
线程池基本概念
1、为什么要使用线程池?
反复创建线程系统开销比较大,而且每个线程的创建和销毁都需要时间,
如果任务比较简单,那么有可能导致线程的创建和销毁占用的资源超过执行任务所消耗的资源.
如果当要执行的任务比较多时,每个线程负责一个任务,那么需要创建很多线程去执行任务,过多的线程会占用过多的内存资源等,还会带来上下文切换,同时还会导致系统不稳定.
线程池好处
线程池解决了线程生命周期的系统开销问题,
线程池中的线程可以反复使用,可以用少量的线程去执行大量的任务,减少了线程创建和销毁的开销,而且线程都是创建好的,来任务就可以执行.
通过设置合适的线程池的线程数,可以避免资源使用不当,线程池可以通过线程数和任务灵活的控制线程数量,任务多的时候可以继续创建线程,任务少的时候只保留核心线程,这样可以避免系统资源浪费和线程过多导致内存溢出.
线程池可以统一管理资源,通过线程书和任务队列,可以统一开始和结束,并设置相关的拒绝策略.
2、线程池的七个参数
- corePoolSize:核心线程数,常驻线程池的线程数量
- maxPoolSize:线程池最大线程数量,当任务特别多的时候,corePoolSize线程数量无法满足需求的时候,就会继续创建线程,最大不超过maxPoolSize.
- KeepAliveTime+时间单位:空闲线程的存活时间
- ThreadFactory:线程工厂,用来创建线程
- WorkQueue:任务队列,用来存放任务
- Handler:处理被拒绝的策略
3、 线程池处理任务流程图
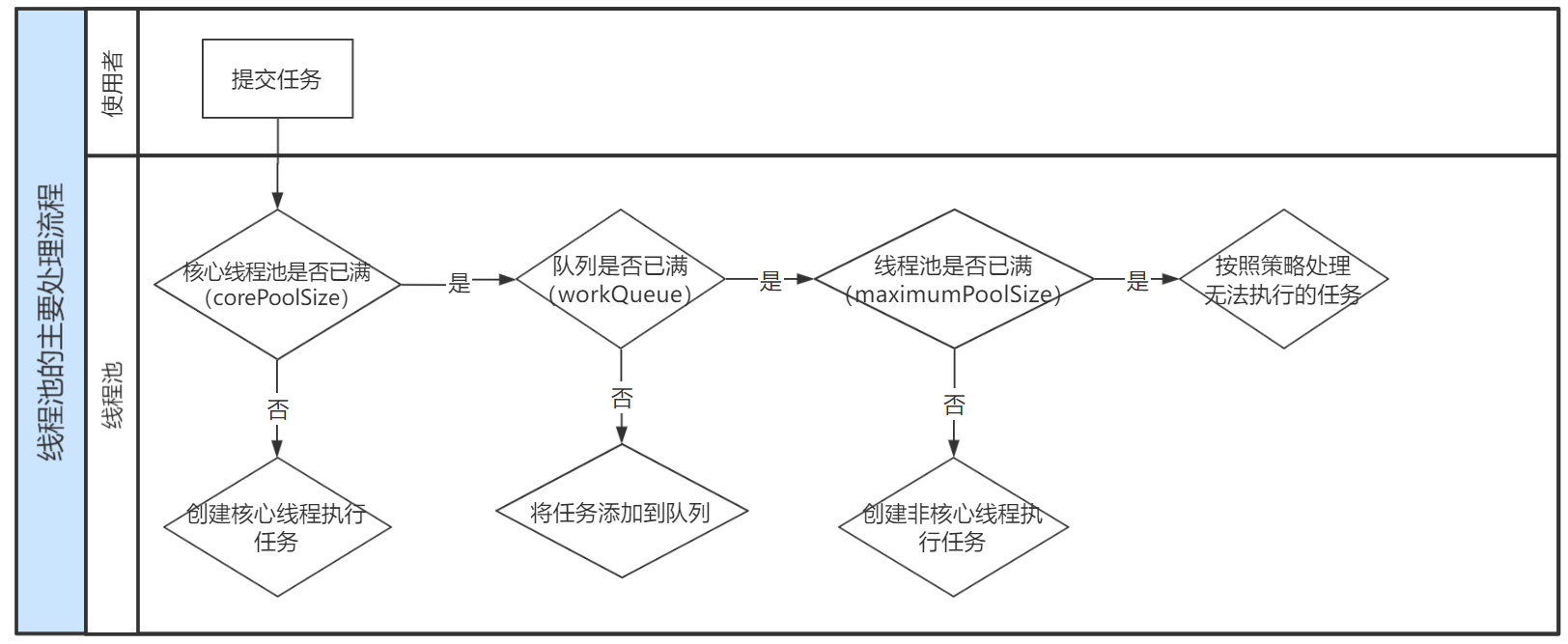
(1) 当提交任务后,线程池首先会检查当前线程数,如果当前线程数小于核心线程数,则新建线程并执行任务.
(2) 随着任务不断增加,线程数达到了核心线程数的数量,此时任务依然在增加,那么新来的任务将会放到workQueue等待队列中,等核心线程执行完任务后重新从队列中提取出等待被执行的任务
(3) 如果已经达到了核心线程数,且任务队列也满了,则线程池就会继续创建线程来执行任务,如果任务不断提交,线程池会持续创建线程直到达到maximumPoolSize最大线程数,
(4) 当达到了最大线程数后,任务仍不断提交,那么此时就超过了线程池的最大处理能力,这个时候线程池就会拒绝处理这些任务,处理策略就是handler.
4、参数分析
corePoolSize和maximumPoolSize:
线程池初始化时,默认的线程数是0,当有任务提交后,开始创建核心线程去执行任务,当线程数达到核心线程数时且任务队列满了后,开始创建非核心线程执行任务,最大可以达到maximumPoolSize,如果这是任务不提交了,线程开始空闲,那么默认情况下大于corePoolSize的线程在超过设置的KeepAliveTime时间后会被合理的收回,所以默认情况下,线程池中的线程数量处于corePoolSize和maximumPoolSize之间.
KeepAliveTime+时间单位:
默认情况下,当线程池中的数量多于核心线程数时,而此时有没有任务可做,那么线程池就会检测线程的KeepAliveTime,如果超过了规定的时间,则无事可做的线程就会被销毁,以便减少内存的占用和资源消耗,如果后期任务又多了起来,则线程池根据规则重新创建线程,通过这个可伸缩的功能,可以实现对资源的合理使用,我们可以通过setKeepAliveTime设置keepAliveTime时间,还可以通过设置allowCoreThreadTimeOut参数,这个参数默认是false,如果设置成ture,则会给核心线程数设置超时等待时间, 如果超过时间了核心线程就会销毁.
ThreadFactory:
ThreadFactory是一个线程工厂,负责生产线程去执行任务,默认的线程工厂,创建的线程会在同一个线程组,并且拥有一样的优先级,且都不是守护线程,我们也可自定义线程工厂,以便给线程自定义名字.
workQueue:
阻塞队列,用来存放任务,我们主要分析一下5种阻塞队列:
- ArrayBlockingQueue是基于数组的有界阻塞队列,按照FIFO排序,新来的队列会放到队列尾部,有界的数组可以防止资源被耗尽问题,当线程达到了核心线程数,再来任务的时候就放到队列的尾部,当队列满了的时候,则继续创建非核心线程,如果线程数量达到了maxPoolSize,则会执行拒绝策略.
- LinkedBlockingQueue是基于链表的无界阻塞队列(最大容量是Integer.MAX),按照FIFO排序,当线程池中线程数量达到核心线程数时,继续来了新任务会一直存放到队列中,而不会创建新线程.因此使用此队列时,maxPoolSize是不起做的
- SynchronousQueue是一个不缓存任务的阻塞队列,当来了新任务的时候,不会缓存到队列中,而是直接被线程执行该任务,如果没有核心线程可用就创建新线程去执行任务,达到了maxPoolSize时,就执行拒绝策略.
- PriorityBlockingQueue是一个具有优先级的无界阻塞队列,优先级通过参数Comparator实现
- DelayedWorkQueu队列的特点是内部的任务并不是按照放入的时间排序,而是会按照延迟的时间长短对任务进行排序,内部采用的是“堆”数据结构.而且它也是一个无界队列.
handler:
拒绝策略是当线程池中任务达到了队列最大容量,且线程数量也达到了最大maxPoolSize的时候,如果继续有新任务来了,则执行这个拒绝策略来处理新来的任务,jdk提供4种拒绝策略,它们都实现了RejectedExecutionHandler接口:
CallRunsPolicy:该策略下,在调用者线程中直接执行被拒绝任务的run方法,就是谁提交的任务,谁负责执行任务,这样任务不会丢失,而且执行任务比较费时,那么提交任务的线程也会被占用,就可以减缓任务提交速度.
- AbortPolicy:该策略下,直接抛弃任务,并抛RejectedExecutionException异常.
- DiscardPolicy:该策略下,直接抛弃任务.
- DiscardOldestPolicy:该策略下,抛弃最早进入队列中的那个任务,然后尝试把这次拒绝的任务放入队列.
除此之外,我们还可以通过实现 RejectedExecutionHandler 接口来实现自己的拒绝策略,在接口中我们需要实现rejectedExecution方法,在rejectedExecution方法中,执行例如暂存任务、重新执行等自定义拒绝策略.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号