
shell文本处理三剑客之——awk
一、awk的概述
1、awk的概念
逐行读取文本,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令
sed命令常用于一整行的处理,而awk比较倾向于将一行分成多个“字段”然后再进行处理。awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示
在使用awk命令的过程中,可以使用逻辑操作符“&&”表示“与”、“| |”表示“或”、“!“表示“非”;还可以进行简单的数学运算,如+、-、*、/、%、^分别表示加、减、乘、除、取余和乘方
2、awk的工作原理
awk是逐行处理的,逐行处理的意思就是说,当awk处理一个文本时,会一行一行进行处理,处理完当前行,再处理下一行,awk默认以"换行符"为标记,识别每一行,也就是说,awk跟我们人类一样,每次遇到"回车换行",就认为是当前行的结束,新的一行的开始,awk会按照用户指定的分割符去分割当前行,如果没有指定分割符,默认使用空格作为分隔符。

$0 表示显示整行 ,$NF表示当前行分割后的最后一列($0和$NF均为内置变量)
注意,$NF 和 NF 要表达的意思是不一样的,对于awk来说,$NF表示最后一个字段,NF表示当前行被分隔符切开以后,一共有几个字段
也就是说,假如一行文本被空格分成了7段,那么NF的值就是7,$NF的值就是$7, 而$7表示当前行的第7个字段,也就是最后一列,那么每行的倒数第二列可以写为$(NF-1)
3、基本格式
awk [选项参数] 'script' var=value file(s) 或 awk [选项参数] -f scriptfile var=value file(s)
4、常见的内建变量(可直接用)
FS∶ 列分割符。指定每行文本的字段分隔符,默认为空格或制表位。与"-F"作用相同
NF∶ 当前处理的行的字段个数。
NR∶ 当前处理的行的行号(序数)。
$0∶当前处理的行的整行内容。
$n∶ 当前处理行的第n个字段(第n列)。
FILENAME∶ 被处理的文件名。
RS∶ 行分隔符。awk从文件上读取资料时,将根据RS的定义把资料切割成许多条记录,而awk一次仅读入一条记录,以进行处理。预设值是’\n’
二、awk的应用一:按行输出文本
1、输出全部内容
[root@weq ~]# cat num.txt
1
2
3
4
5
6
7
8
9
10
[root@weq ~]# awk '{print}' num.txt
1
2
3
4
5
6
7
8
9
10
[root@weq ~]# awk '{print $0}' num.txt
1
2
3
4
5
6
7
8
9
10
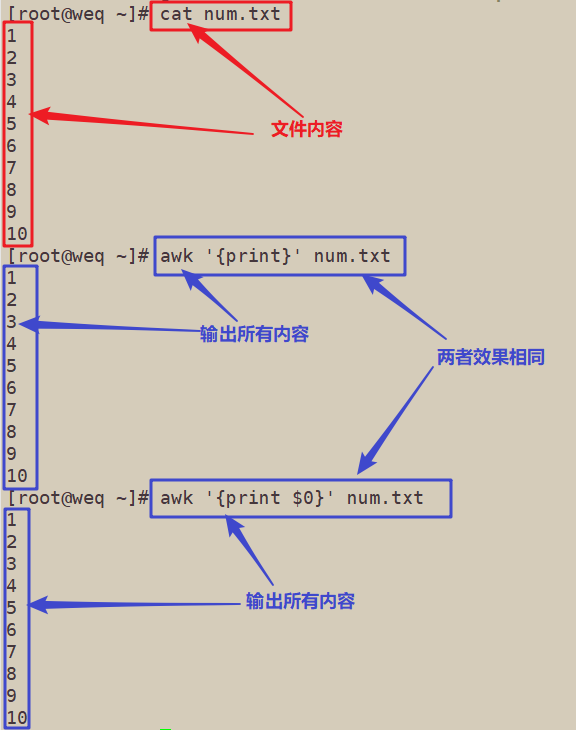
2、输出指定行的内容
[root@weq ~]# cat num.txt
1
2
3
4
5
6
7
8
9
10
[root@weq ~]# awk 'NR==3,NR==5 {print $0}' num.txt
3
4
5
[root@weq ~]# awk '(NR>=3)&&(NR<=5) {print}' num.txt
3
4
5
[root@weq ~]# awk '(NR==3)&&(NR==5) {print}' num.txt
[root@weq ~]# awk '(NR==3)||(NR==5) {print}' num.txt
3
5
[root@weq ~]# awk '(NR<=3)||(NR>=8) {print}' num.txt
1
2
3
8
9
10
[root@weq ~]# awk '(NR==8) {print}' num.txt
8
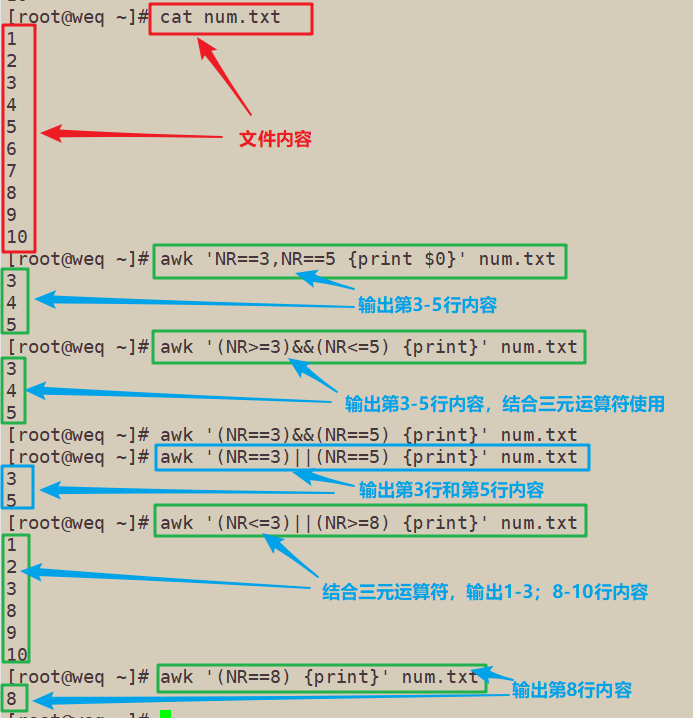
3、输出奇数和偶数行的内容
[root@weq ~]# cat num.txt
1
2
3
4
5
6
7
8
9
10
[root@weq ~]# awk '(NR%2)==1 {print}' num.txt
1
3
5
7
9
[root@weq ~]# awk '(NR%2)==0 {print}' num.txt
2
4
6
8
10

4、输出包含指定字符的行
[root@weq ~]# cat testfile2
c
bd
abbc
cdd
efg
abc
CDD
[root@weq ~]# awk '/^a/{print}' testfile2
abbc
abc
[root@weq ~]# awk '/c$/{print}' testfile2
c
abbc
abc

5、awk包含两种特殊的模式:BEGIN 和 END
5.1 两种模式的概念
BEGIN 模式指定了处理文本之前需要执行的操作:
END 模式指定了处理完所有行之后所需要执行的操作:
BEGIN模式表示,在处理指定的文本之前,需要先执行BEGIN模式中指定的动作; awk再处理指定的文本,之后再执行END模式中指定的动作,END{}语句块中, 往往会放入打印结果等语句
5.2 BEGIN模式的应用实例一
BEGIN 模式指定了处理文本之前需要执行的操作:
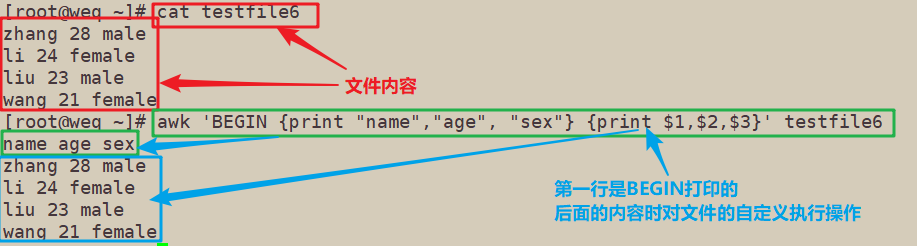
[root@weq ~]# cat testfile6
zhang 28 male
li 24 female
liu 23 male
wang 21 female
[root@weq ~]# awk 'BEGIN {print "name","age", "sex"}' testfile6
name age sex
[root@weq ~]# awk 'BEGIN {print "name","age", "sex"}'
name age sex

5.2 BEGIN模式的应用实例二
如何让:awk先执行BEGIN模式指定的动作,再根据执我们自定义的动作去操作文本
[root@weq ~]# cat testfile6
zhang 28 male
li 24 female
liu 23 male
wang 21 female
[root@weq ~]# awk 'BEGIN {print "name","age", "sex"} {print $1,$2,$3}' testfile6
name age sex
zhang 28 male
li 24 female
liu 23 male
wang 21 female
5.3 END模式的应用实例
END模式就是在处理完所有的指定的文本之后,需要指定的动作
[root@weq ~]# cat testfile6
zhang 28 male
li 24 female
liu 23 male
wang 21 female
[root@weq ~]# awk 'BEGIN {print "name","age", "sex"} {print $1,$2,$3} END{print "lu","18","male"}' testfile6
name age sex
zhang 28 male
li 24 female
liu 23 male
wang 21 female
lu 18 male

返回的结果很像一张"报表",有"表头" 、"表内容"、 "表尾",这就是awk对文本的格式化能力
5.4 BEGIN、END的综合应用实例:统计在文本中匹配到指定字符的次数
[root@weq ~]# cat 123.txt
zs:x:1028:1028::/home/zs:/bin/bash
xx:x:1003:1003::/home/xx:/bin/bash
users.txt:x:1001:1001::/home/users.txt:/bin/bash
usbmuxd:x:113:113:usbmuxd user:/:/sbin/nologin
tss:x:59:59:Account used by the trousers package to sandbox the tcsd daemon:/dev/null:/sbin/nologin
tcpdump:x:72:72::/:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
stu9:x:1015:1015::/home/stu9:/bin/bash
stu8:x:1014:1014::/home/stu8:/bin/bash
stu7:x:1013:1013::/home/stu7:/bin/bash
[root@weq ~]# awk 'BEGIN{x=0};/\/bin\/bash/ {x++};END{print x;}' 123.txt
6
[root@weq ~]# awk 'BEGIN{x=0};/\/bin\/bash/ {x++;print $0;print x};END{print x;}' 123.txt
zs:x:1028:1028::/home/zs:/bin/bash
1
xx:x:1003:1003::/home/xx:/bin/bash
2
users.txt:x:1001:1001::/home/users.txt:/bin/bash
3
stu9:x:1015:1015::/home/stu9:/bin/bash
4
stu8:x:1014:1014::/home/stu8:/bin/bash
5
stu7:x:1013:1013::/home/stu7:/bin/bash
6
6
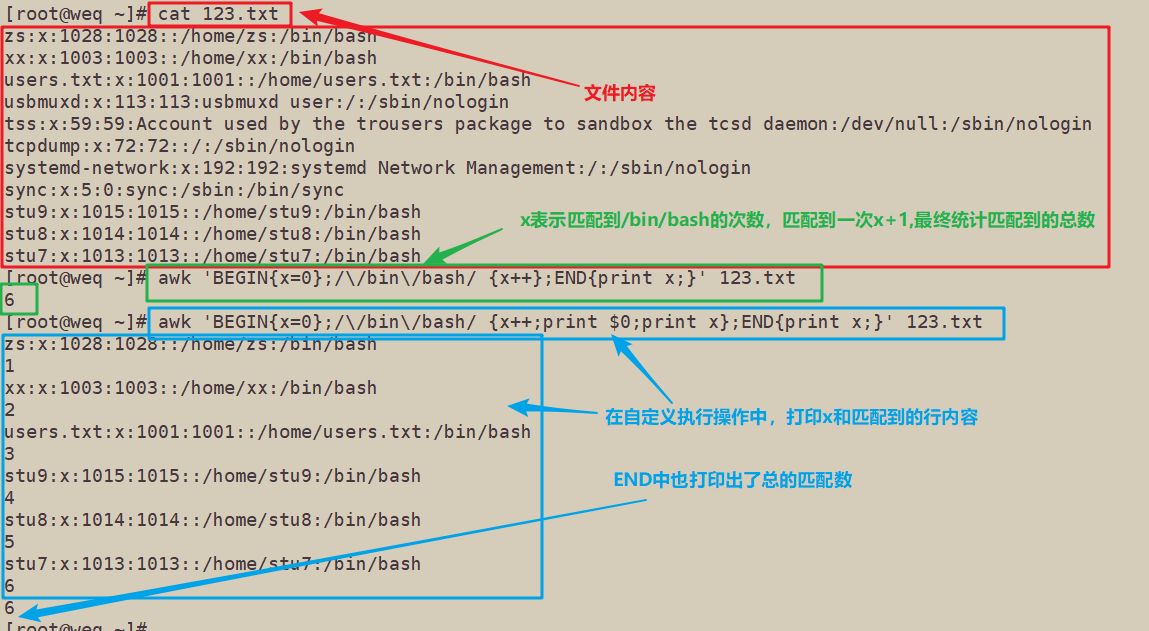
三、awk的应用二:按字段输出文本
awk -F 指定分隔符
FS∶ 列分割符。指定每行文本的字段分隔符,默认为空格或制表位。与"-F"作用相同
1、在指定分隔符下,输出指定的字段内容
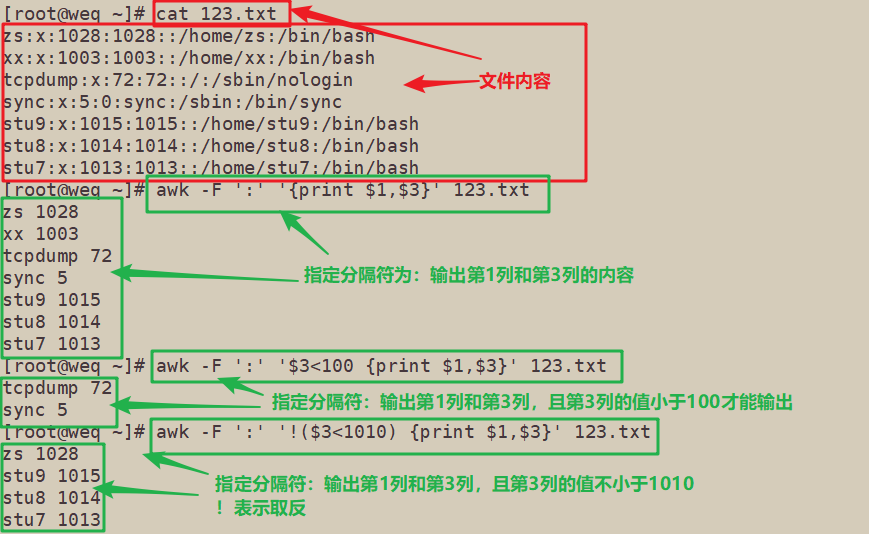
[root@weq ~]# cat 123.txt
zs:x:1028:1028::/home/zs:/bin/bash
xx:x:1003:1003::/home/xx:/bin/bash
tcpdump:x:72:72::/:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
stu9:x:1015:1015::/home/stu9:/bin/bash
stu8:x:1014:1014::/home/stu8:/bin/bash
stu7:x:1013:1013::/home/stu7:/bin/bash
[root@weq ~]# awk -F ':' '{print $1,$3}' 123.txt
zs 1028
xx 1003
tcpdump 72
sync 5
stu9 1015
stu8 1014
stu7 1013
[root@weq ~]# awk -F ':' '$3<100 {print $1,$3}' 123.txt
tcpdump 72
sync 5
[root@weq ~]# awk -F ':' '!($3<1010) {print $1,$3}' 123.txt
zs 1028
stu9 1015
stu8 1014
stu7 1013
2、awk结合if语句,输出指定的字段内容
[root@weq ~]# cat 123.txt
zs:x:1028:1028::/home/zs:/bin/bash
xx:x:1003:1003::/home/xx:/bin/bash
tcpdump:x:72:72::/:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
stu9:x:1015:1015::/home/stu9:/bin/bash
stu8:x:1014:1014::/home/stu8:/bin/bash
stu7:x:1013:1013::/home/stu7:/bin/bash
[root@weq ~]# awk 'BEGIN{FS=":"};{if($3>1010){print $1,$3}}' 123.txt
zs 1028
stu9 1015
stu8 1014
stu7 1013

3、awk结合三元运算符,输出指定字段的内容
三元运算符的概念及语法
三元运算符其实是很方便很好用的一种条件判断方法,这个方法可以使调用或渲染数据时逐级筛选。不仅如此,如果适当的扩展三元运算符的逻辑,这个判断方法还会很好玩,也可以在某种情景下提高代码效率。
(关系表达式) ? 表达式1 : 表达式2;
True : False
int x = 10;
int y = 5;
int z;
如果x大于y 则是true,将x赋值给z;
如果x不大于y 则是false,将y赋值给z;
z = (x > y) ? x : y;
System.out.println("x = " + x);
实例操作格式:
[root@weq ~]# cat 123.txt
zs:x:1028:1028::/home/zs:/bin/bash
xx:x:1003:1003::/home/xx:/bin/bash
tcpdump:x:72:72::/:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
stu9:x:1015:1015::/home/stu9:/bin/bash
stu8:x:1014:1014::/home/stu8:/bin/bash
stu7:x:1013:1013::/home/stu7:/bin/bash
[root@weq ~]# awk -F ':' '{max=($3>=$4)?$3:$4;{print max}}' 123.txt
1028
1003
72
5
1015
1014
1013

4、输出行号以及内容(跟sed输出的行号对比)
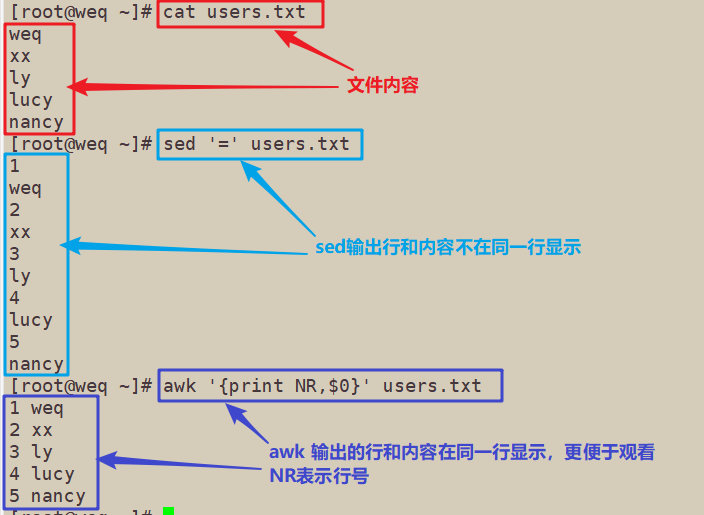
[root@weq ~]# cat users.txt
weq
xx
ly
lucy
nancy
[root@weq ~]# sed '=' users.txt
1
weq
2
xx
3
ly
4
lucy
5
nancy
[root@weq ~]# awk '{print NR,$0}' users.txt
1 weq
2 xx
3 ly
4 lucy
5 nancy
5、在指定分隔符下,输出包含指定内容的字段内容
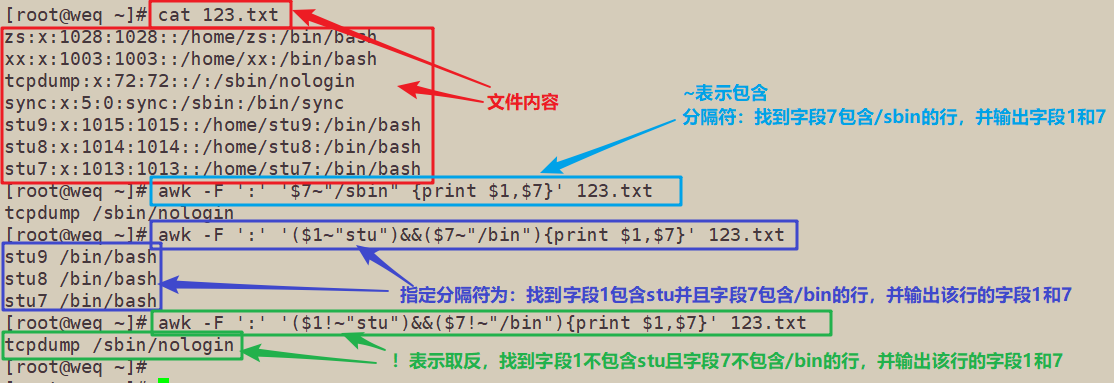
[root@weq ~]# cat 123.txt
zs:x:1028:1028::/home/zs:/bin/bash
xx:x:1003:1003::/home/xx:/bin/bash
tcpdump:x:72:72::/:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
stu9:x:1015:1015::/home/stu9:/bin/bash
stu8:x:1014:1014::/home/stu8:/bin/bash
stu7:x:1013:1013::/home/stu7:/bin/bash
[root@weq ~]# awk -F ':' '$7~"/sbin" {print $1,$7}' 123.txt
tcpdump /sbin/nologin
[root@weq ~]# awk -F ':' '($1~"stu")&&($7~"/bin"){print $1,$7}' 123.txt
stu9 /bin/bash
stu8 /bin/bash
stu7 /bin/bash
[root@weq ~]# awk -F ':' '($1!~"stu")&&($7!~"/bin"){print $1,$7}' 123.txt
tcpdump /sbin/nologin
四、awk的应用三:通过管道、双引号调用shell命令
echo $PATH | awk 'BEGIN{RS=":"};END{print NR}' #统计以冒号分隔的文本段落数,END{}语句块中,往往会放入打印结果等语句
awk -F: '/bash$/{print | "wC -1"}' /etc/passwd #调用wc -1命令统计使用bash 的用户个数,等同于grep -c "bash$" /etc/passwd
free -m | awk '/Mem:/ {print int($3/($3+$4)*100)"%"}' #查看当前 内存使用百分比
top -b -n 1| grep Cpu | awk-F ',' '{print$4}'| awk '{print$1}' #查看当前CPU空闲率,(-b-n 1 表示只需要1次的输出结果)
date -d "$ (awk -F "." '{print $1}' /proc/uptime) second ago" +"%F %H: %M: %S" #显示上次系统重启时间,等同于upt ime; second ago为显示多少秒前的时间,+"%F %H: %M:%S"等同于+"*Y-%m-%d %H:%M:%S"的时间格式
awk 'BEGIN {n=0 ; while ("w" | getline) n++ ; {print n-2}}' #调用w命令,并用来统计在线用户数
awk 'BEGIN {"hostname" | getline ; {print $0}}' #调用hostname, 并输出当前的主机名
1、指定RS: 行分隔符,输出行号和文本;结合wc -l 统计出行数
[root@weq ~]# echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
[root@weq ~]# echo $PATH | awk 'BEGIN{RS=":"};{print NR,$0}'
1 /usr/local/sbin
2 /usr/local/bin
3 /usr/sbin
4 /usr/bin
5 /root/bin
[root@weq ~]# cat 123.txt
zs:x:1028:1028::/home/zs:/bin/bash
xx:x:1003:1003::/home/xx:/bin/bash
tcpdump:x:72:72::/:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
stu9:x:1015:1015::/home/stu9:/bin/bash
stu8:x:1014:1014::/home/stu8:/bin/bash
stu7:x:1013:1013::/home/stu7:/bin/bash
[root@weq ~]# awk -F ':' '/bash$/ {print | "wc -l"}' 123.txt
5
[root@weq ~]# awk -F ':' '/bash$/ {print}' 123.txt
zs:x:1028:1028::/home/zs:/bin/bash
xx:x:1003:1003::/home/xx:/bin/bash
stu9:x:1015:1015::/home/stu9:/bin/bash
stu8:x:1014:1014::/home/stu8:/bin/bash
stu7:x:1013:1013::/home/stu7:/bin/bash
[root@weq ~]# grep -c "bash$" 123.txt
5
awk -F ':' '/bash$/ {print | "wc -l"}' 123.txt 等同于 grep -c "bash$" 123.txt

2、查看内存使用情况,并输出内存使用百分比
[root@weq ~]# free -m
total used free shared buff/cache available
Mem: 1823 250 1106 9 465 1387
Swap: 4095 0 4095
[root@weq ~]# free -m | awk '/Mem:/ {print int($3/$2*100)"%"}'
13%

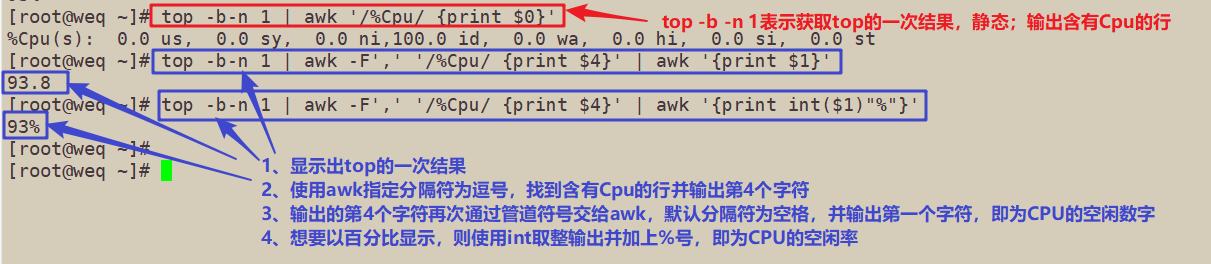
3、查看当前CPU空闲率,(-b-n 1 表示只需要1次的输出结果)
[root@weq ~]# top -b-n 1 | awk '/%Cpu/ {print $0}'
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
[root@weq ~]# top -b-n 1 | awk -F',' '/%Cpu/ {print $4}' | awk '{print $1}'
93.8
[root@weq ~]# top -b-n 1 | awk -F',' '/%Cpu/ {print $4}' | awk '{print int($1)"%"}'
93%
4、显示上次系统重启时间,等同于uptime; second ago为显示多少秒前的时间,+"%F %H: %M:%S"等同于+"*Y-%m-%d %H:%M:%S"的时间格式
4.1 /proc/uptime解析
[root@weq ~]# cat /proc/uptime 204.99 189.78
第一列输出的是,系统启动到现在的时间(以秒为单位),这里简记为num1;
第二列输出的是,系统空闲的时间(以秒为单位),这里简记为num2。
系统的空闲率(%) = num2/(num1*N) 其中N是SMP系统中的CPU个数。
4.2 uptime解析
系统当前时间
系统已经运行了多长时间
目前有多少登陆用户
系统在过去的1分钟 5分钟 15分钟内的平均负载。
你可以使用 w 命令来代替 uptime。w 也提供关于当前系统登录用户和用户所进行工作的相关信息。
[root@weq ~]# uptime 09:11:03 up 2 min, 1 user, load average: 0.02, 0.03, 0.02 [root@weq ~]# cat /proc/uptime 204.99 189.78 [root@weq ~]# w 09:17:55 up 9 min, 1 user, load average: 0.00, 0.01, 0.02 USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT root pts/1 192.168.229.1 09:08 3.00s 0.01s 0.00s w
4.3 实例操作格式
date -d<字符串>:显示字符串所指的日期与时间。字符串前后必须加上双引号;
[root@weq ~]# cat /proc/uptime
731.96 715.63
[root@weq ~]# awk -F '.' '{print $1}' /proc/uptime
813
[root@weq ~]# date -d "$(awk -F '.' '{print $1}' /proc/uptime)second ago" +"%F %H:%M:%S"
2021-07-29 09:08:22
4.4 输出结果

5、调用w命令,并用来统计在线用户数
5.1 getline详解
getline是从流中获取一行信息输入到字符串中:
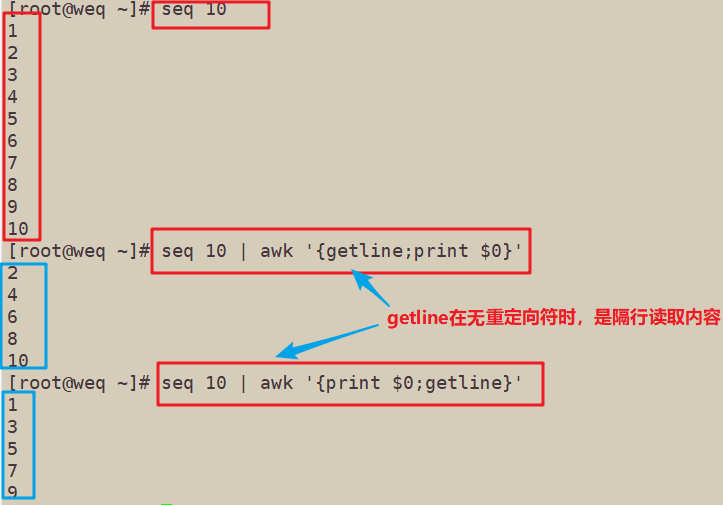
当getline左右无重定向符“<”或“|”时,awk首先读取到了第一行,就是1,然后getline, 就得到了1下面的第二行,就是2,因为getline之后,awk会改变对应的NF, NR,FNR和$0等 内部变量,所以此时的$0的值就不再是1,而是2了,然后将它打印出来。
当getline左右有重定向符“<”或“I”时,getline则作用 于定向输入文件,由于该文件是刚打开,并没有被awk读入一行,只是getline读入那么getline返回的是该文件的第一行, 而不是隔行。
[root@weq ~]# seq 10
1
2
3
4
5
6
7
8
9
10
[root@weq ~]# seq 10 | awk '{getline;print $0}'
2
4
6
8
10
[root@weq ~]# seq 10 | awk '{print $0;getline}'
1
3
5
7
9
回顾:seq的概念
seq(squeue) 是一个序列的缩写,主要用来输出序列化的东西
用法: seq[选项]... 尾数
seq[选项]... 首数 尾数
seq[选项]... 首数 增量 尾数
以指定增量从首数开始打印数字到尾数
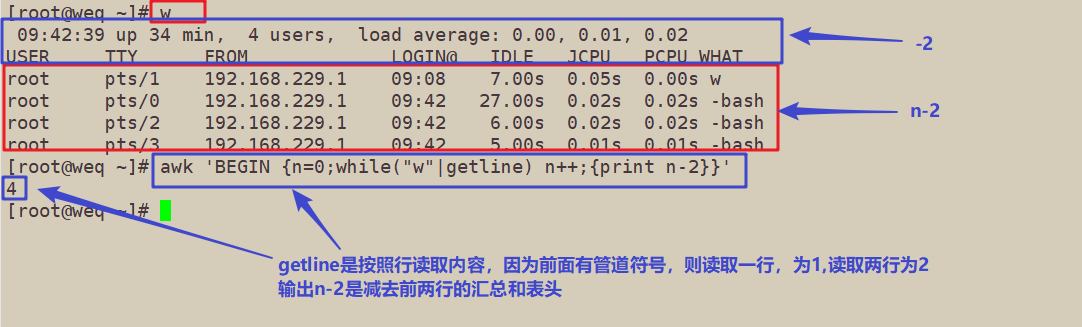
5.2 FNR 与NR的概念
5.3 实例操作格式
[root@weq ~]# w
09:42:39 up 34 min, 4 users, load average: 0.00, 0.01, 0.02
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/1 192.168.229.1 09:08 7.00s 0.05s 0.00s w
root pts/0 192.168.229.1 09:42 27.00s 0.02s 0.02s -bash
root pts/2 192.168.229.1 09:42 6.00s 0.02s 0.02s -bash
root pts/3 192.168.229.1 09:42 5.00s 0.01s 0.01s -bash
[root@weq ~]# awk 'BEGIN {n=0;while("w"|getline) n++;{print n-2}}'
4
5.4 输出结果
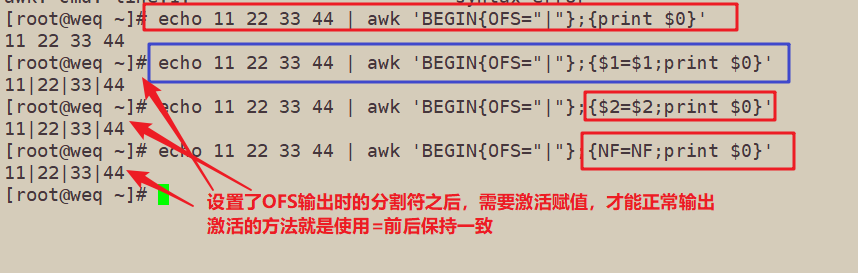
6、OFS详解
OFS表示输出时可设置改变分割符
- $1=$1是用来激活$0的重新赋值,也就是说
- 字段$1…和字段数NF的改变会促使awk重新计算$0的值,通常是在改变OFS后而需要输出$0时这样做
[root@weq ~]# echo 11 22 33 44 | awk 'BEGIN{OFS="|"};{print $0}'
11 22 33 44
[root@weq ~]# echo 11 22 33 44 | awk 'BEGIN{OFS="|"};{$1=$1;print $0}'
11|22|33|44
[root@weq ~]# echo 11 22 33 44 | awk 'BEGIN{OFS="|"};{$2=$2;print $0}'
11|22|33|44
[root@weq ~]# echo 11 22 33 44 | awk 'BEGIN{OFS="|"};{NF=NF;print $0}'
11|22|33|44
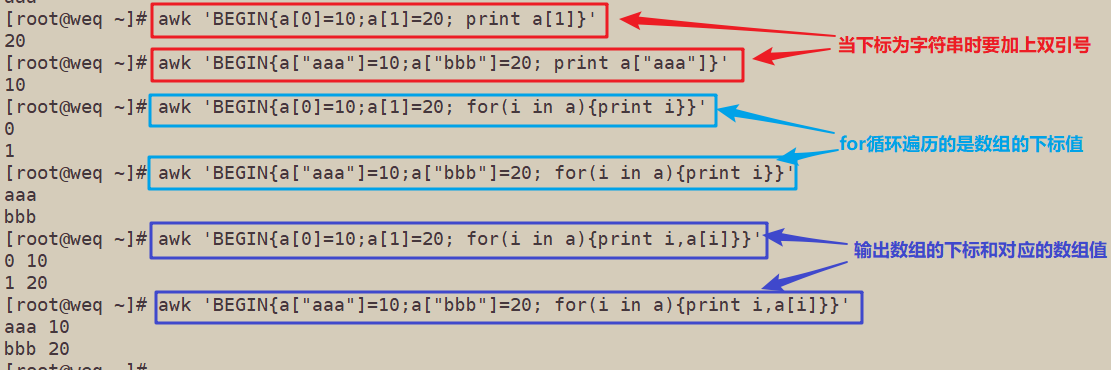
7、使用awk结合for循环遍历创建数组
[root@weq ~]# awk 'BEGIN{a[0]=10;a[1]=20; print a[1]}'
20
[root@weq ~]# awk 'BEGIN{a["aaa"]=10;a["bbb"]=20; print a["aaa"]}'
10
[root@weq ~]# awk 'BEGIN{a[0]=10;a[1]=20; for(i in a){print i}}'
0
1
[root@weq ~]# awk 'BEGIN{a["aaa"]=10;a["bbb"]=20; for(i in a){print i}}'
aaa
bbb
[root@weq ~]# awk 'BEGIN{a[0]=10;a[1]=20; for(i in a){print i,a[i]}}'
0 10
1 20
[root@weq ~]# awk 'BEGIN{a["aaa"]=10;a["bbb"]=20; for(i in a){print i,a[i]}}'
aaa 10
bbb 20
8、使用awk结合for循环以及sort统计重复的次数并排序
[root@weq ~]# cat testfile7
bc
bc
ab
ab
ab
ab
ab
cd
[root@weq ~]# sort testfile7 | uniq -c
5 ab
2 bc
1 cd
[root@weq ~]# awk '{a[$1]++}END{for(i in a){print i,a[i]}}' testfile7 | sort
ab 5
bc 2
cd 1
注意:a[$1]初始为0,a[$1]++后即为1,而这里awk中的a[$1]++的最终值由该文本中内容有多少行决定的,文本逐行读取完毕,再执行END中的命令

 浙公网安备 33010602011771号
浙公网安备 33010602011771号