Transformer 源码中 Mask 机制的实现
训练过程中的 Mask实现
mask 机制的原理是, 在 decoder 端, 做 self-Attention 的时候, 不能 Attention 还未被预测的单词, 预测的信息是基于encoder 与以及预测出的单词. 而在 encoder 阶段的, Self_Attention 却没有这个机制, 因为encoder 的self-Attention 是对句子中的所有单词 Attention ,mask 本质是对于 Attention 来说的, 所以我们来看下 Attention 的实现:
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# 这里是对应公式的 Q* K的转秩矩阵
"""
Queries张量,形状为[B, H, L_q, D_q]
Keys张量,形状为[B, H, L_k, D_k]
Values张量,形状为[B, H, L_v, D_v],一般来说就是k
"""
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
我们知道, 在训练的时候, 我们是以 batch_size 为单位的, 那么就会有 padding, 一般我们取 pad == 0, 那么就会造成在 Attention 的时候, query 的值为 0, query 的值为 0, 所以我们计算的对应的 scores 的值也是 0, 那么就会导致 softmax 很可能分配给该单词一个相对不是很小的比例, 因此, 我们将 pad 对应的 score 取值为负无穷, 以此来减小 pad 的影响. 也就是上面中 scores = scores.masked_fill(mask == 0, -1e9) 的意思. 需要注意的是, 这一步在 Query 与 Key 相乘之后, 在 Softmax 之前, 所以本质上, decoder 的Self-Attention 的内部, Target 句子, 是会和 Encoder-Output 做 Self-Attention 的乘积的, 但是, 这个结果 Attention 的结果, 我们只取前面一部分, 取一部分的方法就是这里的 mask. 我们可以用下面这张图来表示:
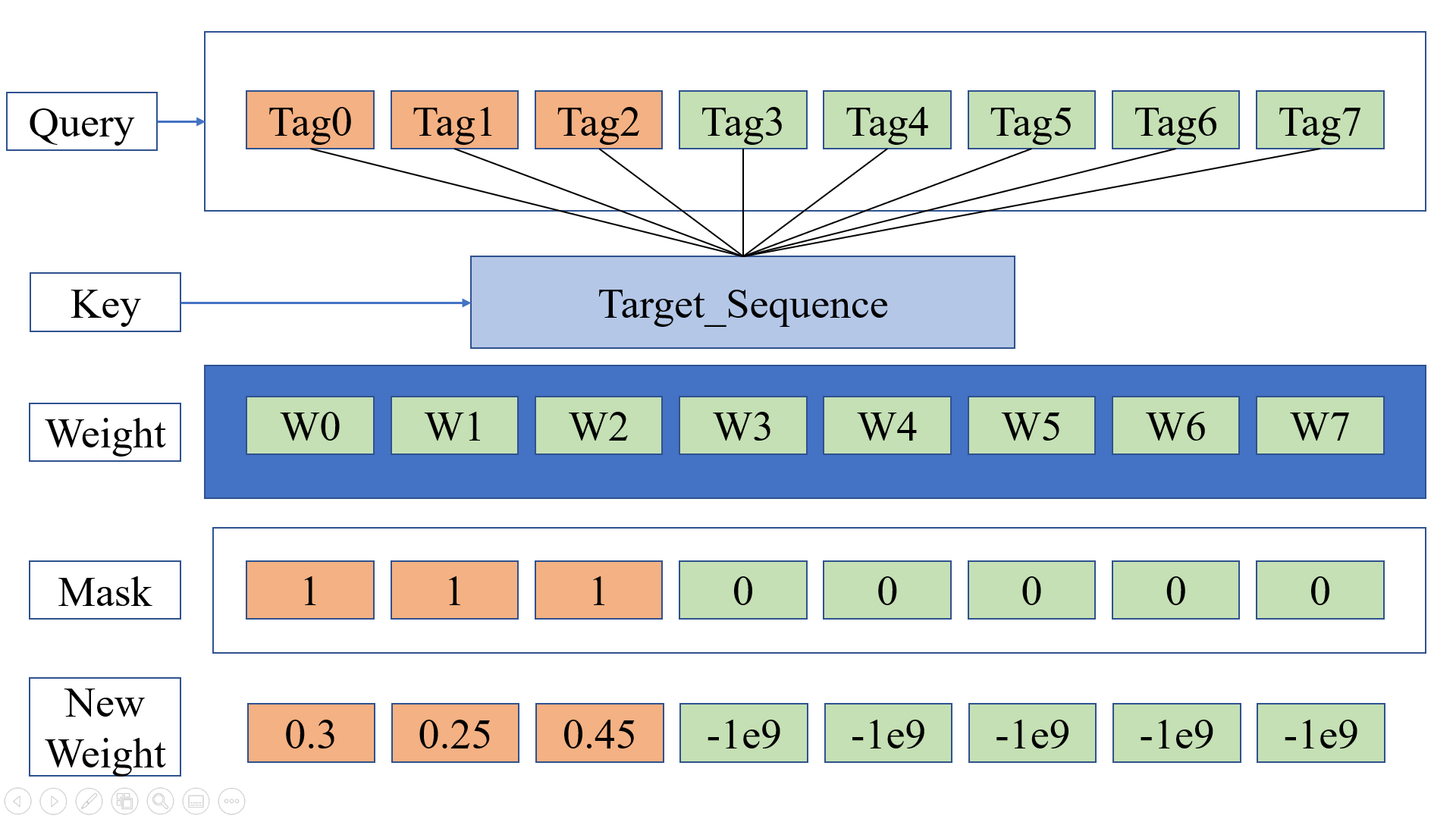
也就是说, 在 decoder, 未预测的单词也是用 padding 的方式加入到 batch 的(注意 Padding 其实就是通过mask 01矩阵实现的), 所以使用的mask 机制与 padding 时mask 的机制是相同的, 本质上都是query在做Attention之后的值为设为最小值, 只是 mask 矩阵不同, 如上图所示, decoder 在先自身做完 self_Attention 之后, 未被预测的单词的权重是最小值, 那么输出就是 0.
我们可以根据 decoder forward部分的代码发现这一点.
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def forward(self, x, memory, src_mask, tgt_mask):
"Follow Figure 1 (right) for connections."
m = memory
# 目标语言的self_Attention, 这里 mask的作用就是用到上面所说的 softmax 之前的部分
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
# 这里使用的是 Self-Attention 机制,其实 m 是encoder的输出,x是decoder第一部分的输出,
# 因为上面一部分的输出中, 未被预测的单词的 query 其实是 0(padding), 那么在这里可以直接使用 src_mask
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
# 最后是两个线形层,
return self.sublayer[2](x, self.feed_forward)
接下来我们来追溯一下, 这里的 mask 是怎么来的, 我们最终构建的模块是 Encoder_Decoder,
class EncoderDecoder(nn.Module):
"""
A standard Encoder-Decoder architecture. Base for this and many
other models.
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
# 将源语言的单词 embedding 放在一起, position embedding
self.tgt_embed = tgt_embed
# 将目标语言的单词 embedding 放在一起, position embedding
self.generator = generator
# 就是最后产生结果的地方
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
我们在训练的时候, 使用的是 model.forward, 这一部分在:
def run_epoch(args, data_iter, model, loss_compute, valid_params=None, epoch_num=0,
is_valid=False, is_test=False, logger=None):
"Standard Training and Logging Function"
start = time.time()
total_tokens = 0
total_loss = 0
tokens = 0
if valid_params is not None:
src_dict, tgt_dict, valid_iter = valid_params
hist_valid_scores = []
bleu_all = 0
count_all = 0
for i, batch in enumerate(data_iter):
model.train()
out = model.forward(batch.src, batch.trg ,batch.src_mask, batch.trg_mask)
# 参数来自 batch
loss = loss_compute(out, batch.trg_y, batch.ntokens)
# 这一步既计算了损失, 又更新了参数
total_loss += loss
total_tokens += batch.ntokens
tokens += batch.ntokens
这些都是训练的步骤, 数据是怎么来的, mask 矩阵来自 batch, 所以最关键的是 batch 是怎么来的, 再往回找在 train.py函数中, 我们发现
_, logger_file = train_utils.run_epoch(args, (train_utils.rebatch(pad_idx, b) for b in train_iter),
model_parallel if args.multi_gpu else model, train_loss_fn,
valid_params=valid_params,
epoch_num=epoch, logger=logger_file)
batch 是来自 rebatch 函数, 以及训练数据的迭代器, 这个train_iter 是根据 torchtext 得到, 这里就不赘述了, 所以关键就是下面的 rebatch 函数,
def rebatch(pad_idx, batch):
"Fix order in torchtext"
src, trg = batch.src.transpose(0, 1), batch.trg.transpose(0, 1)
# 读的数据是 sequence * batch_size 维度, 是在torchtext 中的Filed 决定的
# 所以需要转换为 bacth * sequence
return Batch(src, trg, pad_idx)
最后终于找到了 Batch 类, 最关键的信息来自这里:
class Batch:
"Object for holding a batch of data with mask during training."
def __init__(self, src, trg=None, pad=0):
self.src = src
self.src_mask = (src != pad).unsqueeze(-2)
# 在预测的时候是没有 tgt 的,此时为 None
if trg is not None:
self.trg = trg[:, :-1]
# 每次迭代的时候, 去掉最后一个单词
self.trg_y = trg[:, 1:]
# 去掉第一个单词
self.trg_mask = self.make_std_mask(self.trg, pad)
self.ntokens = (self.trg_y != pad).sum().item()
# target 语言中单词的个数
@staticmethod
def make_std_mask(tgt, pad):
"Create a mask to hide padding and future words."
tgt_mask = (tgt != pad).unsqueeze(-2)
tgt_mask = tgt_mask & transformer.subsequent_mask(tgt.size(-1)).type_as(tgt_mask)
# tgt.size(-1) 表示的是序列的长度
return tgt_mask
在 class Batch 中, trg 为 None 的时候很好理解, 也就是在预测的时候, 是没有目标语言的, 其实在预测的时候, 只有输入的 Batch , 那么 预测过程的 Attention Mask 又是如何实现的呢? 这个我们放在后面再说, 先看这里的src_mask, 源语言的 mask, 也就是 encoder 时的self_Attention 时的mask, 这个很好理解, 就是将非 0 的数字变成 1, 获得一个 0/1 矩阵, self.trg = trg[:, :-1] 这里去掉的最后一个单词, 不是真正的单词, 而是标志 '<eos>' , 输入与输出都还有一个 '<sos>' 在句子的开头, self.trg_y = trg[:, 1:] 去掉开头就变成了最后的结果. 接下来就是最关键的获取 target 语言的 mask 矩阵,
def subsequent_mask(size):
"Mask out subsequent positions."
attn_shape = (1, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
return torch.from_numpy(subsequent_mask) == 0
这个函数干了啥呢?
我们先写成这样:
def subsequentmask(size):
"Mask out subsequent positions."
attn_shape = (1, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
return subsequent_mask == 0
print(subsequentmask(5))
>>
[[[ True False False False False]
[ True True False False False]
[ True True True False False]
[ True True True True False]
[ True True True True True]]]
当这个 numpy 数组转化为tensor 的时候, 构成的是维度为 (1, 5, 5) 的矩阵. 我们注意到, self.src_mask = (src != pad).unsqueeze(-2) 也就是说, 源语言的 mask 矩阵的维度是 (batch_size, 1, length), 那么为什么 attn_shape = (batch_size, size, size) 呢? 可以这么解释, 在 encoder 阶段的 Self_Attention 阶段, 所有的 Attention 是可以同时进行的, 把所有的 Attention_result 算出来, 然后用同一个 mask vector * Attention_result 就可以了, 但是在 decoder 阶段却不能这么做, 我们需要关注的问题是:
根据已经预测出来的单词预测下面的单词, 这一过程是序列的,
而我们的计算是并行的, 所以这一过程中, 必须要引入矩阵. 也就是上面的 subsequent_mask() 函数获得的矩阵.
这个矩阵也很形象, 分别表示已经预测的单词的个数为, 1, 2, 3, 4, 5.
然后我们将以上过程反过来过一遍, 就很明显了, 在 batch阶段获得 mask 矩阵, 然后和 batch 一起训练, 在 encoder 与 deocder 阶段实现 mask 机制.
预测过程中的 Mask实现
我们直接来看预测过程中的 decoder 的实现,
def greedy_decode(model, src, src_mask, max_len, start_symbol):
memory = model.encode(src, src_mask)
# memory 是 encoder 的中间结果
batch_size = src.shape[0]
ys = torch.ones(batch_size, 1).fill_(start_symbol).type_as(src)
# 预测句子的初始化
for i in range(max_len-1):
out = model.decode(memory, src_mask, ys, transformer.subsequent_mask(ys.size(1)).type_as(src))
# ys 的维度是 batch_size * times, 所以target_mask 矩阵必须是 times * times
# 根据 decoder 的训练步骤, 这里的 out 输出就应该是 batch_size * (times+1) 的矩阵
prob = model.generator(out[:, -1])
# out[:, -1] 这里是最新的一个单词的 embedding 向量
# generator 就是产生最后的 vocabulary 的概率, 是一个全连接层
_, next_word = torch.max(prob, dim = 1)
# 返回每一行的最大值, 并且会返回索引
next_word = next_word.unsqueeze(1)
ys = torch.cat([ys, next_word.type_as(src)], dim=1)
# 将句子拼接起来
return ys
上面代码的 transformer.subsequent_mask(ys.size(1)).type_as(src) 这一部分就很好的解释了 target_mask 矩阵的构造方法, 在这里, 输入不是像训练时候一样, 是整个的目标语言的句子, 而是已经训练的句子的集合, 这里的 decode 的步骤不仅仅是预测了最后一个单词, 同时, 前面所有的单词都进行了预测, 只是预测的结果和上次是一样的. 这里在多说一点, 在预测的时候,

 浙公网安备 33010602011771号
浙公网安备 33010602011771号