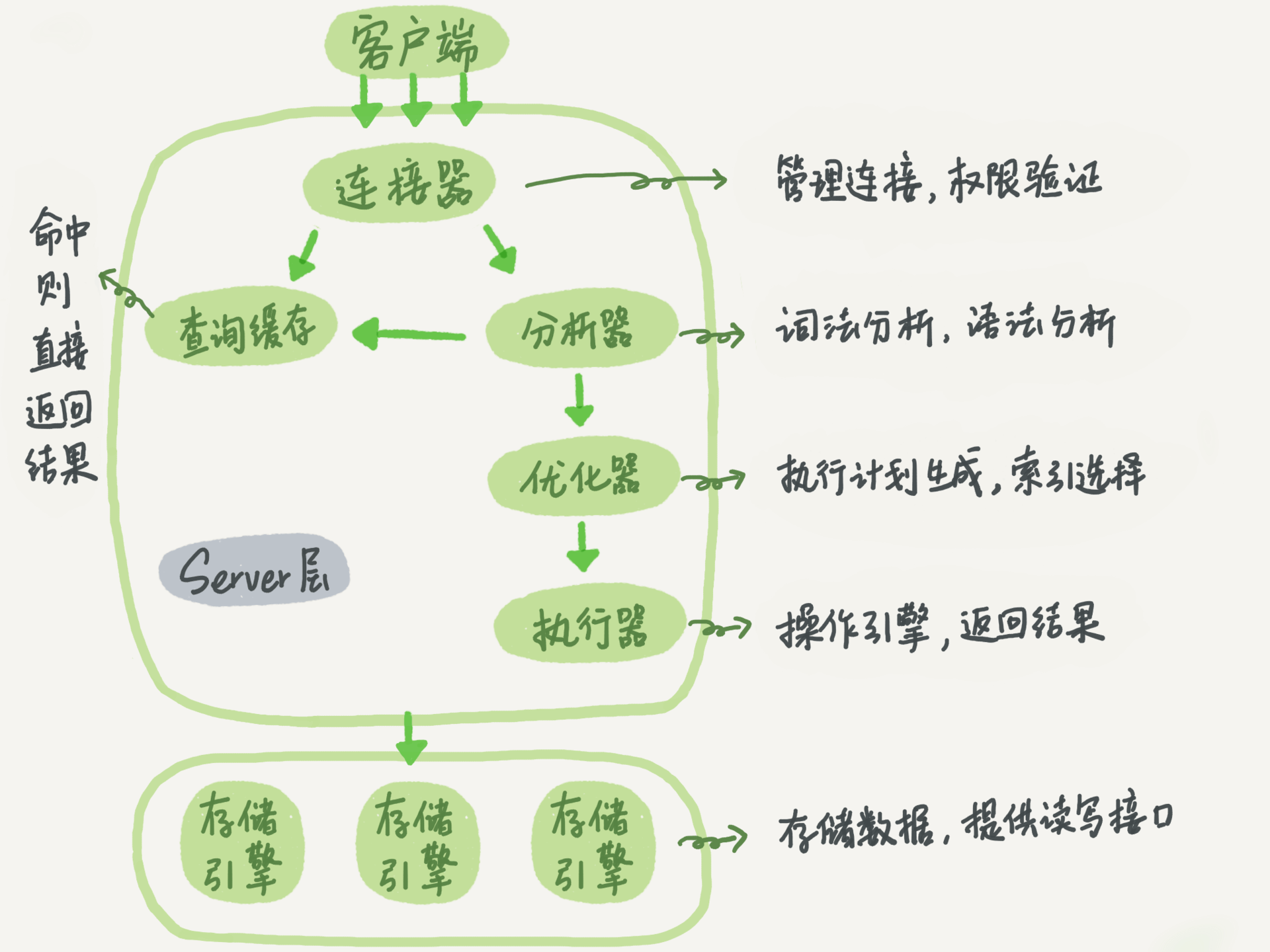

- 根据官方文档的解释
-
- 在没有显示的使用
group by语句,查询隐式带有grouped含义,且至多返回一行
- 在没有显示的使用
-
- 要得到这一行的数据,需要读取多行并筛选,且可以在优化阶段(比如读取索引树),就无需读取数据表。此时读取的索引数就决定了读取的筛选行数。
-
Select tables optimized away (JSON property: message)
The optimizer determined 1) that at most one row should be returned, and 2) that to produce this row, a deterministic set of rows must be read. When the rows to be read can be read during the optimization phase (for example, by reading index rows), there is no need to read any tables during query execution.
The first condition is fulfilled when the query is implicitly grouped (contains an aggregate function but no GROUP BY clause). The second condition is fulfilled when one row lookup is performed per index used. The number of indexes read determines the number of rows to read.
- 个人理解
- 需要使用隐式聚合函数,比如
MAX()/MIN(), 且不使用group by,结果返回1行 - 且函数需要作用在有索引的行
- 需要使用隐式聚合函数,比如
验证
-
作用在没有索引的
add_timeEXPLAIN SELECT max( add_time ) FROM cloud_system_wf
结论
- 在没有group by子句的情况下,基于索引优化MIN/MAX操作或者对于MyISAM存储引擎优化COUNT(*)操作,不必等到执行阶段在进行计算,查询执行计划生成的阶段即可完成优化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号