mysql系列——子查询及连接查询(六)
一、子查询
-
出现在select语句中的select语句,称为子查询或内查询。
-
外部的select查询语句,称为主查询或外查询
二、准备测试数据
浏览器中打开链接:http://www.itsoku.com/course/3/196
mysql中执行里面的 javacode2018_employees 库脚本。
成功创建此库后,会有以下5张表:
| 表名 | 描述 |
|---|---|
| departments | 部门表 |
| employees | 员工信息表 |
| jobs | 职位信息表 |
| locations | 位置表(部门表会用到) |
| job_grades | 薪资等级表 |
selec后面的子查询
查询每个部门员工个数
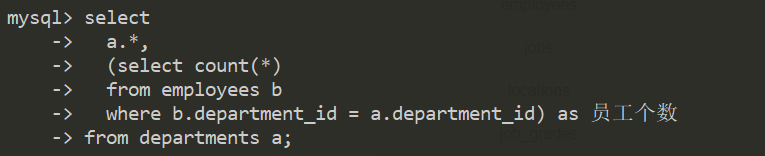
from后面的子查询
将子查询的结果集充当一张表,要求必须 起别名,否则这个表找不到。
1、查询每个部门 平均工资的工资等级
查询每个部门平均工资 SELECT department_id, avg(a.salary) FROM employees a GROUP BY a.department_id; 查询薪资等级 SELECT * FROM job_grades; 将上面2个结果连接查询,筛选条件:平均工资 SELECT t1.department_id, t1.sa, t2.grade_level FROM (SELECT department_id, avg(a.salary) sa FROM employees a GROUP BY a.department_id) t1,job_grades t2 WHERE t1.sa BETWEEN t2.lowest_sal AND highest_sal;
where和having后面的子查询
in,any,some,all分别是子查询关键词之一
in (not in) : 列表中"任意一个",in常用于where表达式中,其作用是查询某个范围内的数据
any/some: 可以与=、>、<、>=、<=、<>(!=) 结合起来使用,分别表示等于、大于、小于、大于等于、小于等于、不等于
其中任何一个数据 ,和子查询返回的"某一个值"比较。例如:a>some(10,20,30),a大于子查询中的任意一个即可,
a大于子查询中最小值即可,其等同于a>min(10,20,30)。
all :可以与=、>、<、>=、<=、<>(!=) 结合起来使用,分别表示大于等于、小于等于、不等于,其中的所有数据 ,
和子查询返回的"所有值"比较。例如:a>all(10,20,30),即a大于子查询中的最大值,其等同于a>max(10,20,30)。
示例:查询最低工资大于50号部门最低工资的部门id和其最低工资
查询50号部门的最低工资 SELECT min(salary) FROM employees WHERE department_id = 50; 查询每个部门的最低工资 SELECT department_id,min(salary) as '最低工资' FROM employees GROUP BY department_id; 在查询二的基础上,满足查询一 SELECT a.department_id,min(a.salary) as '最低工资' FROM employees a GROUP BY a.department_id HAVING min(a.salary) > (SELECT min(salary) FROM employees WHERE department_id = 50);
示例:返回location_id是1400或1700的部门中所有员工姓名
提示:列子查询需搭配多行操作符使用:in(not in)、any/some、all,为提升效率,最好用distinct 关键字去重一下。
方式一 SELECT a.last_name FROM employees a WHERE a.department_id = ANY (SELECT DISTINCT department_id FROM departments WHERE location_id IN (1400, 1700));
方式二
SELECT a.last_name FROM employees a WHERE a.department_id = SOME (SELECT DISTINCT department_id FROM departments WHERE location_id IN (1400, 1700));
exists后面
1、语法:exists(玩转的查询语句);
2、exists查询结果:1或0,exists查询的结果用来判断子查询的结果集中是否有值;
3、一般来说,能用exists的子查询,绝对都能用in代替,所以exists用的少;
4、和前面的查询不同,这先执行主查询,然后主查询查询的结果,在根据子查询进行过滤。
示例1:简单示例
mysql> select exists (select employee_id from employees where salary = 30000000) as 'exists返回1或0'; +-------------------+ | exists返回1或0 | +-------------------+ | 0 | +-------------------+ 1 row in set (0.00 sec)
示例2:查询所有员工的部门名称
exists入门案例 mysql> select exists (select employee_id from employees where salary = 30000000) as 'exists返回1或0'; 查询所有员工部门名 SELECT department_name FROM departments a WHERE EXISTS (SELECT 1 FROM employees b WHERE a.department_id = b.department_id);
使用in实现 SELECT department_name FROM departments a WHERE a.department_id IN (SELECT department_id FROM employees);
三、NULL的大坑
in的情况下,子查询中列的值为NULL的时候,外查询的结果为空。建议建表时,列不允许为空
示例1:使用in的方式查询没有员工的部门,如下:
SELECT * FROM departments a WHERE a.department_id NOT IN (select department_id from employees);
运行结果如下:
mysql> select *
-> from departments a
-> where a.department_id not in (select department_id from employees);
Empty set (0.02 sec)
四、连接查询
create table t_score(id int primary key auto_increment,stu_id int not null, score decimal(5,2));
注意: decimal(10,2)中“2”表示小数部分的位数,插入的值未指定小数部分或小数部分不足两位则自动补到2位小数
若插入的值小数部分超过了2为则会发生截断,截取前2位小数。10指的是整数部分加小数部分的总长度,
即插入的数字整数部分不能超过“10-2”位,否则不能成功插入,会报超出范围的错误。
内连接 :
join等同于inner join,内连接返回的是符合连接条件且两个表中都有对应数据的记录。若符合条件 但某一字段值为null,查出来的是null
连接条件on ,using, where区别:
on 是在连表查询中,任何情况下都可以使用on,而且建议使用on。
on是在连表的过程中,根据on条件判断是否保留连表的结果。
using 是在连表查询的字段名一致时可以使用。
如using(age)等同与on a.age=b.age。
where是在连表操作完成后,再根据where条件进行数据过滤。效率低不建议这样。
假设,A,B两表各有一个字段
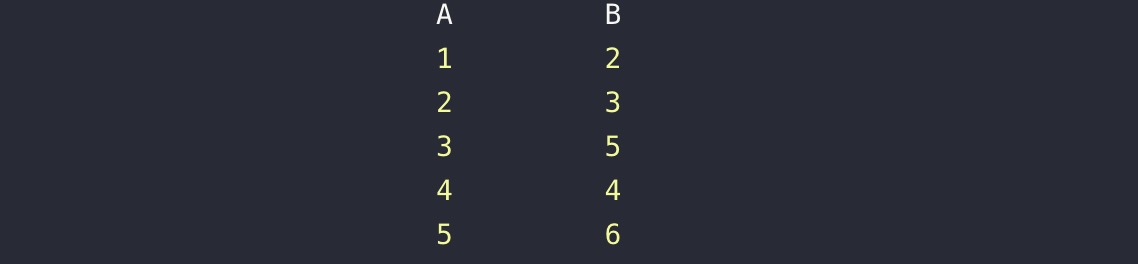
inner join 是默认的,实际效果是去两个表都有的部分,而不是交集的部分不予显示,可以获取到两表的交集部分
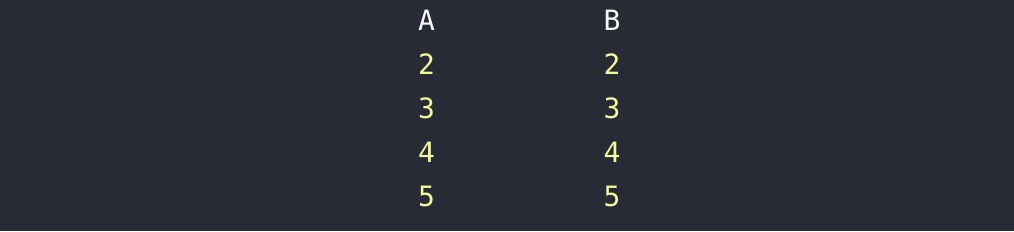
外连接:
查询时允许另一方存在与之不匹配的数据。外连接的连接条件不可使用where,必须使用using和on的一种,其他都与内连接一致。
左外连接(left outer join/ left join )
左表为主表,即使右表没有与之匹配的记录,也返回左表的记录。而右表与左表不匹配的记录将显示为null。 右外连接与左外连接相反。
1.left join :左表完全获取,如果left join 右表此字段没有值则默认为null,最后显示为左表的此字段的全部元素和右表此字段存在的元素若不存在则为null
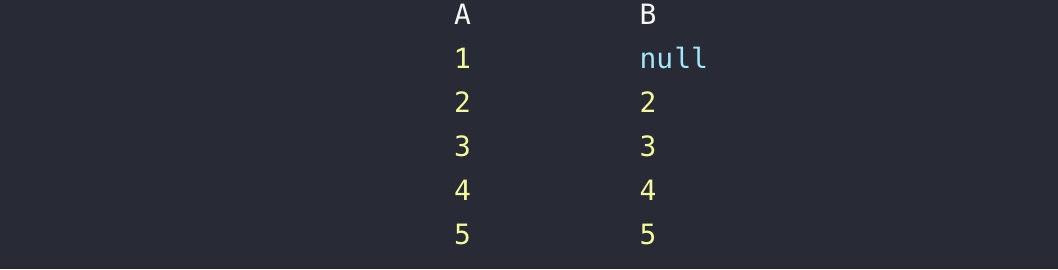
2.full join:显示全表,若另一表中无相同元素则为null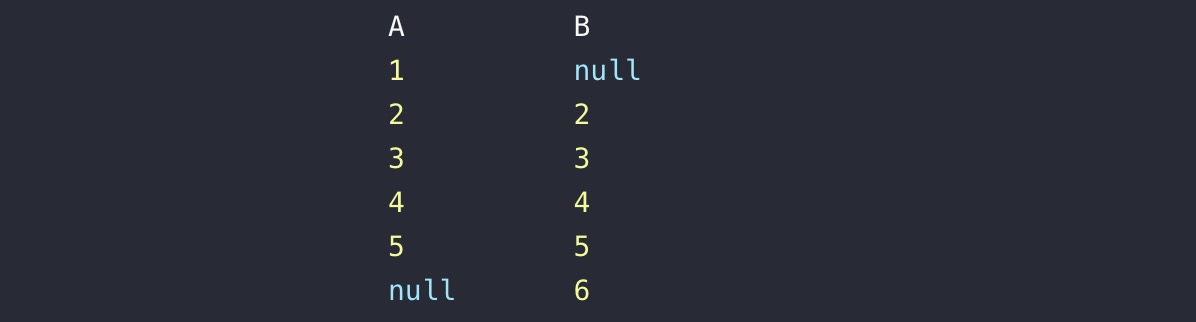

 浙公网安备 33010602011771号
浙公网安备 33010602011771号