NLP-word2vec
参考:
https://blog.csdn.net/qq_29678299/article/details/92403395
https://blog.csdn.net/Jiajikang_jjk/article/details/101154395
https://github.com/jiajikang-nlp/NLP-related-algorithm-learning/tree/master/%5B3%5DNLP%20related%20algorithm%20learning
下载wiki中文语料(大约1.7G)https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2
下载的文件名为“zhwiki-latest-pages-articles.xml.bz2”

文本预处理 data_pre_process.py
# -*- coding: utf-8 -*- # 中文语料预处理 from gensim.corpora import WikiCorpus import jieba from langconv import * def my_function(): space = ' ' i = 0 l = [] zhwiki_name = './data/zhwiki-latest-pages-articles.xml.bz2' f = open('./data/reduce_zhiwiki.txt', 'w',encoding='utf-8') # wiki = WikiCorpus(zhwiki_name, lemmatize=False, dictionary={}) wiki = WikiCorpus(zhwiki_name, dictionary={}) for text in wiki.get_texts(): for temp_sentence in text: temp_sentence = Converter('zh-hans').convert(temp_sentence) seg_list = list(jieba.cut(temp_sentence)) for temp_term in seg_list: l.append(temp_term) f.write(space.join(l) + "\n") l = [] i = i + 1 if(i % 200 == 0): print('Saved ' + str(i) + "articles") f.close() if __name__ == '__main__': my_function()
4个半小时训练完成(本机)

# 文件的操作模式有:
# 1. r模式: 以字符串的方式读取文件中的数据
# 2. w模式:以字符串的方式往文件中写入数据
# 3. a模式: 以字符串的方式往文件末尾追加写入数据
# 4. rb模式:以字节(二进制)方式读取文件中的数据
# 5. wb模式: 以字节(二进制)方式往文件中写入数据
# 6. ab模式: 以字节(二进制)方式往文件末尾追加写入数据
word2vec训练代码:一直有utf-8报错,在open文件时添加了errors='ignore'
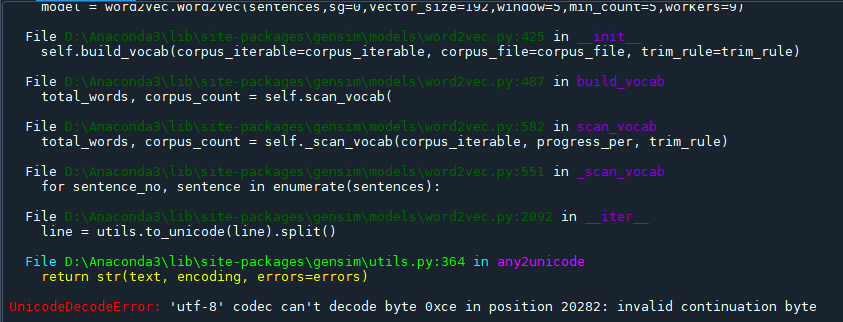
# 使用gensim模块训练词向量: from gensim.models import Word2Vec from gensim.models import word2vec from gensim.models.word2vec import LineSentence from gensim.test.utils import datapath import logging # 记录日志 try: import cPickle as pickle except ImportError as e: import pickle logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO) # 基本信息 def my_function(): wiki_news = open('./data/reduce_zhiwiki.txt','r',encoding='utf-8',errors='ignore') # 打开中文语料文件 # print(wiki_news.readline()) # sg=表示使用CBOW模型训练词向量;sg=1表示利用Skip-gram训练词向量。 # 参数size表示词向量的维度。 # windows表示当前词和预测词可能的最大距离,其中windows越大所需要枚举的预测此越多,计算时间就越长。 # min_count表示最小出现的次数。 # workers表示训练词向量时使用的线程数。 sentences = LineSentence(wiki_news) # 为要训练的txt的路径 print(sentences) # model = Word2Vec('E:/1-PythonTest2022/word2Vec/data/reduce_zhiwiki.txt',sg=0,vector_size=192,window=5,min_count=5,workers=9) print('训练~~~') model = word2vec.Word2Vec(sentences,sg=0,vector_size=192,window=5,min_count=5,workers=9) model.save('./data/zhiwiki_news.pkl')# model_path为模型路径。保存模型,通常采用pkl形式保存,以便下次直接加载即可 model.save('./data/zhiwiki_news.word2vec') if __name__ == '__main__': my_function() print('训练结束')
得到模型:zhiwiki_news.word2vec


 浙公网安备 33010602011771号
浙公网安备 33010602011771号