企业——Redis的高可用的搭建
一.Redis的哨兵机制
1.为什么要有哨兵机制?
哨兵机制的出现是为了解决主从复制的缺点的。Redis的哨兵(sentinel) 系统用于管理多个 Redis 服务器,该系统执行以下三个任务:
监控(Monitoring): 哨兵(sentinel) 会不断地检查你的Master和Slave是否运作正常。
提醒(Notification):当被监控的某个 Redis出现问题时, 哨兵(sentinel) 可以通过 API 向管理员或者其他应用程序发送通知。
自动故障迁移(Automatic failover):当一个Master不能正常工作时,哨兵(sentinel) 会开始一次自动故障迁移操作,它会将失效Master的其中一个Slave升级为新的Master, 并让失效Master的其他Slave改为复制新的Master; 当客户端试图连接失效的Master时,集群也会向客户端返回新Master的地址,使得集群可以使用Master代替失效Master。
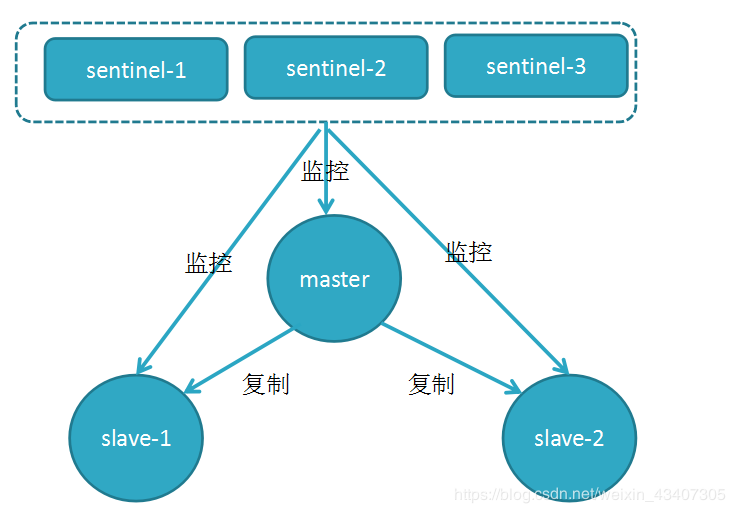
整个过程只需要一个哨兵节点来完成,首先使用Raft算法(选举算法)实现选举机制,选出一个哨兵节点来完成转移和通知。
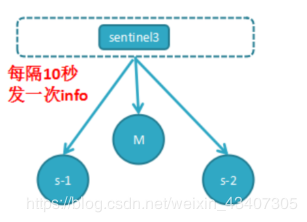
哨兵的定时监控任务
任务1:每个哨兵节点每10秒会向主节点和从节点发送info命令获取最拓扑结构图,哨兵配置时只要配置对主节点的监控即可,通过向主节点发送info,获取从节点的信息,并当有新的从节点加入时可以马上感知到
任务2:每个哨兵节点每隔2秒会向redis数据节点的指定频道上发送该哨兵节点对于主节点的判断以及当前哨兵节点的信息,同时每个哨兵节点也会订阅该频道,来了解其它哨兵节点的信息及对主节点的判断,其实就是通过消息publish和subscribe来完成的

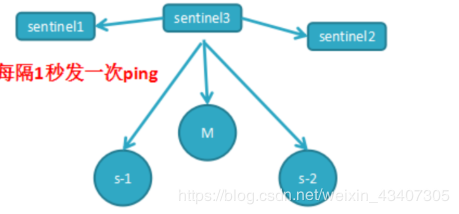
任务3:每隔1秒每个哨兵会向主节点、从节点及其余哨兵节点发送一次ping命令做一次心跳检测,这个也是哨兵用来判断节点是否正常的重要依据
哨兵的确认服务器down机的原理:
客观下线:当主观下线的节点是主节点时,此时该哨兵3节点会通过指令sentinel is-masterdown-by-addr寻求其它哨兵节点对主节点的判断,当超过quorum(选举)个数,此时哨兵节点则认为该主节点确实有问题,这样就客观下线了,大部分哨兵节点都同意下线操作,也就说是客观下线
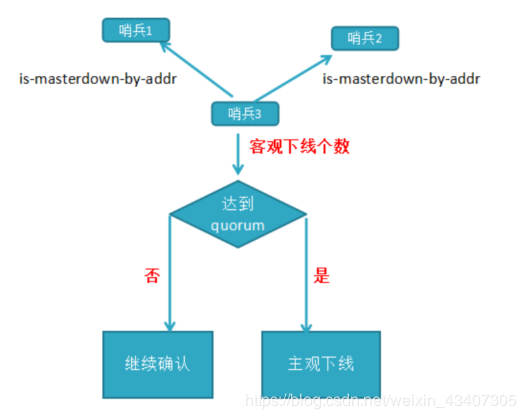
领导者哨兵选举流程:
a)每个在线的哨兵节点都可以成为领导者,当它确认(比如哨兵3)主节点下线时,会向其它哨兵发is-master-down-by-addr命令,征求判断并要求将自己设置为领导者,由领导者处理故障转移;
b)当其它哨兵收到此命令时,可以同意或者拒绝它成为领导者;
c)如果哨兵3发现自己在选举的票数大于等于num(sentinels)/2+1时,将成为领导者,如果没有超过,继续选举
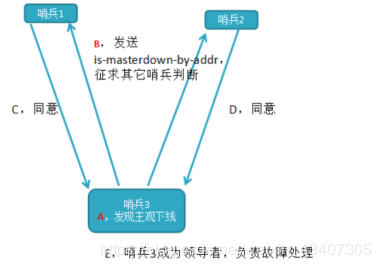
故障转移机制:
a)由Sentinel节点定期监控发现主节点是否出现了故障,sentinel会向master发送心跳PING来确认master是否存活,如果master在“一定时间范围”内不回应或者是回复了一个错误消息,那么这个sentinel会主观地(单方面地)认为这个master已经不可用了
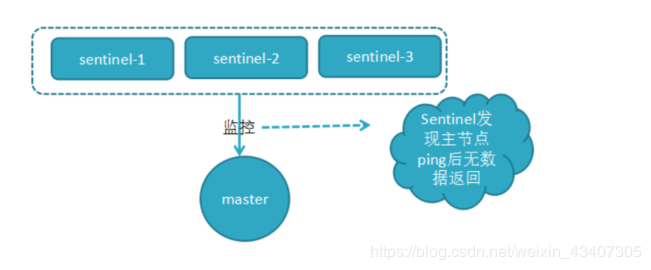
b) 当主节点出现故障,此时3个Sentinel节点共同选举了Sentinel3节点为领导,负载处理主节点的故障转移

c) 由Sentinel3领导者节点执行故障转移,过程和主从复制一样,但是自动执行
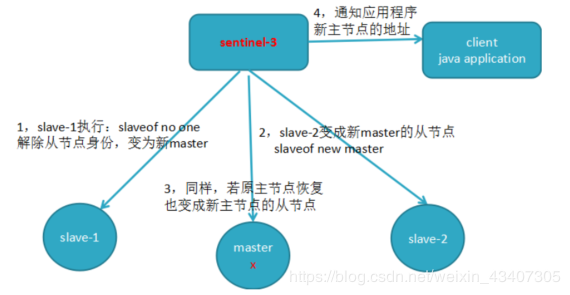
哨兵机制-故障转移详细流程-确认主节点
a) 过滤掉不健康的(下线或断线),没有回复过哨兵ping响应的从节点
b) 选择salve-priority从节点优先级最高(redis.conf)的
c) 选择复制偏移量最大,指复制最完整的从节点
二.Redis的高可用的配置
实验环境:
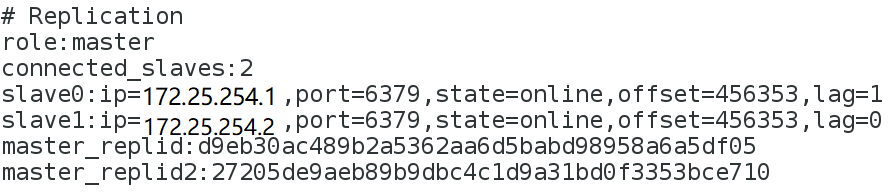
172.25.254.1 master/sentinel server1
172.25.254.2 slave/sentinel server2
172.25.254.3 slave/sentinel server3
172.25.254.4 client
1.server1(master),将 sentinel.conf复制到 /etc/redis/,并做相应编辑
cd redis-5.0.3
cp sentinel.conf /etc/redis/
cd /etc/redis/
ls
6379.conf sentinel.conf
vim sentinel.conf
protected-mode no ##关闭保护模式
sentinel monitor mymaster 172.25.254.1 6379 2 ##指定要监控的master,mymaster是定义的master名字,quorum为法定票数2,此处指的是sentinel的数,只有指定的sentinel同意时才认为sentinel做的决策是有效的,一般大于sentinel数量的半数。一组sentinel集群可以监控N个主从复制架构
sentinel down-after-milliseconds mymaster 10000 (这里设置的是10秒) ##至少多长时间连不上才认为master离线了。单位为ms, 即连接超时时长
sentinel parallel-syncs mymaster 1 ##刚刚设定为新主时,允许同时有多少个从向主发起同步请求。
sentinel failover-timeout mymaster 180000 ##当master故障时,把slave提升为新的master,多长时间提不上就认为故障转移失败。
2.将写好的配置文件发到两个slave上的/etc/redis下
scp sentinel.conf root@172.25.254.2:/etc/redis/
scp sentinel.conf root@172.25.254.3:/etc/redis/
3.查看master和slave的状态是否良好
4.开启sentinel服务
redis-server /etc/redis/sentinel.conf --sentinel 或者 redis-sentinel /etc/redis/sentinel.conf &
5.测试
手动将master down掉
redis cli
SHUTDOWN
EXIT
查看状态,哨兵起作用了,显示slave接替原来的master任务。
查看server3(我的测试是将server3提升为新的master)

查看另一个slave上的信息
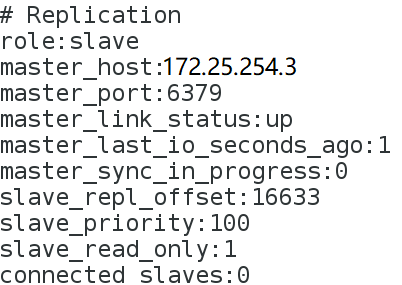
把server1的redis服务重新开启,它会自动的成为server3的slave
![]()