
Redis---缓存雪崩,缓存穿透,缓存击穿,缓存预热概念及解决方案
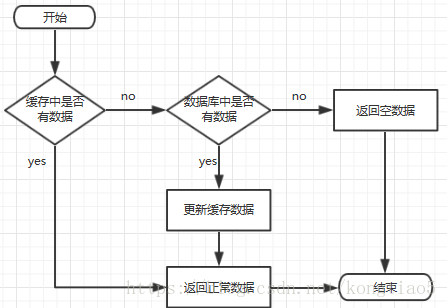
一、缓存处理流程
前台请求,后台先从缓存中取数据,取到直接返回结果,取不到时从数据库中取,数据库取到更新缓存,并返回结果,数据库也没取到,那直接返回空结果。
二:缓存雪崩
概念:当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候由于查询数据量巨大,引起数据库压力过大甚至down机。
解决方案:
- 缓存数据的过期时间在一个基础的时间上加一个随机值,防止同一时间大量数据过期现象发生。
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同缓存数据库中。
- 设置热点数据永远不过期。
三:缓存穿透
概念: 缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,缓存层和存储层都不会命中,通常出于容错的考虑,如果从存储层查不到数据则不写入缓存层。
例如用户不断发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。这时可以在接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
解决方案一:缓存空对象

/**
* 缓存空对象:
* 此种方式存在漏洞,不经过判断就直接将Null对象存入到缓存中,
* 如果恶意制造很多不存在的id,那么缓存中的键值就会很多,恶意攻击时,很可能会被打爆,所以需设置较短的过期时间。
*/
public Object getObjectInclNullById(Integer id) {
// 从缓存中获取数据
Object cacheValue = cache.get(id);
// 缓存为空
if (cacheValue != null) {
// 从数据库中获取
Object storageValue = storage.get(key);
// 缓存空对象
cache.set(key, storageValue);
// 如果存储数据为空,需要设置一个过期时间(300秒)
if (storageValue == null) {
// 必须设置过期时间,否则有被攻击的风险
cache.expire(key, 60 * 5);
}
return storageValue;
}
return cacheValue;
}
缓存空对象会有一个必须考虑的问题:
缓存空对象的时候缓存层中会存更多的键,需要更多的内存空间(如果是攻击,问题更严重),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
解决方案二:布隆过滤器拦截
布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间越来越大。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为 O(n),O(log n),O(n/k)。
布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
示例:google guava包下有对布隆过滤器的封装,BloomFilter。
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class BloomFilterTest {
// 初始化一个能够容纳10000个元素且容错率为0.01布隆过滤器
private static final BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), 10000, 0.01);
//初始化布隆过滤器
private static void initLegalIdsBloomFilter() {
// 初始化10000个合法Id并加入到过滤器中
for (int legalId = 0; legalId < 10000; legalId++) {
bloomFilter.put(legalId);
}
}
//id是否合法有效,即是否在过滤器中
public static boolean validateIdInBloomFilter(Integer id) {
return bloomFilter.mightContain(id);
}
public static void main(String[] args) {
// 初始化过滤器
initLegalIdsBloomFilter();
// 误判个数
int errorNum=0;
// 验证从10000个非法id是否有效
for (int id = 10000; id < 20000; id++) {
if (validateIdInBloomFilter(id)){
// 误判数
errorNum++;
}
}
System.out.println("judge error num is : " + errorNum);
}
}
实现布隆过滤器拦截
设置过期时间,让其自动过期失效,这种在很多时候不是最佳的实践方案。
我们可以提前将真实正确的商品Id,在添加完成之后便加入到过滤器当中,每次再进行查询时,先确认要查询的Id是否在过滤器当中,如果不在,则说明Id为非法Id,则不需要进行后续的查询步骤了。
/**
* 防缓存穿透的:布隆过滤器
*/
public Object getObjectByBloom(Integer id) {
// 判断是否为合法id
if (!bloomFilter.mightContain(id)) {
// 非法id,则不允许继续查库
return null;
} else {
// 从缓存中获取数据
Object cacheValue = cache.get(id);
// 缓存为空
if (cacheValue == null) {
// 从数据库中获取
Object storageValue = storage.get(id);
// 缓存空对象
cache.set(id, storageValue);
}
return cacheValue;
}
}
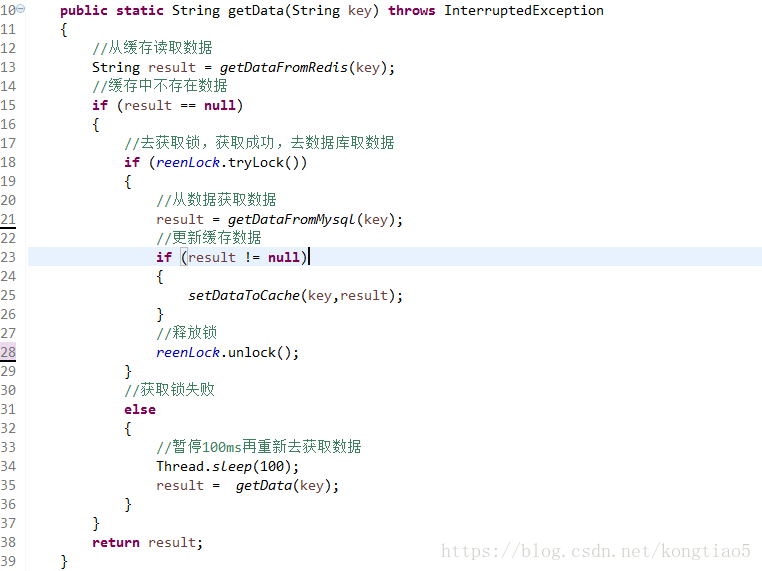
四:缓存击穿
概念:缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
补充:通常使用缓存 + 过期时间的策略来帮助我们加速接口的访问速度,减少了后端负载,同时保证功能的更新,一般情况下这种模式已经基本满足要求了。但如下两个问题如果同时出现,可能就会对系统造成致命的危害:其一:这个key是一个热点key,其二是key的访问量非常大缓存的构建是需要一定时间的。(可能是一个复杂计算,例如复杂的sql、多次IO、多个依赖(各种接口)等等),于是就会出现一个致命问题:在缓存失效的瞬间,有大量线程来构建缓存,造成后端负载加大,甚至可能会让系统崩溃 。
解决方案:
- 设置热点数据永远不过期。
- 加互斥锁,互斥锁参考代码如下:
五:缓存预热
概念:缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
解决思路:
1.直接写个缓存刷新页面,上线时手工操作下;
2.数据量不大,可以在项目启动的时候自动进行加载;
3.定时刷新缓存;


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程