20210708-学习记录
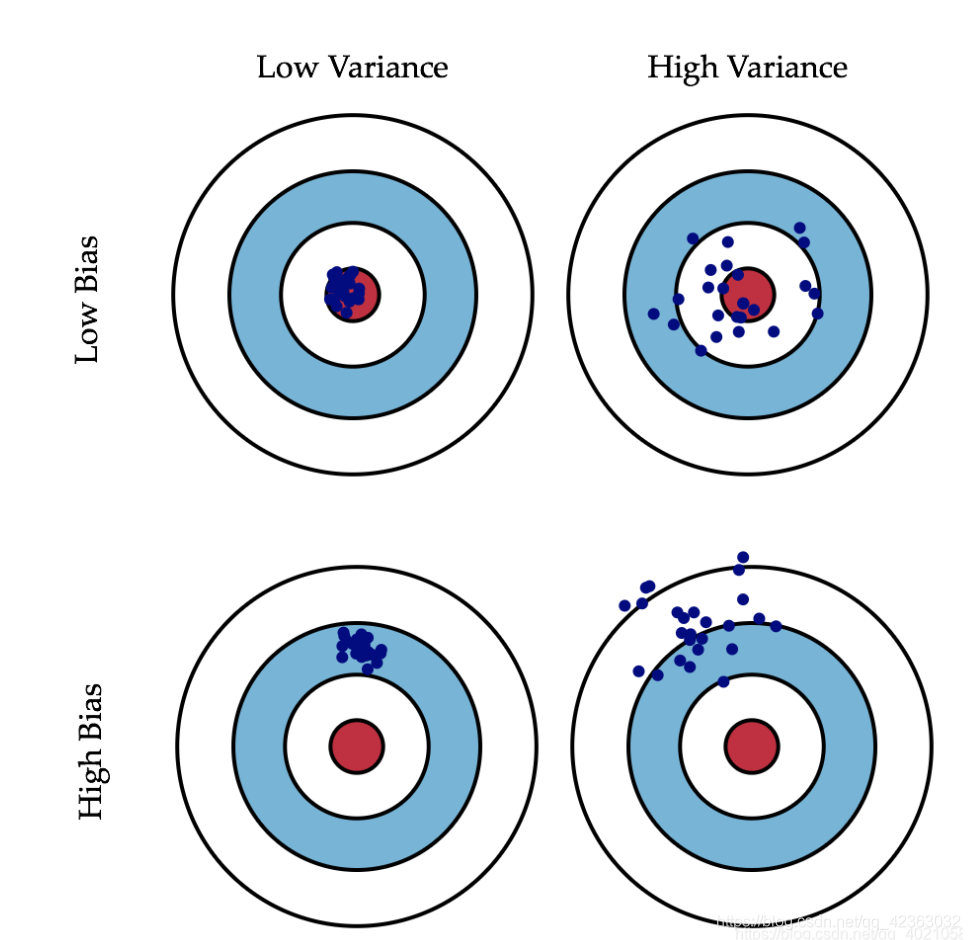
左下角这幅图,箭完全偏离了靶心,这种情况叫做偏差。右上角这幅图,箭随机分布在靶心周围,这叫方差。可以把靶心看作模型的预测目标,箭看作模型的预测值,模型的预测结果也同样会出现偏差和方差两种情况。
一个模型的误差通常来源于三种情况:
模型误差=偏差+方差+不可避免误差
不可避免误差往往是无法消除的,例如环境噪声等。
造成偏差与方差的原因
偏差的出现往往是模型本身有问题,例如我们的要拟合一个二次函数,但是预测模型为一个一次函数,预测结果就会出现偏差。
方差的体现一般在输入数据的一个细微扰动就会得到不同的输出结果,通俗的来说模型可能连输入数据里的噪声也一起学到了,所以测试数据与训练数据分布稍有不同预测结果就会有较大差异。
参数化算法对数据进行参数化,形成很多的特征,这种方法训练速度非常快,而且也不需要很多的数据,但是他不是很灵活。这些方法通常都是高偏差的,例如逻辑回归
非参数化算法对目标函数做出很少或者根本不做任何假设,但是它需要更多的数据,训练速度非常慢,模型复杂度非常高,但是模型非常强大。这些方法通常都是高方差的,例如KNN、决策树
如何平衡偏差与方差
在上面的例子中我们可以看到一个趋势:参数或者线性的机器学习算法一般都会有一个很高的偏差和一个很低的方差。但是,非参数或者非线性的机器学习算法一般都有一个很低的偏差和一个很高的方差。所有,我们需要在这两者之间找到一个平衡点,来优化我们的算法。想要获得低方差和低偏差是矛盾的,我们只能对他们做一个平衡。
比如,KNN 算法有很低的偏差和很高的方差,但是我们可以通过调整 k 的值来改变偏差和方差之间的权衡关系,从而达到一个比较平衡的状态。
在机器学习领域,主要的挑战来自方差,当然主要是在算法方面,实际问题中原因不尽相同
解决高方差的通常手段:
1.降低模型复杂度
2.减少数据维度;降噪
3.增加样本数
4.使用验证集
5.模型正则化
原文链接:https://blog.csdn.net/qq_42363032/article/details/108311310

 浙公网安备 33010602011771号
浙公网安备 33010602011771号