
故障集,更新中……
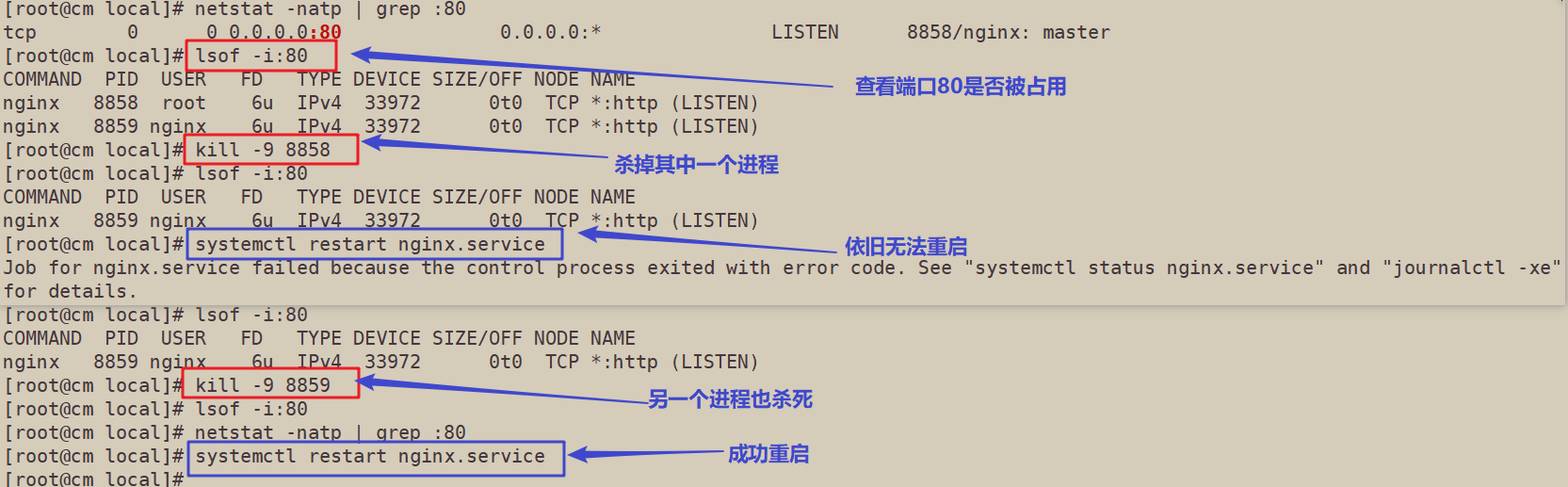
一、nginx无法重启,显示端口已被占用
nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address already in use)
[root@cm local]# netstat -natp | grep :80 tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 8858/nginx: master [root@cm local]# lsof -i:80 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME nginx 8858 root 6u IPv4 33972 0t0 TCP *:http (LISTEN) nginx 8859 nginx 6u IPv4 33972 0t0 TCP *:http (LISTEN) [root@cm local]# kill -9 8858 [root@cm local]# lsof -i:80 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME nginx 8859 nginx 6u IPv4 33972 0t0 TCP *:http (LISTEN) [root@cm local]# systemctl restart nginx.service Job for nginx.service failed because the control process exited with error code. See "systemctl status nginx.service" and "journalctl -xe" for details. [root@cm local]# systemctl status nginx.service ● nginx.service - nginx Loaded: loaded (/usr/lib/systemd/system/nginx.service; enabled; vendor preset: disabled) Active: failed (Result: exit-code) since 三 2021-08-18 12:15:23 CST; 12s ago Process: 13254 ExecStart=/usr/local/nginx/sbin/nginx (code=exited, status=1/FAILURE) Main PID: 874 (code=exited, status=0/SUCCESS) 8月 18 12:15:20 cm nginx[13254]: nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address already in use) 8月 18 12:15:21 cm nginx[13254]: nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address already in use) 8月 18 12:15:21 cm nginx[13254]: nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address already in use) 8月 18 12:15:22 cm nginx[13254]: nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address already in use) 8月 18 12:15:22 cm nginx[13254]: nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address already in use) 8月 18 12:15:23 cm systemd[1]: nginx.service: control process exited, code=exited status=1 8月 18 12:15:23 cm nginx[13254]: nginx: [emerg] still could not bind() 8月 18 12:15:23 cm systemd[1]: Failed to start nginx. 8月 18 12:15:23 cm systemd[1]: Unit nginx.service entered failed state. 8月 18 12:15:23 cm systemd[1]: nginx.service failed. Use the ``-h'' option to get more help information. [root@cm local]# lsof -i:80 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME nginx 8859 nginx 6u IPv4 33972 0t0 TCP *:http (LISTEN) [root@cm local]# kill -9 8859 [root@cm local]# lsof -i:80 [root@cm local]# netstat -natp | grep :80 [root@cm local]# systemctl restart nginx.service
二、"Can't locate CPAN.pm in @INC " 解决方案
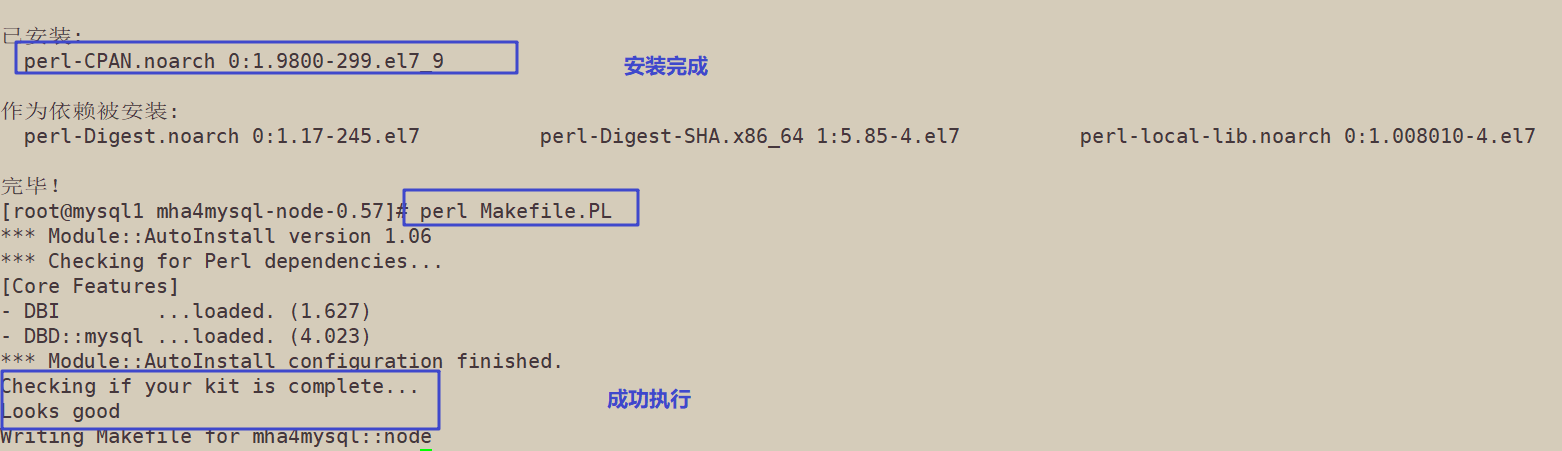
[root@mysql1 mha4mysql-node-0.57]# ls AUTHORS bin COPYING debian inc lib Makefile.PL MANIFEST META.yml README rpm t [root@mysql1 mha4mysql-node-0.57]# perl Makefile.PL *** Module::AutoInstall version 1.06 *** Checking for Perl dependencies... Can't locate CPAN.pm in @INC (@INC contains: inc /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .) at inc/Module/AutoInstall.pm line 304.
【解决方案】
这个问题就是说,没有安装perl-CPAN,解决就很简单了,安装个perl-CPAN:#yum install perl-CPAN
[root@mysql1 mha4mysql-node-0.57]# yum install perl-CPAN 已安装: perl-CPAN.noarch 0:1.9800-299.el7_9 作为依赖被安装: perl-Digest.noarch 0:1.17-245.el7 perl-Digest-SHA.x86_64 1:5.85-4.el7 perl-local-lib.noarch 0:1.008010-4.el7 完毕! [root@mysql1 mha4mysql-node-0.57]# perl Makefile.PL *** Module::AutoInstall version 1.06 *** Checking for Perl dependencies... [Core Features] - DBI ...loaded. (1.627) - DBD::mysql ...loaded. (4.023) *** Module::AutoInstall configuration finished. Checking if your kit is complete... Looks good Writing Makefile for mha4mysql::node
三、[ERROR] unknown variable 'default-character-set=utf8'
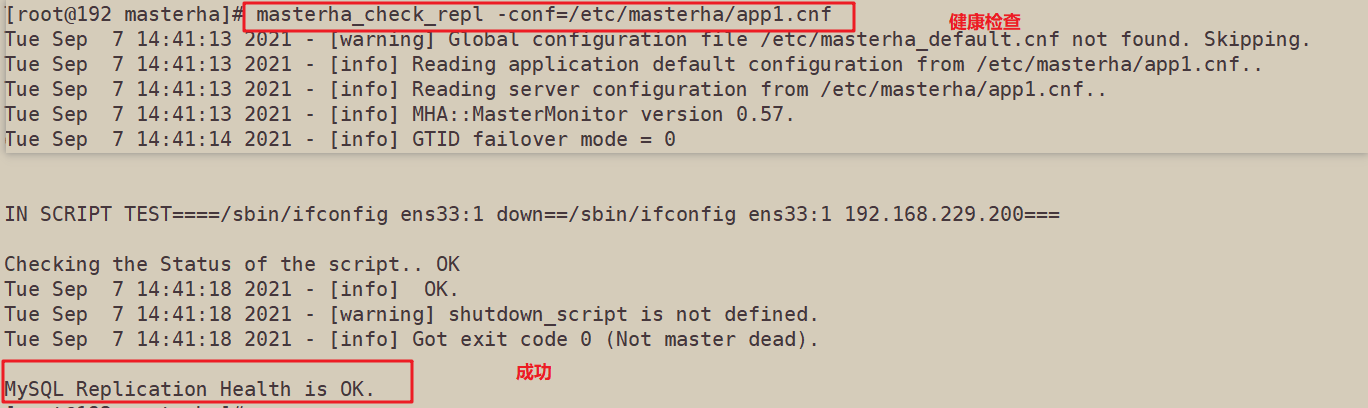
masterha_check_repl -conf=/etc/masterha/app1.cnf 健康检查时报错
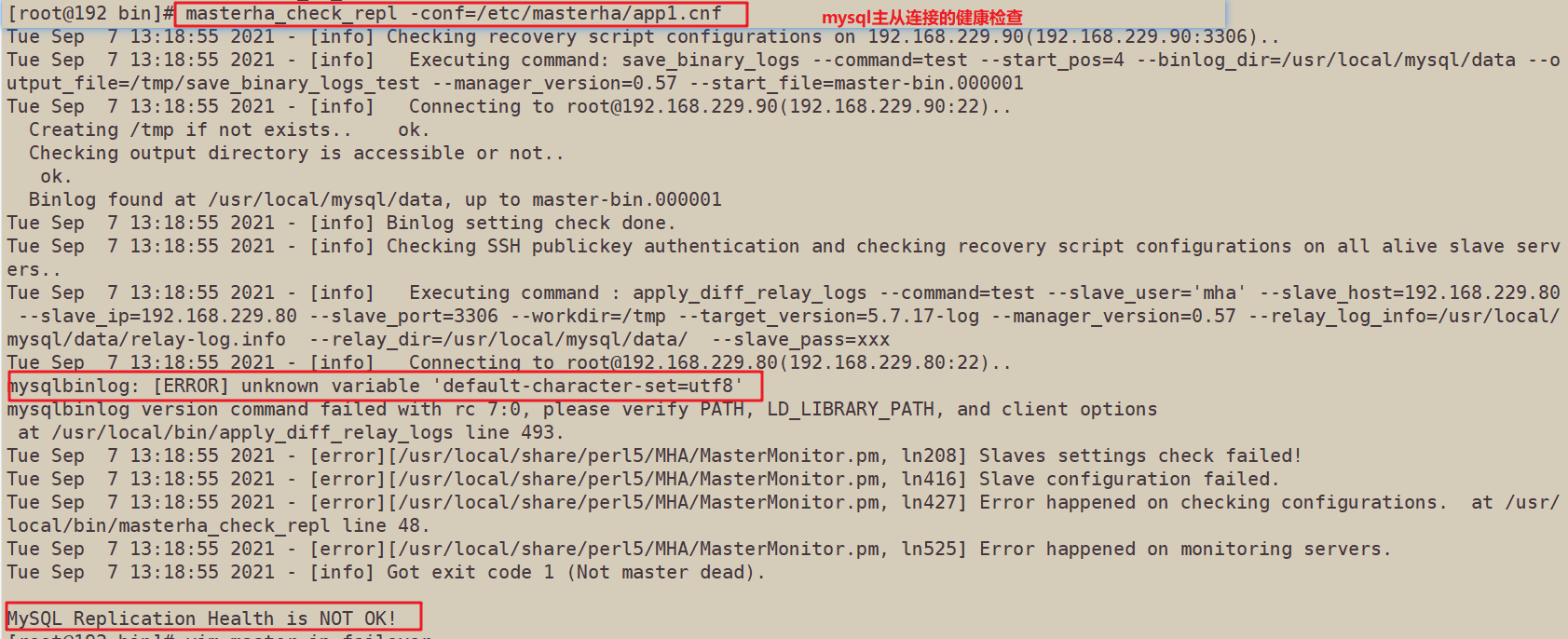
查看日志:发现其中提示:
Tue Sep 7 13:18:55 2021 - [info] Connecting to root@192.168.229.80(192.168.229.80:22)..
mysqlbinlog: [ERROR] unknown variable 'default-character-set=utf8'
default-character-set=utf8这个设置有问题,系统无法识别,将非必要项删除或者注释掉即可
修改192.168.229.80主机的配置文件/etc/my.cnf
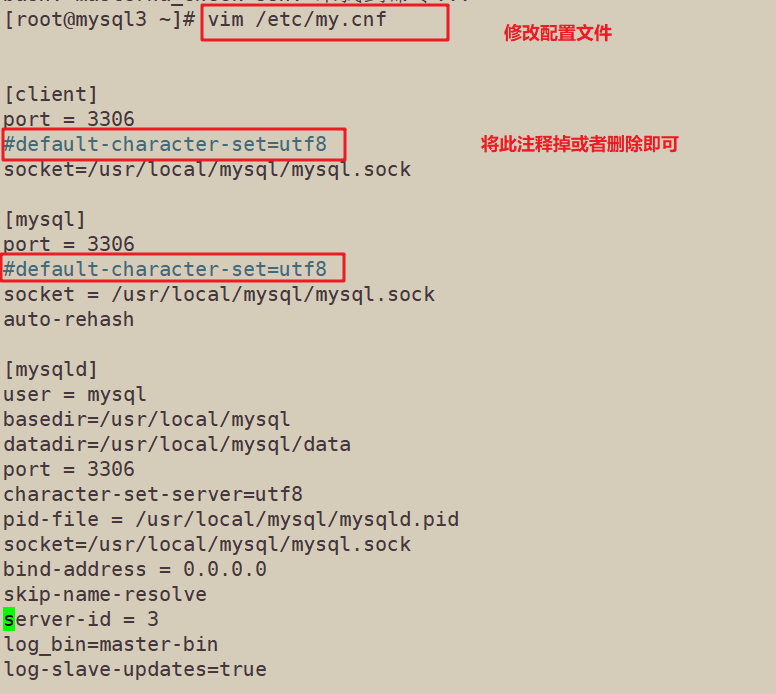
重启mysql服务,再次检查,OK
四、MySQL主从复制,启动slave时报错Slave failed to initialize relay log info structure from the repository
症状:
MySQL主从复制,启动slave时,出现下面报错:
mysql> start slave; ERROR 1872 (HY000): Slave failed to initialize relay log info structure from the repository
解决方法:
在网上搜索
原来是找不到./server246-relay-bin.index文件,找到原因所在了,由于我使用的是冷备份文件恢复的实例,在mysql库中的slave_relay_log_info表中依然保留之前relay_log的信息,所以导致启动slave报错。
mysql提供了工具用来删除记录:reset slave;
slave reset执行候做了这样几件事:
1、删除slave_master_info ,slave_relay_log_info两个表中数据;
2、删除所有relay log文件,并重新创建新的relay log文件;
3、不会改变gtid_executed 或者 gtid_purged的值
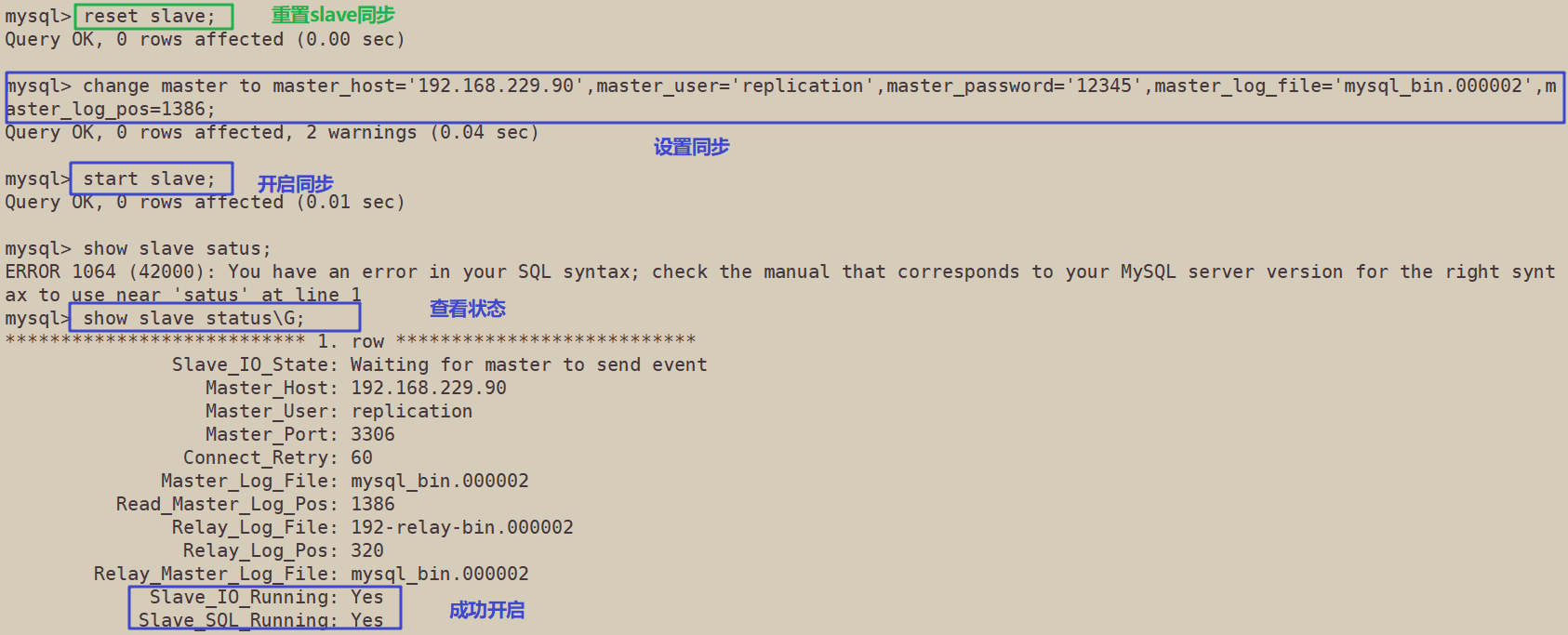
mysql> reset slave;
Query OK, 0 rows affected (0.00 sec)
mysql> change master to master_host='192.168.229.90',master_user='replication',master_password='12345',master_log_file='mysql_bin.000002',maaster_log_pos=1386;
Query OK, 0 rows affected, 2 warnings (0.04 sec)
mysql> start slave;
Query OK, 0 rows affected (0.01 sec)
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.229.90
Master_User: replication
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql_bin.000002
Read_Master_Log_Pos: 1386
Relay_Log_File: 192-relay-bin.000002
Relay_Log_Pos: 320
Relay_Master_Log_File: mysql_bin.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
将本人在工作学习中的一些知识记录并分享

