mysql系列——优化sql及sql练习(十二)
如何优化sql?
开启数据库慢查询日志,定位到查询效率比较低的sql 并分析
1.查看sql语句是否规范
(1)避免使用关键字:or ,in,not in ,!=,<>,避免使用select *
(2)尽量避免子查询,大部分子查询都可以连接查询
(3)用到or的地方可以使用union去代替实现
(4)用到in的地方可以考虑使用exists去代替
in适合于外表大而内表小的情况,exists适合于外表小而内表大
2.查看表中是否存在大量的冗余字段,字段数据类型是否合理
(1) 比如能用数值的绝对不用字符存储,使用varchar代替char
(2)尽量避免null值,使用默认值替代空值,数值型可以使用0,字符型可以使用空字符串
3.分析sql的索引是否可以用
(1) explain查询sql的执行计划,重点关注的几个列就是,type是不是全表扫描
(2)看一下索引是否能够用的上,主要看key使用的是哪个索引
(3)看一下rows扫描行数是不是很大
sql练习
试题.删除一张表中重复记录,重复记录中保留id小的记录
DROP TABLE IF EXISTS `tb_coupon`;
CREATE TABLE `tb_coupon` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '优惠卷id',
`name` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '优惠卷名称',
`type` enum('1','2','3') CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '优惠卷类型,1、抵扣 2、折扣(打折)',
`condition` bigint(20) NULL DEFAULT 0 COMMENT '抵扣或折扣条件,如果没有限制,则设置为0',
`reduction` bigint(20) NULL DEFAULT 0 COMMENT '优惠金额',
`discount` int(3) NULL DEFAULT 100 COMMENT '如果没有折扣,为100。如果是八五折,折扣为85',
`targets` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '' COMMENT '优惠券可以生效的sku的id拼接,以,分割',
`stock` int(6) NOT NULL COMMENT '剩余优惠券数量',
`start_time` datetime NOT NULL COMMENT '优惠券生效时间',
`end_time` datetime NOT NULL COMMENT '优惠券失效时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 2 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '优惠卷表' ROW_FORMAT = Compact;
INSERT INTO `tb_coupon` VALUES (1, 'uuu', '1', 0, 0, 100, '', 2, '1000-01-01 00:00:00', '1000-01-01 00:00:00');
INSERT INTO `tb_coupon` VALUES (2, 'uuu', '1', 0, 0, 100, '', 2, '1000-01-01 00:00:00', '1000-01-01 00:00:00');
INSERT INTO `tb_coupon` VALUES (3, 'ddd', '2', 0, 0, 100, '', 2, '1000-01-01 00:00:00', '1000-01-01 00:00:00');
INSERT INTO `tb_coupon` VALUES (4, 'ddd', '2', 0, 0, 100, '', 2, '1000-01-01 00:00:00', '1000-01-01 00:00:00');
INSERT INTO `tb_coupon` VALUES (5, 'eee', '2', 0, 0, 100, '', 2, '1000-01-01 00:00:00', '1000-01-01 00:00:00');
INSERT INTO `tb_coupon` VALUES (6, 'eee', '3', 0, 0, 100, '', 2, '1000-01-01 00:00:00', '1000-01-01 00:00:00');
答案:delete from tb_coupon where name in (select name from(select name from tb_coupon group by name HAVING count(name)>1)a )
and id not in(select id from(select min(id) as id from tb_coupon GROUP BY name HAVING count(name)>1)b);
注意:不能将直接查出来的数据当做删除数据的条件,我们应该先把查出来的数据作为一张临时表,然后再把临时表作为条件进行删除功能
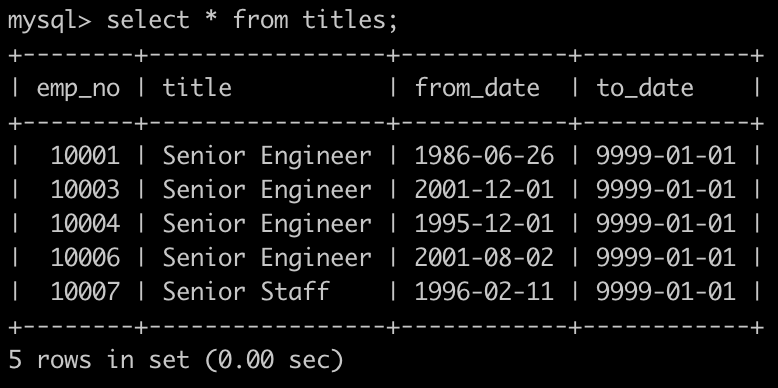
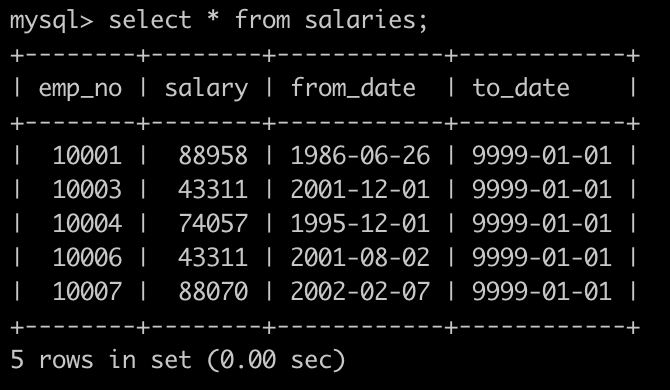
select avg(s.salary),t.title from salaries s join titles t on s.emp_no=t.emp_no group by t.title
注意:连表之后根据连接条件group by,salary字段也被分组
试题.用一条SQL 语句 查询出每门课都大于80 分的学生姓名
name kecheng fenshu
张三 语文 81
张三 数学 75
李四 语文 76
李四 数学 90
王五 语文 81
王五 数学 100
王五 英语 90
A: select distinct name from table where name not in (select distinct name from table where fenshu<=80)
B: select name from table group by name having min(fenshu)>80
试题请你查找employees表所有emp_no为奇数,且last_name不为Mary的员工信息,并按照hire_date逆序排列
select * from employees where emp_no % 2 = 1 and last_name<>'Mary' order by hire_date desc;
注意:emp_no % 2取余后为1也可以改成MOD(emp_no, 2)=1,但是某些sql版本可能不支持后者
不相等有三种表示方式:<>、!=、IS NOT
试题. 删除除了自编号不同, 其它都相同的学生冗余信息
学生表 如下:
编号 学号 姓名 课程编号 课程名称 分数
1 2005001 张三 0001 数学 69
2 2005002 李四 0001 数学 89
3 2005001 张三 0001 数学 69
A: delete from table where 编号 not in(select min( 编号) from table group by学号, 姓名, 课程编号, 课程名称, 分数)
注意:可以根据多个字段分组
试题.一个叫 team 的表,里面只有一个字段name, 一共有4 条纪录,分别是a,b,c,d, 对应四个球队比赛,用一条sql 语句查出所有可能的比赛组合.
你先按你自己的想法做一下,看结果有我的这个简单吗?
答:select a.name, b.name from team a, team b where a.name < b.name
注意:一张表可以用使用不同的名字从而多次使用。
试题:怎么把这样一个表儿
year month amount
1991 1 1.1
1991 2 1.2
1991 3 1.3
1991 4 1.4
1992 1 2.1
1992 2 2.2
1992 3 2.3
1992 4 2.4
查成这样一个结果
year m1 m2 m3 m4
1991 1.1 1.2 1.3 1.4
1992 2.1 2.2 2.3 2.4
答案一、
select year,
(select amount from aaa m where month=1 and m.year=aaa.year) as m1,
(select amount from aaa m where month=2 and m.year=aaa.year) as m2,
(select amount from aaa m where month=3 and m.year=aaa.year) as m3,
(select amount from aaa m where month=4 and m.year=aaa.year) as m4
from aaa group by year
有两个表A 和B ,均有key 和value 两个字段,如果B 的key 在A 中也有,就把B 的value 换为A 中对应的value
这道题的SQL 语句怎么写?
update b set b.value=(select a.value from a where a.key=b.key) where b.id in(select b.id from b,a where b.key=a.key);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号