
shell脚本之——管道命令(sort/uniq/tr/cut/eval命令)
一、sort命令
1、作用
- 以行为单位对文件内容进行排序
- 也可以根据不同的数据类型来排序
2、语法格式
sort [选项] 参数 cat file | sort 选项
3、常用选项
-f∶ 忽略大小写,会将小写字母都转换为大写字母来进行比较;
-b∶ 忽略每行前面的空格;
-n∶ 按照数字进行排序;
-r∶ 反向排序;
-u∶ 等同于uniq,表示相同的数据仅显示一行;
-t∶ 指定字段分隔符,默认使用 【Tab】键分隔;
-k∶指定排序字段;
-o <输出文件>∶ 将排序后的结果转存至指定文件;
4、实例操作
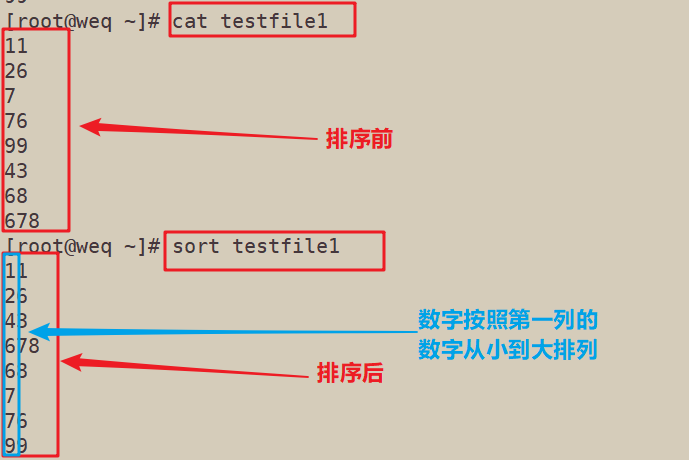
4.1 对数字进行排序:按照第一列数字顺序进行排序,而不是按照数字大小
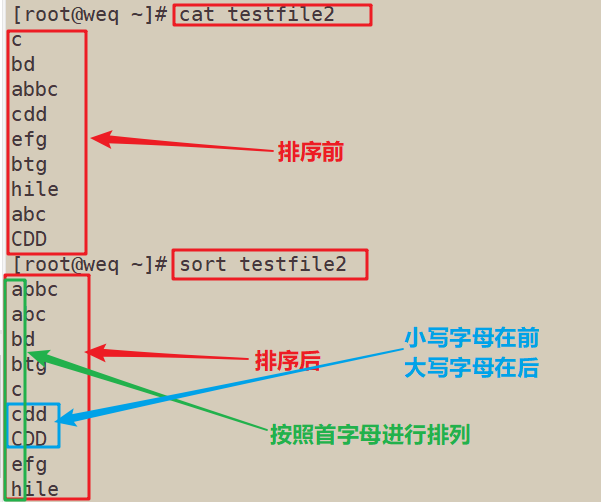
4.2 对字母进行排序:默认是按照首字母进行排序,且小写字母放前面,大写字母放后面
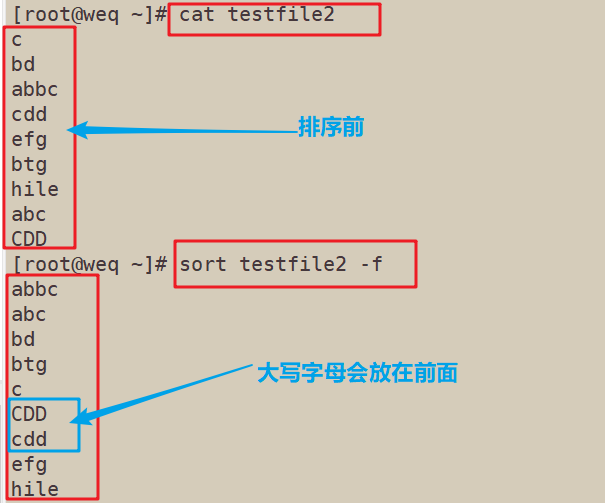
4.3 -f:忽略大小写,会将小写字母都转换为大写字母来进行比较
4.4 sort -n:按照数字进行排序;sort -r:反向排序

4.5 sort -u∶ 等同于uniq,表示相同的数据仅显示一行;去除重复的

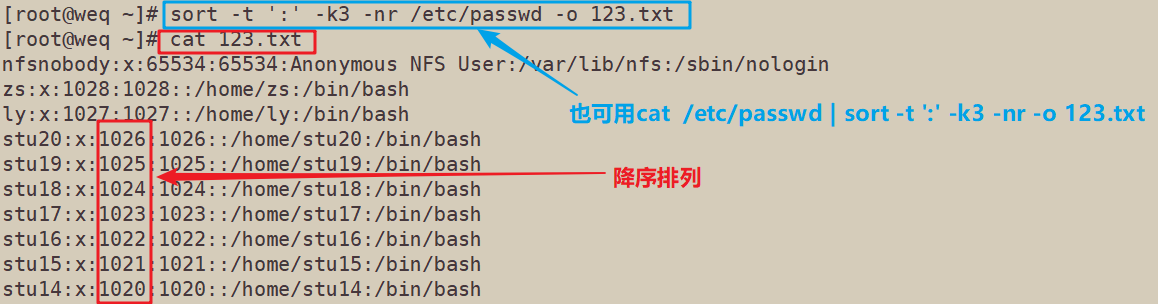
4.6 按照/etc/passwd内的UID进行从大到小反向排序,并将排序结果输出到123.txt文件中
sort -t ':' -k3 -nr /etc/passwd -o 123.txt cat /etc/passwd | sort -t ':' -nr -o 123.txt
-t∶ 指定字段分隔符,默认使用 【Tab】键分隔;-k∶指定排序字段;-o <输出文件>∶ 将排序后的结果转存至指定文件
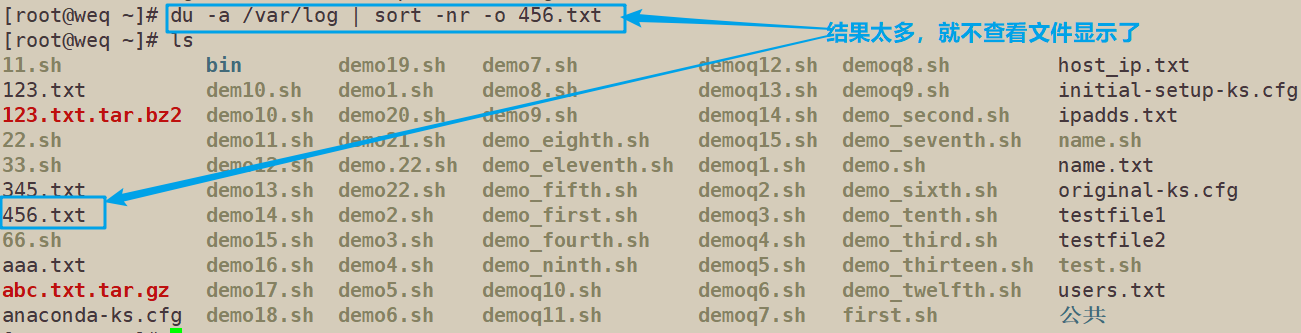
4.7 对/var/log目录下的文件所占磁盘大小进行降序排列,并将排序结果输出到456.txt文件中
du -a /var/log | sort -nr -o 456.txt
二、uniq命令
1、概述
-
uniq 命令用于检查及删除文本文件中重复出现的行列,一般与 sort 命令结合使用
2、语法格式
uniq [选项] 参数 cat file | uniq 选项
3、常用选项
- -c∶ 进行计数,并删除文件中重复出现的行;
- -d∶ 仅显示连续的重复行;
- -u∶ 仅显示出现一次的行;
4、实例操作
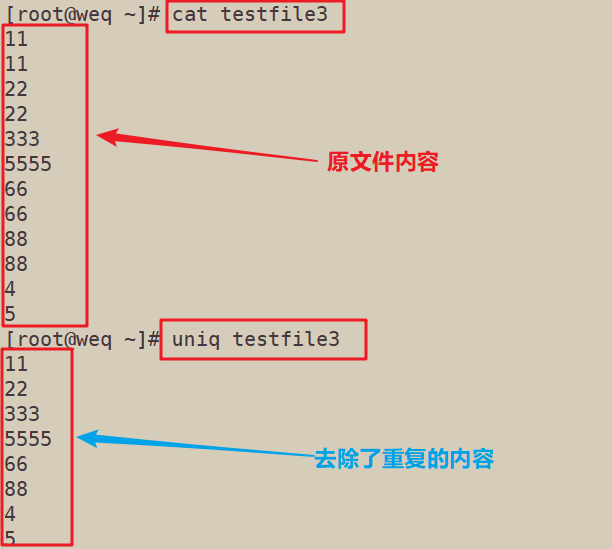
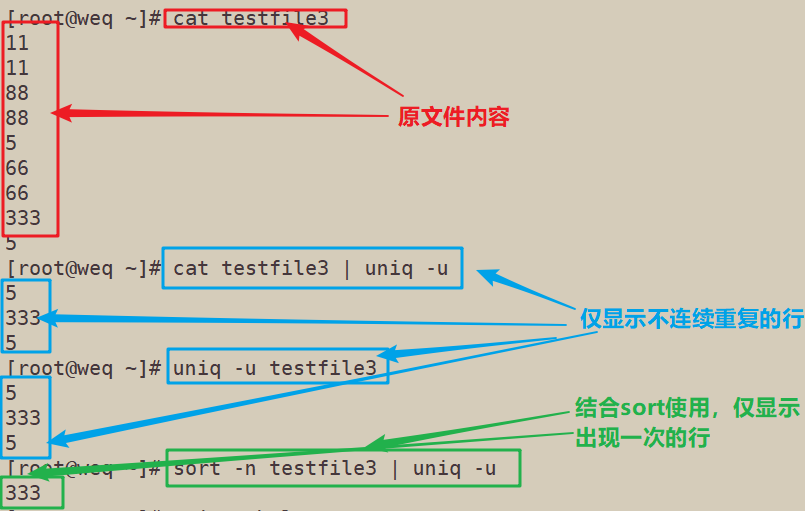
4.1 去除重复内容,uniq+文件名
4.2 uniq 结合sort -n 使用,去除重复项,并进行升序排列
sort -nu testfile3 sort -n testfile3 |uniq

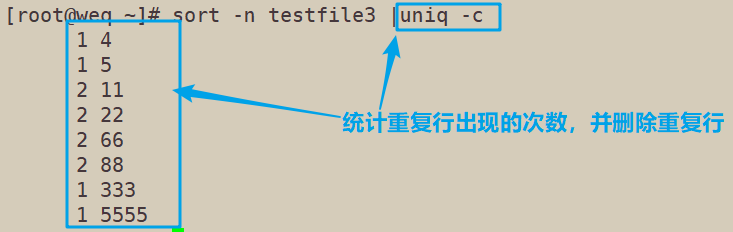
4.3 uniq -c∶ 进行计数,并删除文件中重复出现的行;
sort -n testfile3 |uniq -c
4.4 uniq -c的应用:统计登录失败次数大于3次的IP地址,可以用于检测是否有人爆破密码,可加入定时任务,失败登录大于3次,则进行报警并加入黑名单
grep -i "failed password" /var/log/secure | awk '{print $11}'| uniq -c
也可使用cut进行截取字符串
grep -i "failed password" /var/log/secure | cut -d ' ' -f 11

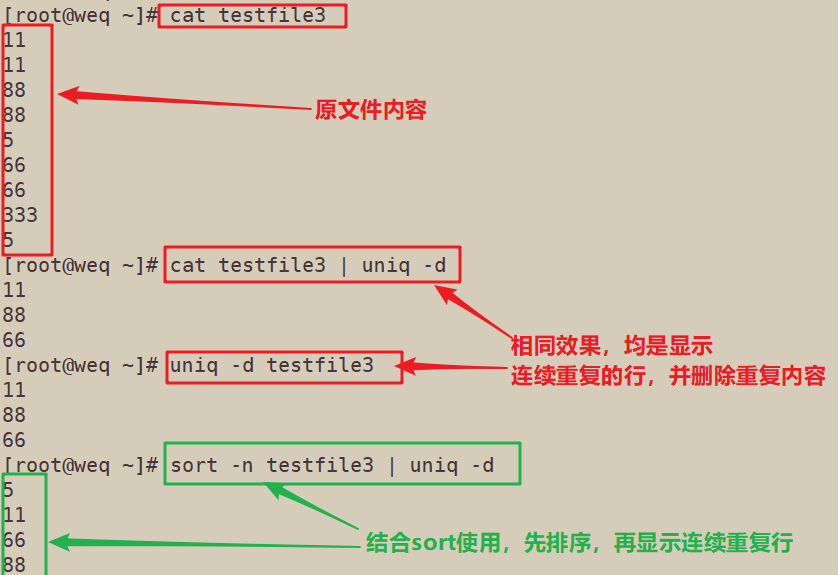
4.5 uniq-d∶ 仅显示连续的重复行;
cat testfile3 | uniq -d uniq -d testfile3 sort -n testfile3 | uniq -d
4.6 sort -u∶ 仅显示出现一次的行
cat testfile3 | uniq -u uniq -u testfile3 sort -n testfile3 | uniq -u
三、tr命令
1、作用
常用来对来自标准输入的字符进行替换、压缩和删除
2、语法格式
tr [选项] 参数
3、常用选项
- -c∶保留字符集1的字符,其他的字符(也包括换行符\n)用字符集2替换
- -d∶ 删除所有属于字符集1的字符
- -s∶ 将重复出现的字符串压缩为一个字符串;用字符集2替换 字符集1
- -t∶ 字符集2 替换 字符集1,不加选项和结果
4、参数
- 字符集1:指定要转换或删除的原字符集,当执行转换操作时,必须使用参数“字符集2”指定转换的目标字符集,但是执行删除操作时,不需要参数“字符集2”;
- 字符集2:指定要转换成的目标字符集
5、实例操作
5.1 替换字符
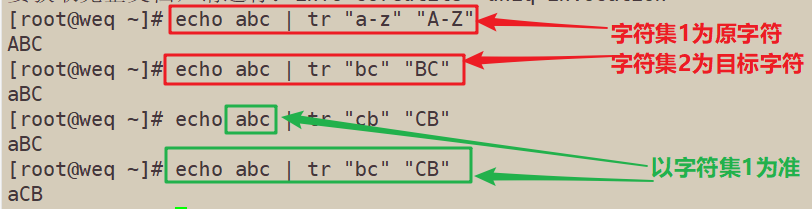
5.2 tr-c∶保留字符集1的字符,其他的字符(也包括换行符\n)用字符集2替换
echo -e "abc\n123" | tr -c "a\n" "d" echo -e "abc\n123" | tr -c "a" "d"

5.3 tr -d∶ 删除所有属于字符集1的字符
echo hi baby | tr -d "hi" echo hiiiiiiiii babyyyyyyyyyyy | tr -d "iy"

5.4 tr -s∶ 将重复出现的字符串压缩为一个字符串;用字符集2替换字符集1
echo hiiiiiiiii babyyyyyyyyyyy | tr -s "iy" echo hiiiiiiiii babyyyyyyyyyyy | tr -s "iy" "0"

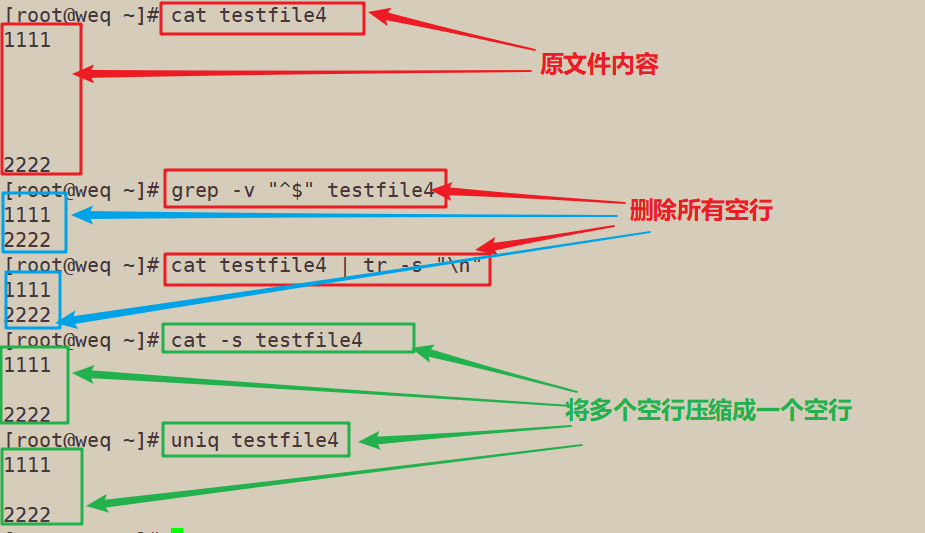
删除空行以及压缩空行(多种方法cat uniq)
grep -v "^$" testfile4 cat testfile4 | tr -s "\n" cat -s testfile4 uniq testfile4
echo -e "11\n\n\n\n\n22"
echo -e "11\n\n\n\n\n22" | tr -s "\n" ":"
n=`echo -e "11\n\n\n\n\n22" | tr -s "\n" ":"`
echo ${n:0:5}
echo ${n%:*}

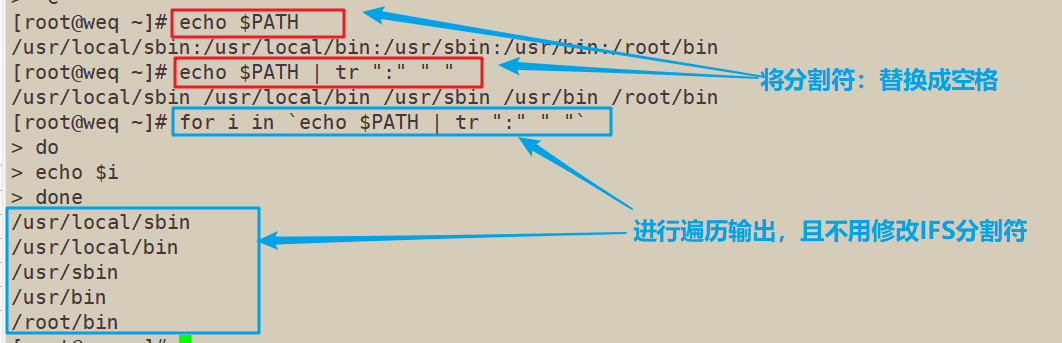
5.5 tr应用一:对PATH变量,替换分割符,并进行遍历输出
[root@weq ~]# echo $PATH /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin [root@weq ~]# echo $PATH | tr ":" " " /usr/local/sbin /usr/local/bin /usr/sbin /usr/bin /root/bin [root@weq ~]# for i in `echo $PATH | tr ":" " "` > do > echo $i > done /usr/local/sbin /usr/local/bin /usr/sbin /usr/bin /root/bin
5.6 tr应用二:解决从windows传来的文件的空格问题
Linux中遇到换行符("\n")会进行回车+换行的操作,回车符反而只会作为控制字符("^M")显示,不发生回车的操作。而windows中要回车符 +换行符("\r\n")才会回车+换行,缺少一个控制符或者顺序不对都不能正确的另起一行
如果文本文件是在windows下创建或文本格式被设置为dos,有时我们会看到一些 ^M符号,其实它就相当于 \r,只是不同的文件格式的转义字符也有所不同。
cat -v 可以让隐藏的转移字符也打印中显示
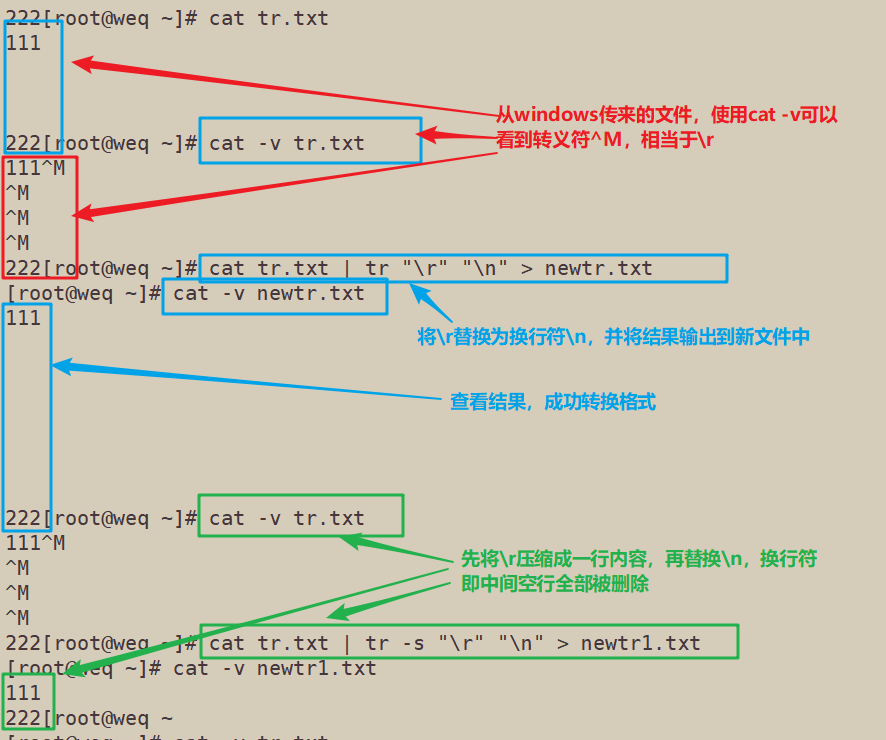
5.6.1 使用tr替换换行符
[root@weq ~]# cat tr.txt 111 222[root@weq ~]# cat -v tr.txt 111^M ^M ^M ^M 222[root@weq ~]# cat tr.txt | tr "\r" "\n" > newtr.txt [root@weq ~]# cat -v newtr.txt 111 222[root@weq ~]# cat -v tr.txt 111^M ^M ^M ^M 222[root@weq ~]# cat tr.txt | tr -s "\r" "\n" > newtr1.txt [root@weq ~]# cat -v newtr1.txt 111 222
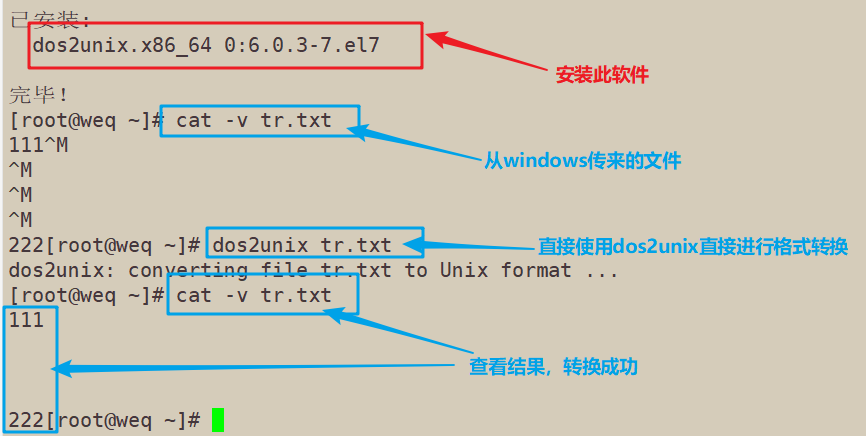
5.6.2 使用 dos2unix +文件名,进行直接转换格式
已安装: dos2unix.x86_64 0:6.0.3-7.el7 完毕! [root@weq ~]# cat -v tr.txt 111^M ^M ^M ^M 222[root@weq ~]# dos2unix tr.txt dos2unix: converting file tr.txt to Unix format ... [root@weq ~]# cat -v tr.txt 111 222
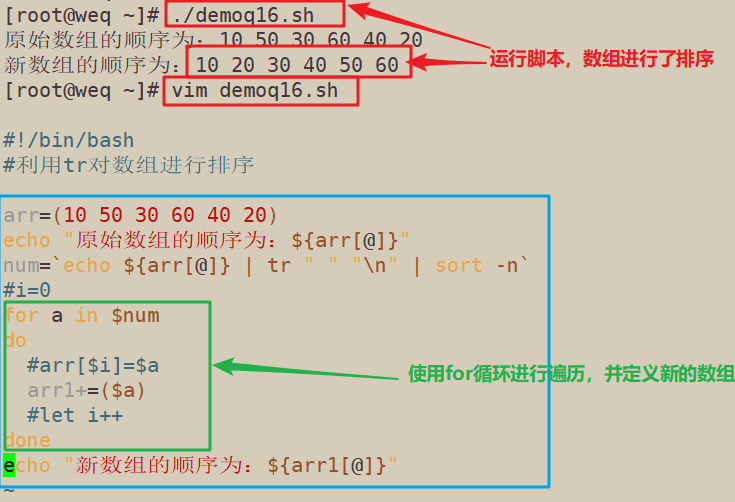
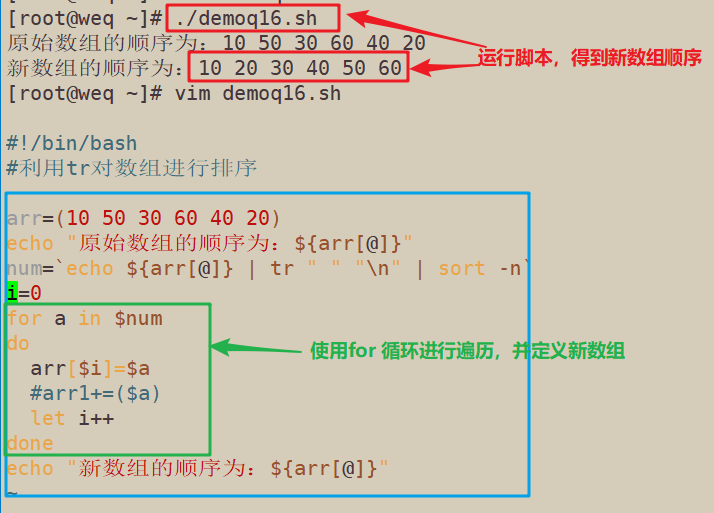
5.6.3 使用tr对数组进行排序
[root@weq ~]# arr=(10 50 30 60 40 20)
[root@weq ~]# echo ${arr[@]}
10 50 30 60 40 20
[root@weq ~]# echo ${arr[@]} | tr " " "\n" | sort -n
10
20
30
40
50
60
[root@weq ~]# arr1=(`echo ${arr[@]} | tr " " "\n" | sort -n | tr "\n" " "`)
[root@weq ~]# echo ${arr1[@]}
10 20 30 40 50 60

#!/bin/bash
#利用tr对数组进行排序
arr=(10 50 30 60 40 20)
echo "原始数组的顺序为:${arr[@]}"
num=`echo ${arr[@]} | tr " " "\n" | sort -n`
#i=0
for a in $num
do
#arr[$i]=$a
arr1+=($a)
#let i++
done
echo "新数组的顺序为:${arr1[@]}"
四、cut命令
1、作用
显示行中的指定部分,删除文件中指定字段
-
cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。
-
如果不指定 File 参数,cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一。
2、格式
cut [选项] 参数
3、常用选项
- -f∶ 通过指定哪一个字段进行提取。cut命令使用"TAB"作为默认的字段分隔符。
- -d∶ “TAB"是默认的分隔符,使用此选项可以更改为其他的分隔符。
- - -complement∶ 此选项用于排除所指定的字段。
- - -output-delimiter∶ 更改输出内容的分隔符。
- -b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志
4、实例操作
4.1 -d∶ “TAB"是默认的分隔符,使用此选项可以更改为其他的分隔符;-f∶ 通过指定哪一个字段进行提取
[root@weq ~]# echo $PATH /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin [root@weq ~]# echo $PATH |cut -d ":" -f 1 /usr/local/sbin [root@weq ~]# cut -d ":" -f 1 /etc/shadow root bin daemon adm lp

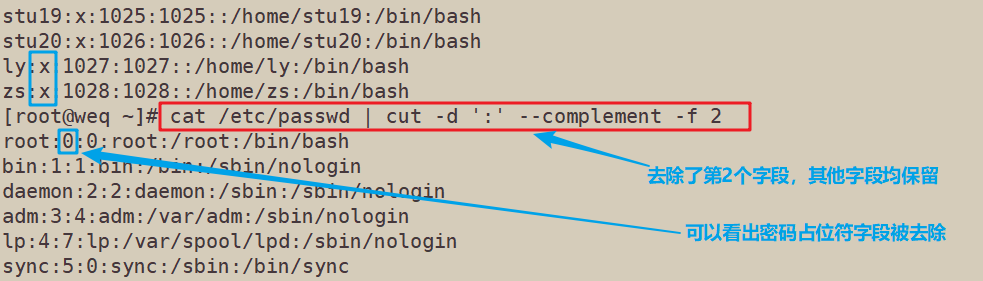
4.2 - -complement∶ 此选项用于排除所指定的字段
cat /etc/passwd | cut -d ':' --complement -f 2
4.3 - -output-delimiter∶ 更改输出内容的分隔符
[root@weq ~]# echo $PATH /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin [root@weq ~]# echo $PATH | cut -d ':' -f 1-4 --output-delimiter=' ' /usr/local/sbin /usr/local/bin /usr/sbin /usr/bin [root@weq ~]# echo $PATH | tr ":" " " /usr/local/sbin /usr/local/bin /usr/sbin /usr/bin /root/bin

5、cut命令主要是接受三个定位方法:
- 第一,字节(bytes),用选项-b
- 第二,字符(characters),用选项-c
- 第三,域(fields),用选项-f
参数说明: 必须指定分割单位,即参数b、c、f 必须三选一
5.1 参数-f-b和-c的比较
[root@weq ~]# who root pts/0 2021-07-26 08:49 (192.168.229.1) root pts/1 2021-07-26 09:02 (192.168.229.1) [root@weq ~]# who | cut -f 1 root pts/0 2021-07-26 08:49 (192.168.229.1) root pts/1 2021-07-26 09:02 (192.168.229.1) [root@weq ~]# who | cut -d ' ' -f 1 root root [root@weq ~]# who |cut -b 4 t t [root@weq ~]# who |cut -b 4,5,6 t t [root@weq ~]# who |cut -b 4-10 t p t p [root@weq ~]# who |cut -c 4-10 t p t p

5.2 参数-b和-c的区别
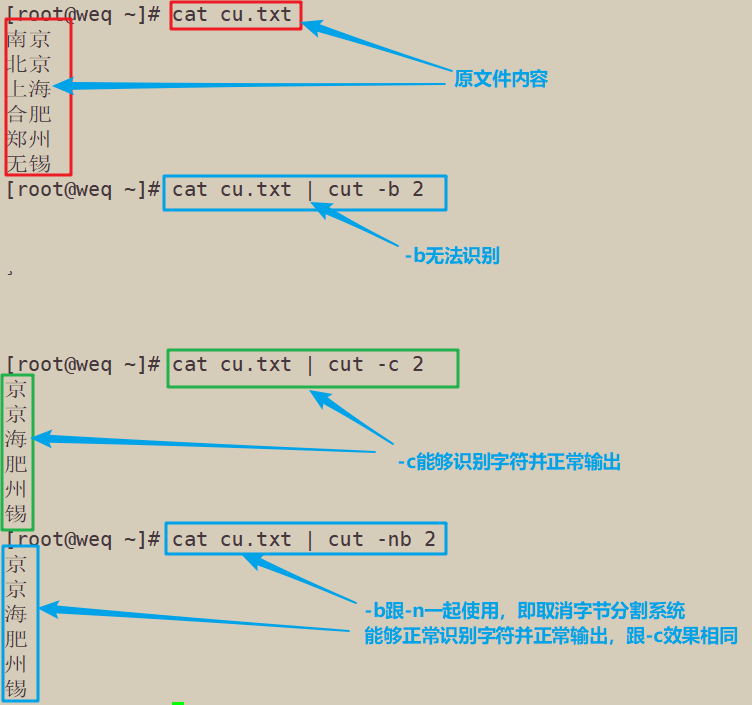
-c则会以字符为单位,输出正常;而-b只会以字节(8位二进制位)来计算,输出就是乱码
-n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的
范围之内,该字符将被写出;否则,该字符将被排除。
[root@weq ~]# cat cu.txt 南京 北京 上海 合肥 郑州 无锡 [root@weq ~]# cat cu.txt | cut -b 2 ¸ [root@weq ~]# cat cu.txt | cut -c 2 京 京 海 肥 州 锡 [root@weq ~]# cat cu.txt | cut -nb 2 京 京 海 肥 州 锡
五、截取字符串的四种方法
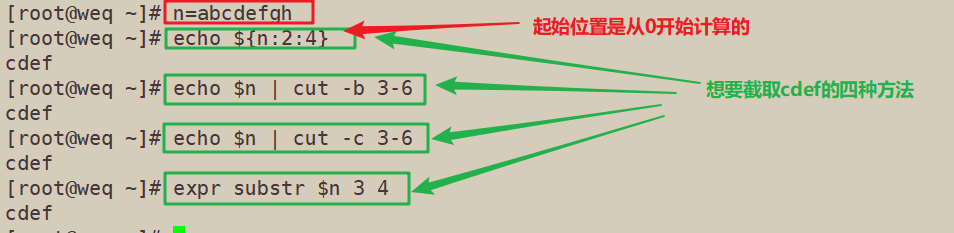
方法一:expr substr $字符串 起始位置 截取长度 (起始位置从1开始)
方法二:echo ${字符串:起始位置:截取长度} (起始位置从0开始)
方法三:echo $字符串 | cut -b 起始位置—结束位置 (起始位置从1开始)
方法四:echo $字符串 | cut -c 起始位置—结束位置 (起始位置从1开始)
[root@weq ~]# n=abcdefgh
[root@weq ~]# echo ${n:2:4}
cdef
[root@weq ~]# echo $n | cut -b 3-6
cdef
[root@weq ~]# echo $n | cut -c 3-6
cdef
[root@weq ~]# expr substr $n 3 4
cdef
六、eval命令
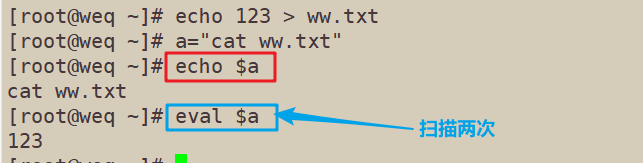
命令加上eval时,shell会执行命令之前扫描两次。eval命令将首先会先扫描命令行进行所有命令适用于那些一次扫描无法实现其功能的变量。该命令对变量进行两次扫描。
1、实例操作一
[root@weq ~]# echo 123 > ww.txt [root@weq ~]# a="cat ww.txt" [root@weq ~]# echo $a cat ww.txt [root@weq ~]# eval $a 123
2、实例操作二
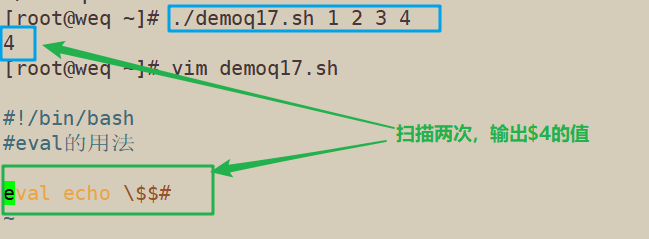
[root@weq ~]# ./demoq17.sh 1 2 3 4 4 [root@weq ~]# vim demoq17.sh #!/bin/bash #eval的用法 eval echo \$$#

 浙公网安备 33010602011771号
浙公网安备 33010602011771号