BP神经网络+ GAN
最近回顾了一下机器学习的几大算法,三部分内容:误差反向传播算法的过程和生成对抗网络这两块内容的基本思想,和一些具体实现。
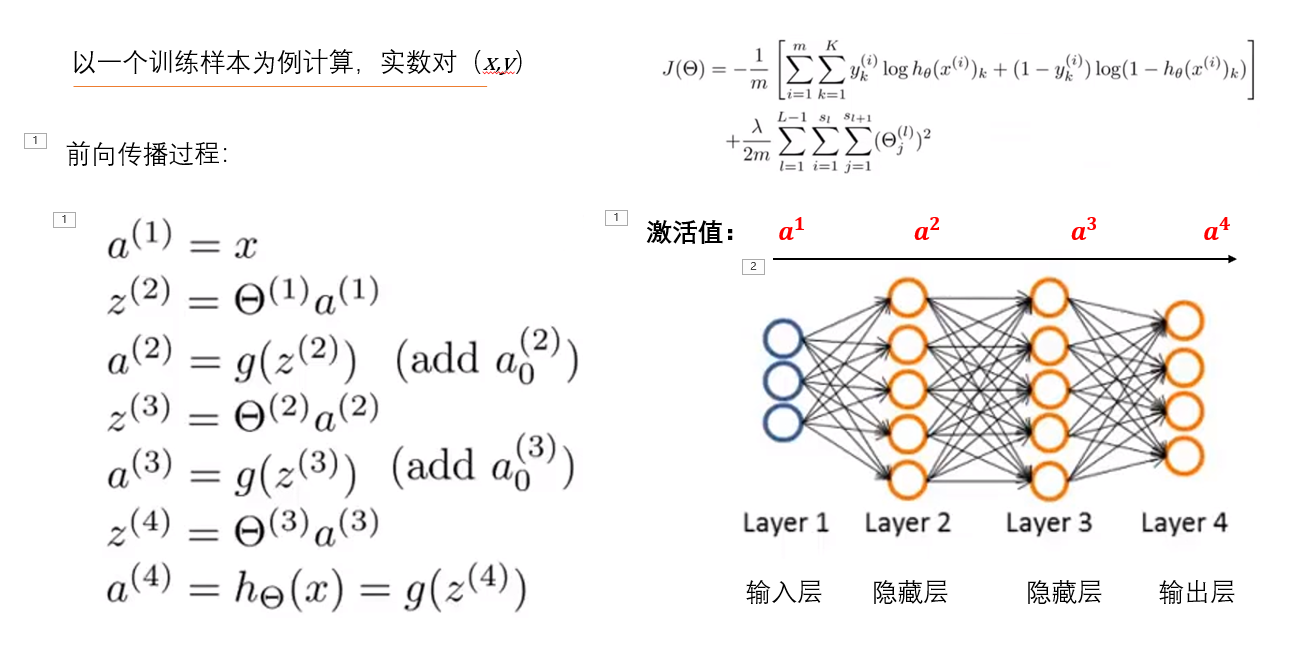
BP神经网络是一种多层的前馈神经网络,其主要的特点是:信号是前向传播的,而误差是反向传播的。
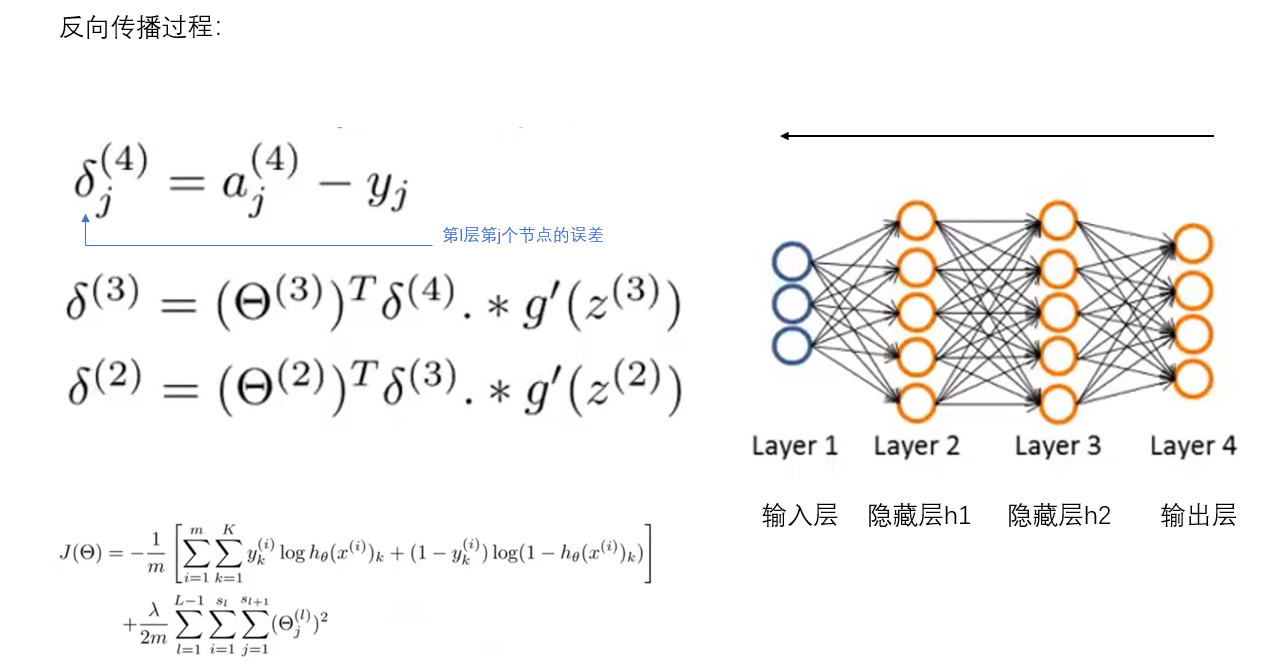
BP算法(梯度下降法+导数链式法则)实现的,它可以理解为一种最优化损失函数过程,求解每个参与运算的参数的梯度,不断地更新参数,直到损失函数最小,达到局部或者全局最优值。
反向传播算法的过程根据损失函数,求出损失函数关于每一层的权值w及偏置项b的偏导数,这个偏导数也就是我们所说的梯度。
首先和BP对应的是前向传播,a指的是激活值,也就是每一层的输出值,g函数用到了sigmoid函数,这个函数输出结果都是大于0的,最后一步A4也就是假设函数的输出结果,得到的是预测值,他的过程是从左到右;下面是反向传播算法的过程,要计算的就是&,表示的是第L层第j个节点的误差,y是真实值,依次计算,注意的是&到2为止,因为第一项输入的是x是真实值,所以不会存在误差。
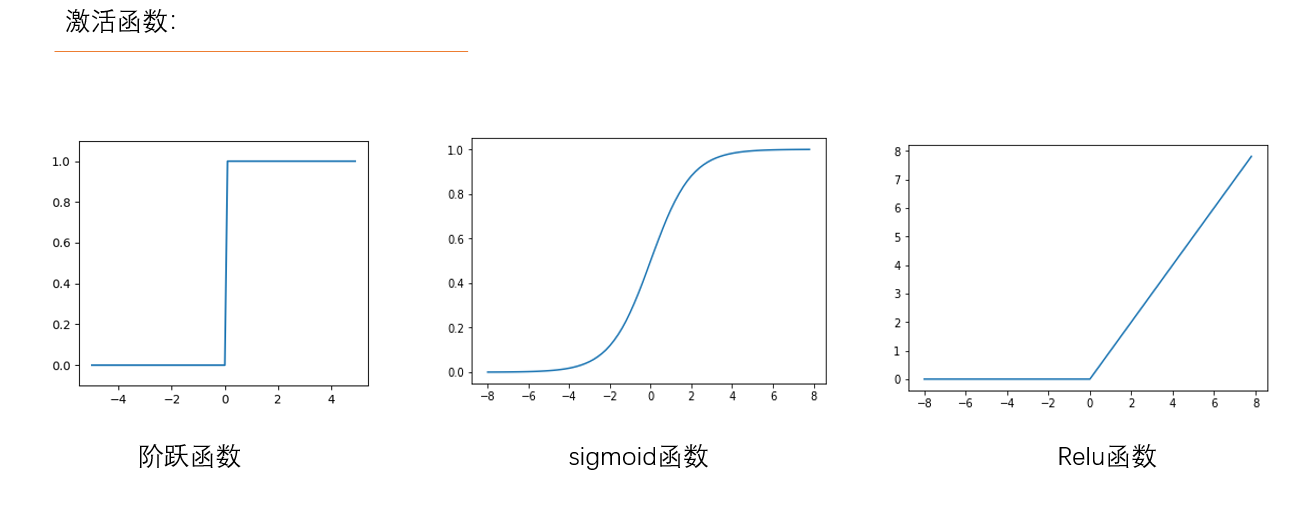
Relu函数能让输入是负数的神经元输出0,也就是在网络中没有激活这一类神经元,从而导致稀疏,不会轻易出现过拟合现象,计算的时候也有更高的效率了。
有一组数据目的是训练这两组数据,找到输入X计算得到Y的预测值尽可能接近于真实值的参数。设定模型:设计一个隐藏层为1,隐藏单元数为2,激活函数为sigmod函数的模型,运用反向传播算法,得到参数。初始权重可以随机生成也可以自己设定,对后续的影响不会很大
5)重复步骤2-4,直到损失值达到了预先设定的阈值或迭代次数用完,得到最终的权值。


GAN
生成模型目前最长用的三种方法有:像素神经网络、变分自编码器、生成对抗网络。
详细说一下生成对抗网络。
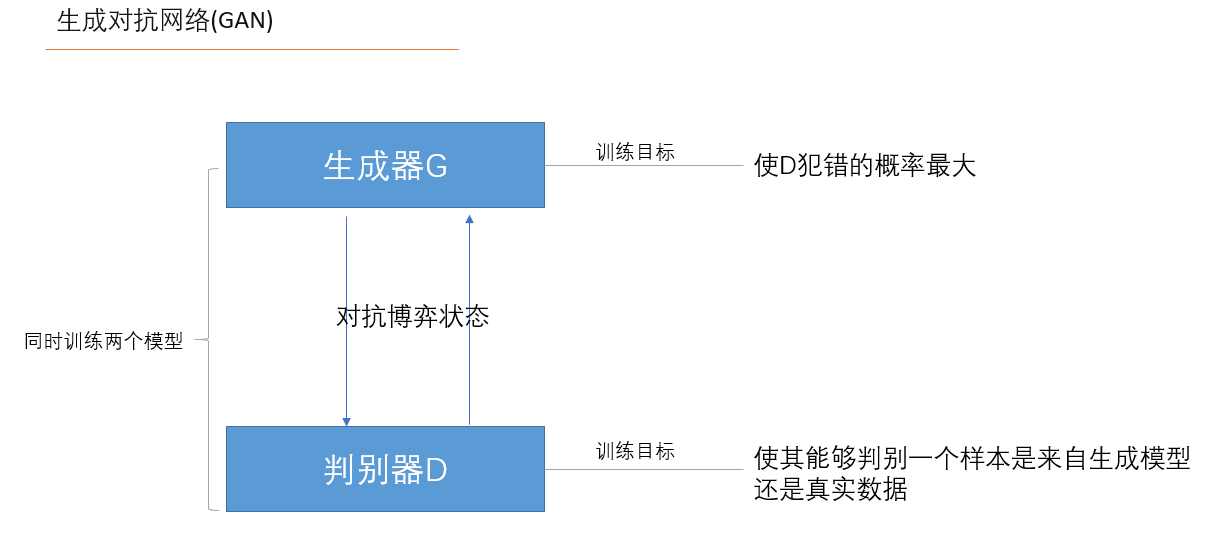
同时训练两个模型:生成模型G和判别模型D。对G的训练的目标是 使得D犯错的概率最大。对D的训练目标是使得其能够判别一个样本是来自生成模型还是真实数据。文中作者做了一个比喻,生成模型G存在一个对手,即判别模型D,可将G类比为一个伪造货币的团队,他们试图生产假的货币,并且使用这些货币而不被警察发现,而D则可类比为警察,他们要查出这些伪造的货币。最后的竞争结果直到伪造者(G)造出警察(D)无法判别真假的货币为止。
以手写数字为例,假如现在拥有大量的手写数字的数据集,希望通过GAN生成一些能够以假乱真的手写字图片。主要由如下两个部分组成:
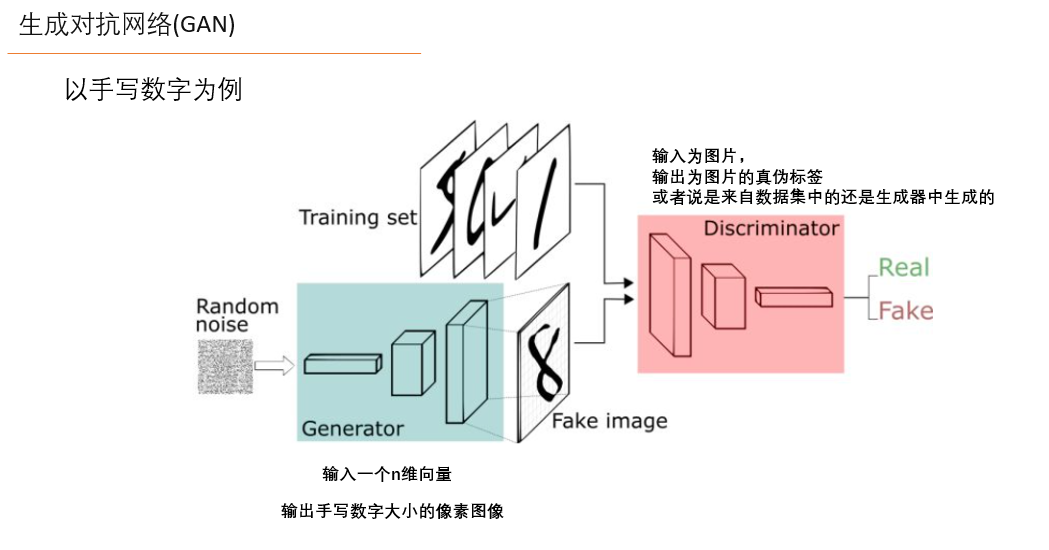
- 定义一个模型来作为生成器(图三中蓝色部分Generator),能够输入一个向量,输出手写数字大小的像素图像。
- 定义一个分类器来作为判别器(图三中红色部分Discriminator)用来判别图片是真的还是假的(或者说是来自数据集中的还是生成器中生成的),输入为手写图片,输出为判别图片的标签;
已经定义好了一个生成器(Generator)来生成手写数字,一个判别器(Discrimnator)来判别手写数字是否是真实的,和一些真实的手写数字数据集。下面是训练的过程:



交叉熵一般在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。在当前模型的情况下,判别器为一个二分类问题,因此可以对基本交叉熵进行更具体地展开如下图7所示:




 浙公网安备 33010602011771号
浙公网安备 33010602011771号